
HDFS Writer
HDFS stands for Hadoop Distributed File System. It is a distributed file system designed to store and manage large data sets in a reliable, fault-tolerant, and scalable way. HDFS is a core component of the Apache Hadoop ecosystem and is used by many big data applications.
This task writes the data in HDFS(Hadoop Distributed File System).
Please follow the below steps to configure the meta information of HDFS Writer:
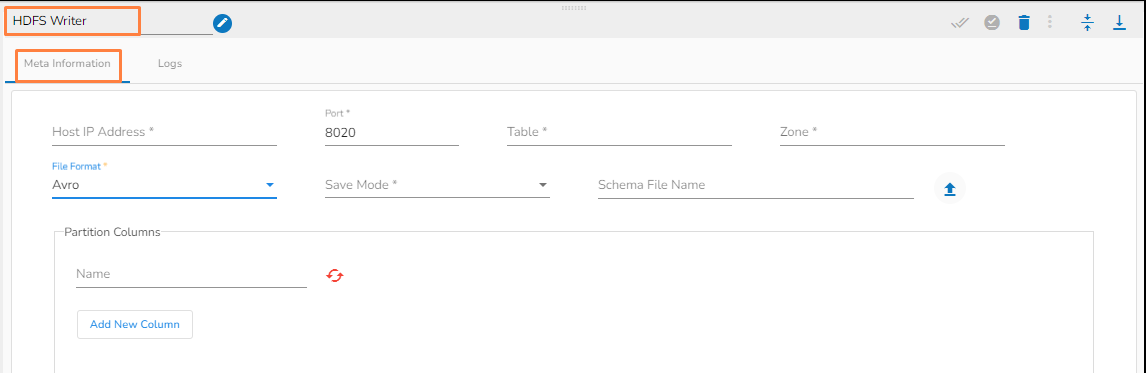
Host IP Address: Enter the host IP address for HDFS.
Port: Enter the Port.
Table: Enter the table name where the data has to be written.
Zone: Enter the Zone for HDFS in which the data has to be written. Zone is a special directory whose contents will be transparently encrypted upon write and transparently decrypted upon read.
File Format: Select the file format in which the data has to be written:
CSV
JSON
PARQUET
AVRO
Save Mode: Select the save mode.
Schema file name: Upload spark schema file in JSON format.
Partition Columns: Provide a unique Key column name to partition data in Spark.