
S3 Writer
This task is used to write the data in Amazon S3 bucket.
Please follow the below mentioned steps to configure the meta information of S3 writer:
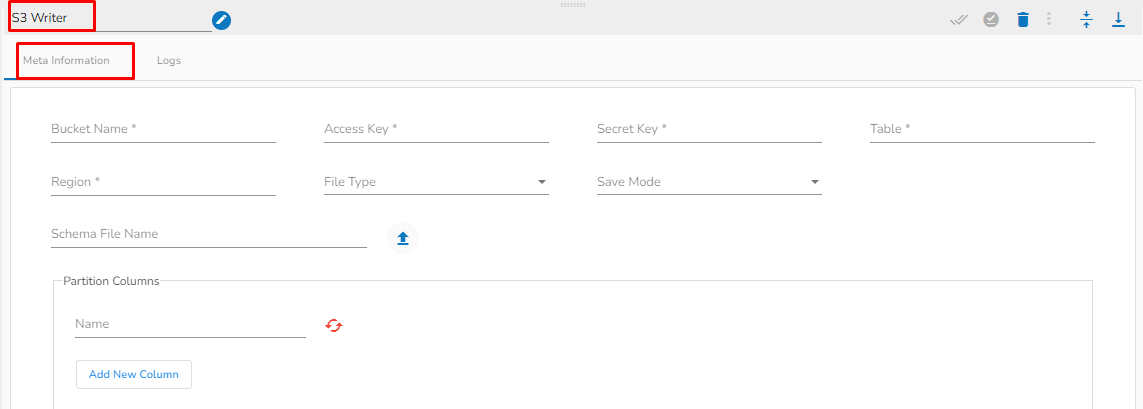
Bucket Name (*): Enter S3 Bucket name.
Region (*): Provide S3 region.
Access Key (*): Access key shared by AWS to login
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which is to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO are the supported file types).
Save Mode: Select the Save mode from the drop down.
Append
Schema File Name: Upload spark schema file in JSON format.