# Settings
This page is for the ***Advanced configuration*** of the Data Pipeline. The following list of the configurations get displayed on the ***Settings*** Page:
* Logger
* Default Configuration
* System Pod Status
* Data Sync
* Job BaseInfo
## Logger
This gives the info and config details of the Kafka topic that is set for logging.
Logger Configuration
## Default Configuration
This is for setting the **Default component configuration** for Low, Medium and, High configuration Pipelines.
{% embed url="" %}
Default Configuration
{% endembed %}
{% hint style="info" %} Please Note: *The **Non-Spark** means **Docker** under the **Default Configuration** section.*
{% endhint %}
## System Pod Status
The ***System*** ***Pod Status*** page under the ***Settings*** option gives us monitoring capability on the health of the System Components.
{% embed url="" %}
System Pod Status
{% endembed %}
{% hint style="info" %}
*Please Note:* *The system components should be up for proper functionality of the Pipeline module.*
{% endhint %}
## Data Sync
Data Sync in Settings is given to globally configure the ***Data Sync*** feature. This way the user can enable a DB connection and use the same connection in the pipeline workflow without using any extra resources.
DB Sync page under the Pipeline Settings option
* Go to the ***Settings*** page.
* Click the ***Data Sync*** option.
* The ***Data Sync*** page opens.
* Click the ***Plus*** icon.
{% hint style="info" %} Please Note: *We support seven(7) drivers at present.*
* MongoDB
* Postgres
* MySQL
* MSSQL
* Oracle
* ClickHouse
* Snowflake
{% endhint %}
* The ***New Settings*** dialog box appears.
* Specify all the required connection details
* Click the ***Save*** option.
{% hint style="warning" %}
ClickHouse Port: If you are using Clickhouse as Driver ; Please use TCP Port.
{% endhint %}
{% hint style="info" %}
*Please Note: The **configured Driver** from the **Settings** page provided for DB Sync **can be accessed inside a*** [***DB Sync component on the Pipeline Editor page***](https://docs.bdb.ai/data-pipeline-2/getting-started/homepage/create/creating-a-new-pipeline/connecting-components/events-kafka-and-data-sync) *while using it in a Pipeline.*
{% endhint %}
* A notification message appears.
* Enable the action button.
### Edit Connection String
* Go to the ***Settings*** page.
* Click the ***Data Sync***** option** - the DB Sync Settings page opens.
* Click the ***Edit*** icon.
* The ***Edit Settings*** dialog box opens.
* Edit the connection string if required.
* Click the ***Update*** option.
.png)
### Disconnect Connection String
* Go to the ***Settings*** page.
* Click the ***Data Sync*** option.
* The ***Data Sync Settings*** page opens.
* Click on the Disconnect button to disconnect.
* The Disconnect Setting confirmation dialog box appears.
* Click the ***DISCONNECT*** option.
* A success notification message appears on the top when DB Sync gets disconnected.
### Data Sync in a Pipeline
* All the Pipelines containing the DB Sync Event component get listed under the Pipeline using DB Sync section.
* The user can see the following information:
* **Name**: Name of the pipeline where Data Sync is used.
* **Running status**: This indicates if the pipeline is active or deactivated.
* **Actions:** The user will be able to view the pipeline where Data Sync is used.
## Job BaseInfo
There are two types of Jobs used in Pipeline module:
* Spark Job
* PySpark Job
These two types of are configured in the Job BaseInfo page under the settings menu.
{% hint style="info" %}
***Please Note:*** **The Job BaseInfo has been created from the admin side, and the user is not supposed to create it in the settings menu**.
{% endhint %}
**Steps to create new Job BaseInfo:**
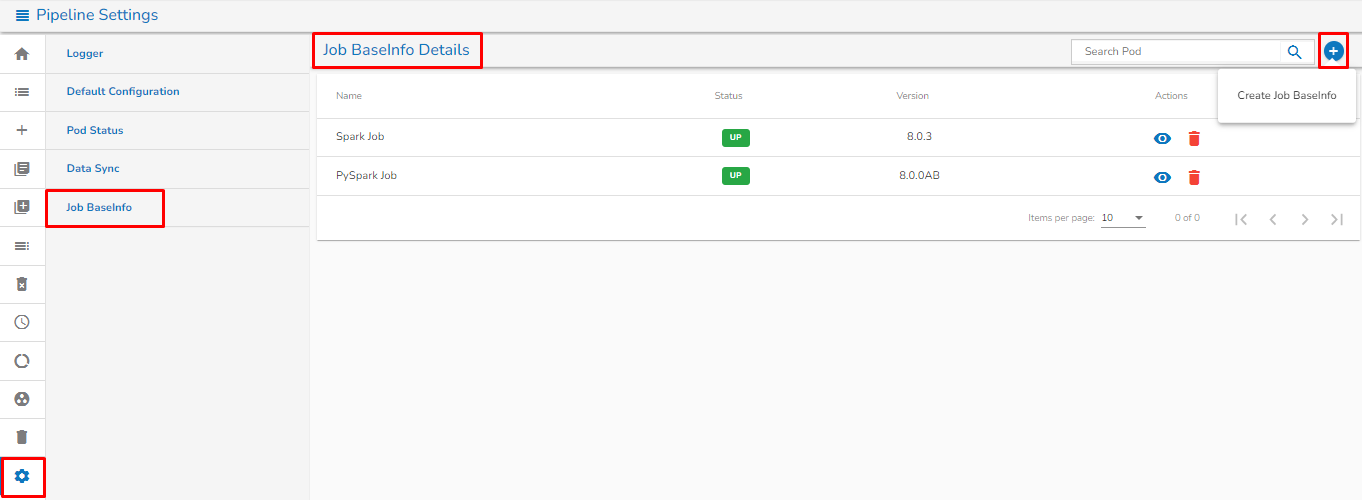
* Click on the Plus icon on the Job BaseInfo details page as shown in the below image.
* Once clicked, it will redirect to the page for creating a new Job BaseInfo and the user will be asked to fill details in the following Tabs:
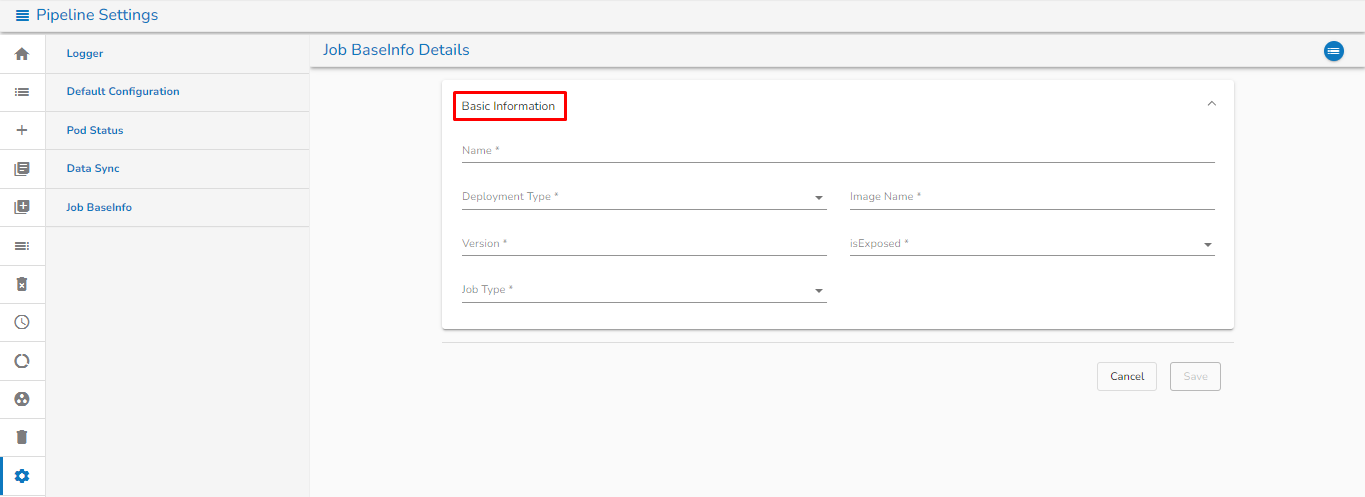
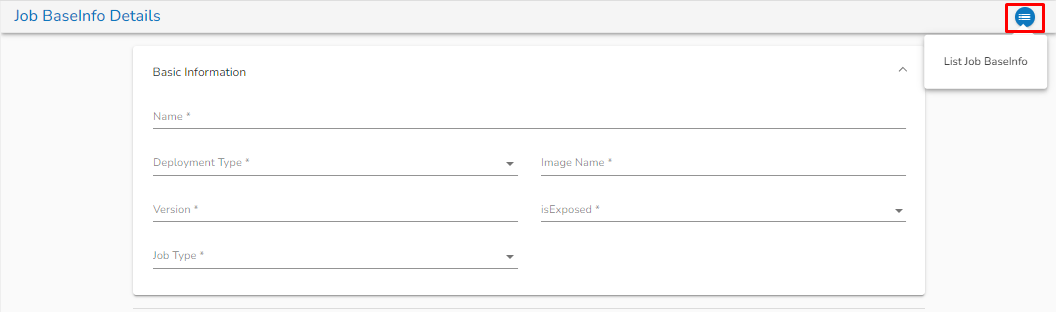
**Basic Information Tab:**
Basic information tab
1. **Name:** Provide a Name for the Job BaseInfo.
2. **Deployment type:** Select the Deployment type from the drop-down.
3. **Image Name:** Enter the Image name for the Job BaseInfo.
4. **Version:** Specify the version.
5. **isExposed:** This option will be automatically filled as True once the deployment type is selected
6. **Job type:** Select the job type from the drop down.
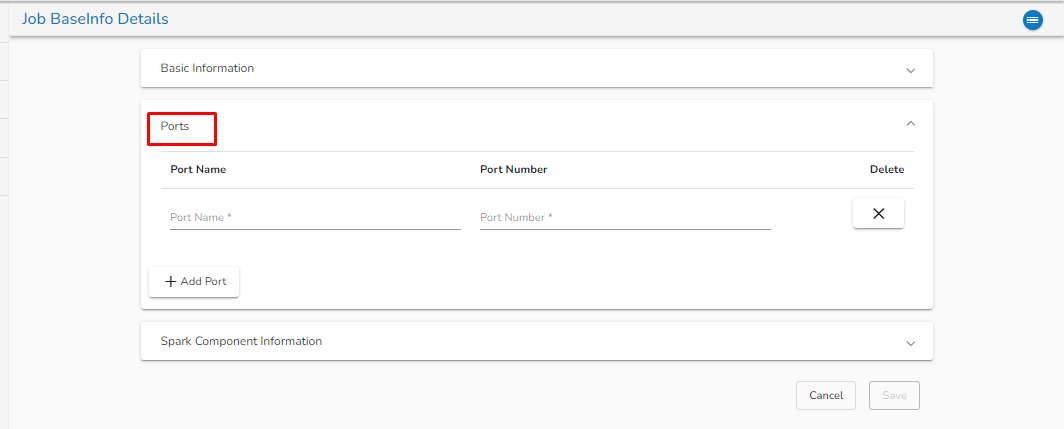
**Ports Tab:**
Ports Tab
* **Port Name:** Enter the Port name.
* **Port Number:** Enter the Port number.
* **Delete:** The user can delete the port details by clicking on this option.
* **Add Port:** The user can add the Port by clicking on this option.
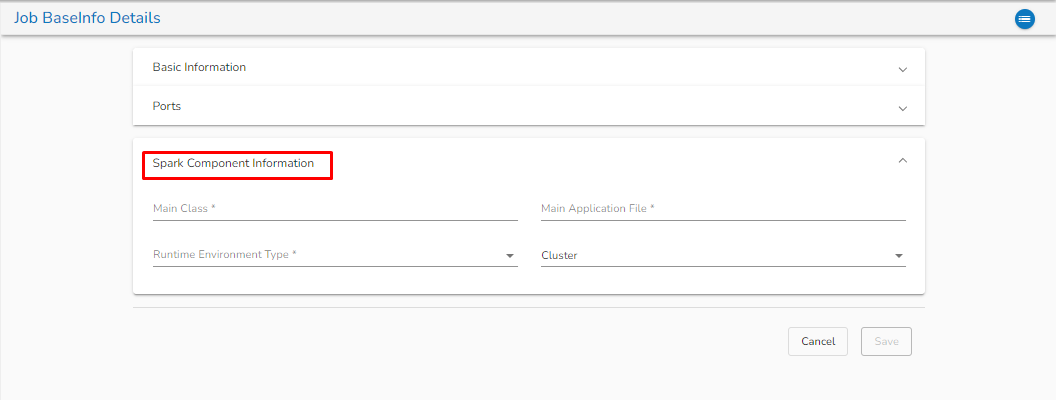
**Spark component information:**
* **Main class:** Enter the Main class for creating the Job BaseInfo.
* **Main application file:** Enter the main application file.
* **Runtime Environment Type:** Select from the drop-down. There are three options available: Scala, Python and R.
* Now, click on **Save** option to create the Job BaseInfo.
Once the Job BaseInfo is created, the user can redirect to the List Job BaseInfo page by clicking on the List Job BaseInfo icon as shown in the below image:
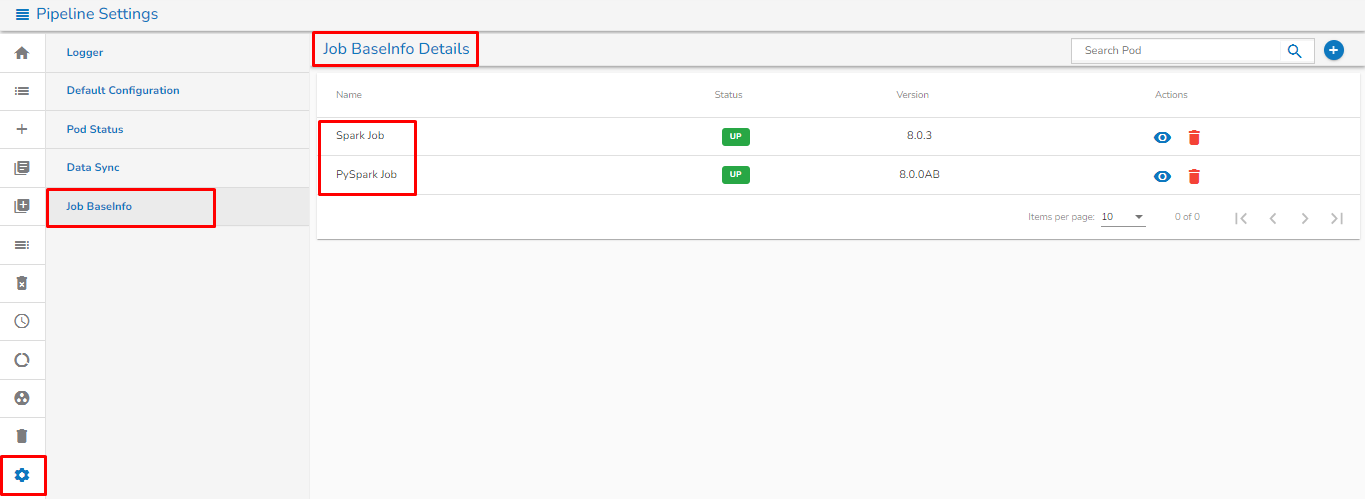
**List Job BaseInfo Page:**
This Page will show the list of all created Job BaseInfo as shown in the below image:
* The ***Name*** column represents the Name of the Job BaseInfo.
* The ***Status*** column will display the status of the Job BaseInfo.
* The ***Version*** column displays the version of the Job BaseInfo.
* The user can see the details of Job Baseinfo by clicking on View icon . Once clicked on view icon, the user can see the details of Job BaseInfo which were provide at the time of creating of that Job BaseInfo.
* The user can delete the Job BaseInfo by clicking on delete  icon.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)