
S3 Writer
An S3 Writer is designed to write data to an S3 bucket in AWS. S3 readers typically authenticate with S3 using AWS credentials, such as an access key ID and secret access key, to gain access to the S3 bucket and its contents.
All component configurations are classified broadly into the following sections:
Meta Information
Check out the steps given in the demonstration to configure the S3 Writer component.
Configuring the Meta Information tab of the S3 Writer
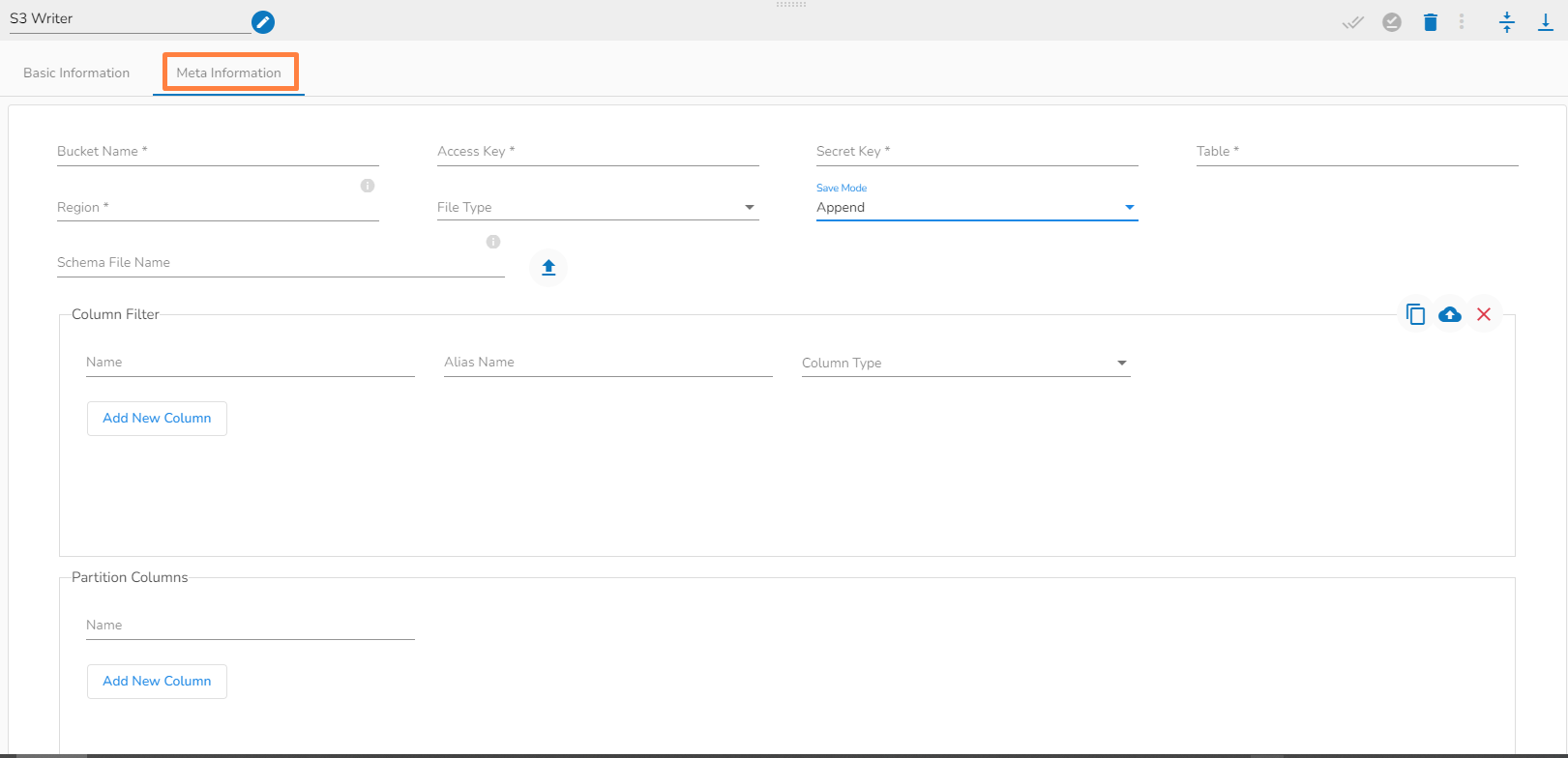
Bucket Name (*): Enter S3 Bucket name.
Access Key (*): Access key shared by AWS to login.
Secret Key (*): Secret key shared by AWS to login.
Table (*): Mention the Table or object name which is to be read.
Region (*): Provide S3 region.
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO are the supported file types).
Save Mode: Select the Save mode from the drop down.
Schema File Name: Upload spark schema file in JSON format.
Column Filter: There is also a section for the selected columns in the Meta Information tab if the user can select some specific columns from the table to read data instead of selecting a complete table so this can be achieved by using the Column Filter section. Select the columns which you want to read and if you want to change the name of the column, then put that name in the alias name section otherwise keep the alias name the same as of column name and then select a Column Type from the drop-down menu.
Use Download Data and Upload File options to select the desired columns.
Upload File: The user can upload the existing system files (CSV, JSON) using the Upload File icon (file size must be less than 2 MB).
Download Data: Users can download the schema structure in JSON format by using the Download Data icon.
Partition Columns: Partition columns are used to organize data in a table based on specific column values. You provide a unique key column name on which the data should be partitioned. When a partition column is used, the data is typically stored in directories or subdirectories within a given Amazon S3 data storage location based on the values of the partition column. Each unique value of the partition column creates a separate directory, and the data corresponding to that partition value is stored in that directory on Amazon S3. This allows for efficient data organization and retrieval when querying the table. For example, If data is partitioned by a date column, a separate folder will be created for each unique date value in an Amazon S3 bucket. The data storage might look like this:
The Meta Information fields may vary based on the selected File Type.
All the possibilities are mentioned below:
CSV: ‘Header’ and ‘Infer Schema’ fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: ‘Multiline’ and ‘Charset’ fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the ‘Deflate’ and ‘Snappy’ options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
Last updated