# DB Reader
This task is used to read the data from the following databases: ***MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL***.
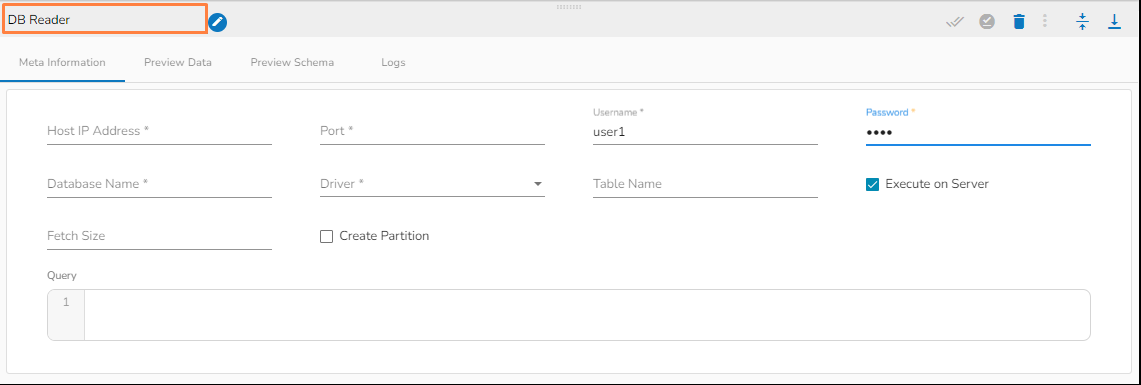
**Please follow the below steps to configure the meta information of DB Reader:**
DB Reader Task
* **Host IP Address:** Enter the Host IP Address for the selected driver.
* **Port:** Enter the port for the given IP Address.
* **Database name:** Enter the Database name.
* **Table name:** Provide a single or multiple table names. If multiple table name has be given, then enter the table names separated by comma(,)**.**
* **User name:** Enter the user name for the provided database.
* **Password:** Enter the password for the provided database.
* **Driver:** Select the driver from the drop down. There are 6 drivers supported here: ***MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL***.
* **Fetch Size:** Provide the maximum number of records to be processed in one execution cycle.
* **Create Partition**: This is used for performance enhancement. It's going to create the sequence of indexing. Once this option is selected, the operation will not execute on server.
* **Partition By:** This option will appear once create partition option is enabled. There are two options under it:
* **Auto Increment**: The number of partitions will be incremented automatically.
* **Index**: The number of partitions will be incremented based on the specified Partition column.
* **Query:** Enter the spark SQL query in this field for the given table or table(s). Please refer the below image for making query on multiple tables.
{% hint style="info" %}
***Please Note:***
* *The ClickHouse driver in the Spark components will use HTTP Port and not the TCP port.*
* In the case of data from multiple tables (join queries), one can write the join query directly without specifying multiple tables, as only one among table and query fields is required.
{% endhint %}