
ES Writer
Elasticsearch is an open-source search and analytics engine built on top of the Apache Lucene library. It is designed to help users store, search, and analyze large volumes of data in real-time. Elasticsearch is a distributed, scalable system that can be used to index and search structured, semi-structured, and unstructured data.
This task is used to write the data in Elastic Search engine.
Please follow the below given steps to configure the meta information of ES Writer:
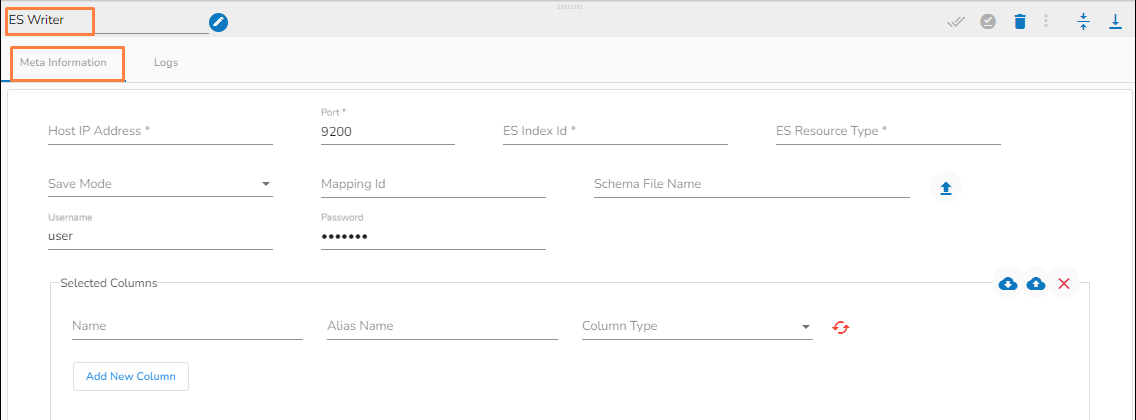
Host IP Address: Enter the host IP Address for Elastic Search.
Port: Enter the port to connect with Elastic Search.
Index ID: Enter the Index ID to read a document in elastic search. In Elasticsearch, an index is a collection of documents that share similar characteristics, and each document within an index has a unique identifier known as the index ID. The index ID is a unique string that is automatically generated by Elasticsearch and is used to identify and retrieve a specific document from the index.
Mapping ID: Provide the Mapping ID. In Elasticsearch, a mapping ID is a unique identifier for a mapping definition that defines the schema of the documents in an index. It is used to differentiate between different types of data within an index and to control how Elasticsearch indexes and searches data.
Resource Type: Provide the resource type. In Elasticsearch, a resource type is a way to group related documents together within an index. Resource types are defined at the time of index creation, and they provide a way to logically separate different types of documents that may be stored within the same index.
Username: Enter the username for elastic search.
Password: Enter the password for elastic search.
Schema File Name: Upload spark schema file in JSON format.
Save Mode: Select the Save mode from the drop down.
Append
Selected columns: The user can select the specific column, provide some alias name and select the desired data type of that column.