
Schema Validator
Schema Validator component lets the users create validation rules for their fields, such as allowed data types, value ranges, and nullability.
The Schema Validator component has two outputs. The first one is to pass the Schema Validated records successfully and the second one is to pass the Bad Record Event.
Check out the given demonstration to configure the Schema Validator component.
All component configurations are classified broadly into the following sections:
Meta Information
Please Note: Schema Validator will only work for flat JSON data, it will not work on array/list or nested JSON data.
{'Emp_id':248, 'Age':20, 'city': 'Mumbai, 'Dept':'Data_Science'}
{'Id':248, 'name': 'smith', 'marks':[80,85,70,90,91], 'Dept':{'dept_id':20,'dept_name':'data_science','role':'software_engineer'}}
Steps to Configure the Schema Validator
Access the Schema Validator component from the Ingestion component.
Drag the Schema Validator component to the Pipeline workflow canvas and connect it with the required components.
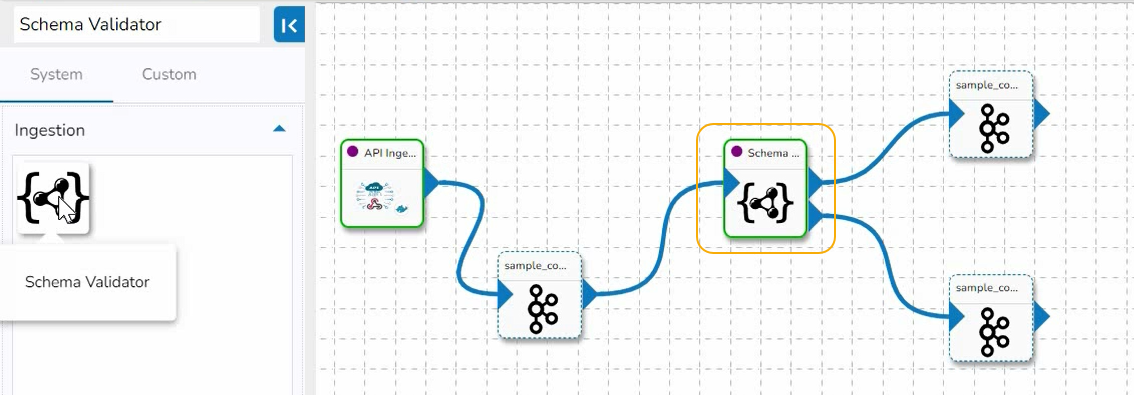
Click the Schema Validator component.
It displays the component configuration tabs below:
Basic Information
Invocation Type: The user can select any one invocation type from the given choices.
Real-Time: If the Real-Time option is selected in invocation type, the component never goes down when the pipeline is active. This is for the situations when you want to keep the component ready all the time to consume data.
Batch-Size: Is Batch is selected as invocation type, the component needs a trigger to initiate the process from the previous event. Once the process of the component is finished and there are no new Events to process, the component goes down.
Batch Size: The Pipeline components process the data in batches. This batch size is given to define the maximum number of records that you want to process in a single cycle of operation. This is really helpful if you want to control the number of records being processed by the component if the unit record size is huge.
Failover Event: The Failover Event can be mapped through the given field. If the component gets failed due to any glitch, all the needed data to perform the operation goes to this Event with the failure cause and timestamp.
Intelligent Scaling: By enabling this option helps the component to scale up to the max number of instances by automatically reducing the data processing. This feature detects the need to scale up the components in case of higher data traffic.
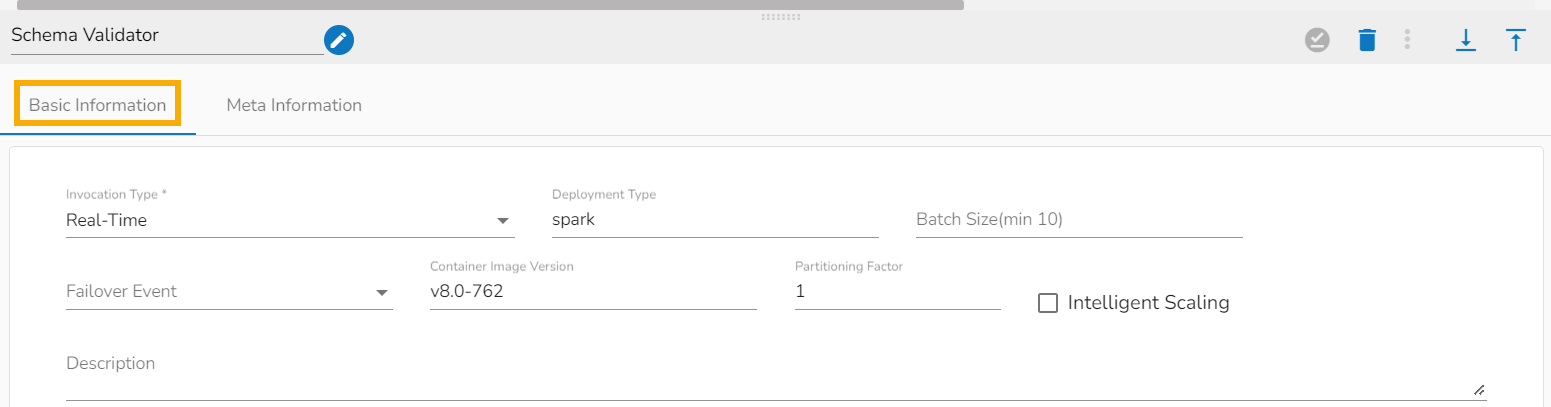
Please Note: The Intelligent Scaling option appears if the selected Invocation Type is Real-Time.
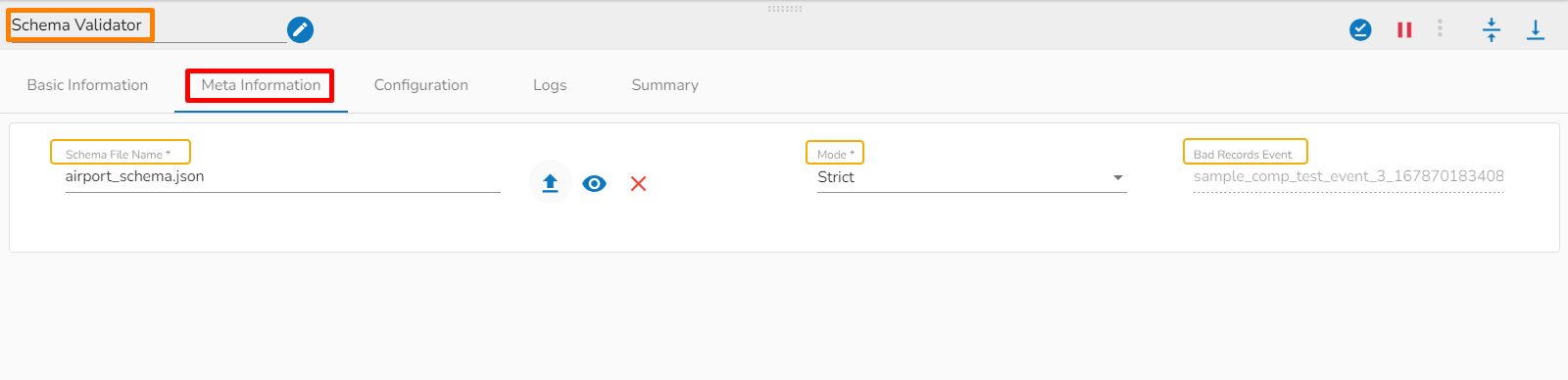
Meta Information
Schema File Name: This specifies the name of uploaded Schema file.
Choose File: This option allows you to upload your schema file.
View Schema: This option allows you to view uploaded schema file.
Remove File: This option allows you to remove uploaded schema file.
Mode: Two choices are provided under the Meta Information of the Schema Validator to choose a mode.
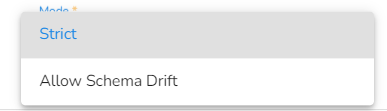
Strict: Strict mode intends to prevent any unexpected behaviors or silently ignored mistakes in user schemas. It does not change any validation results compared with the specification, but it makes some schemas invalid and throws exception or logs warning (with strict: "log" option) in case any restriction is violated and sends them to bad record event.
Allow Schema Drift: Schema drift is the case where the used data sources often change metadata. Fields, columns, types etc. can be added, removed, or changed on the fly. It allows slight changes in the data schema.
Bad Records Event: The records that are rejected by the Schema Validator will automatically go to the Bad Records Event.
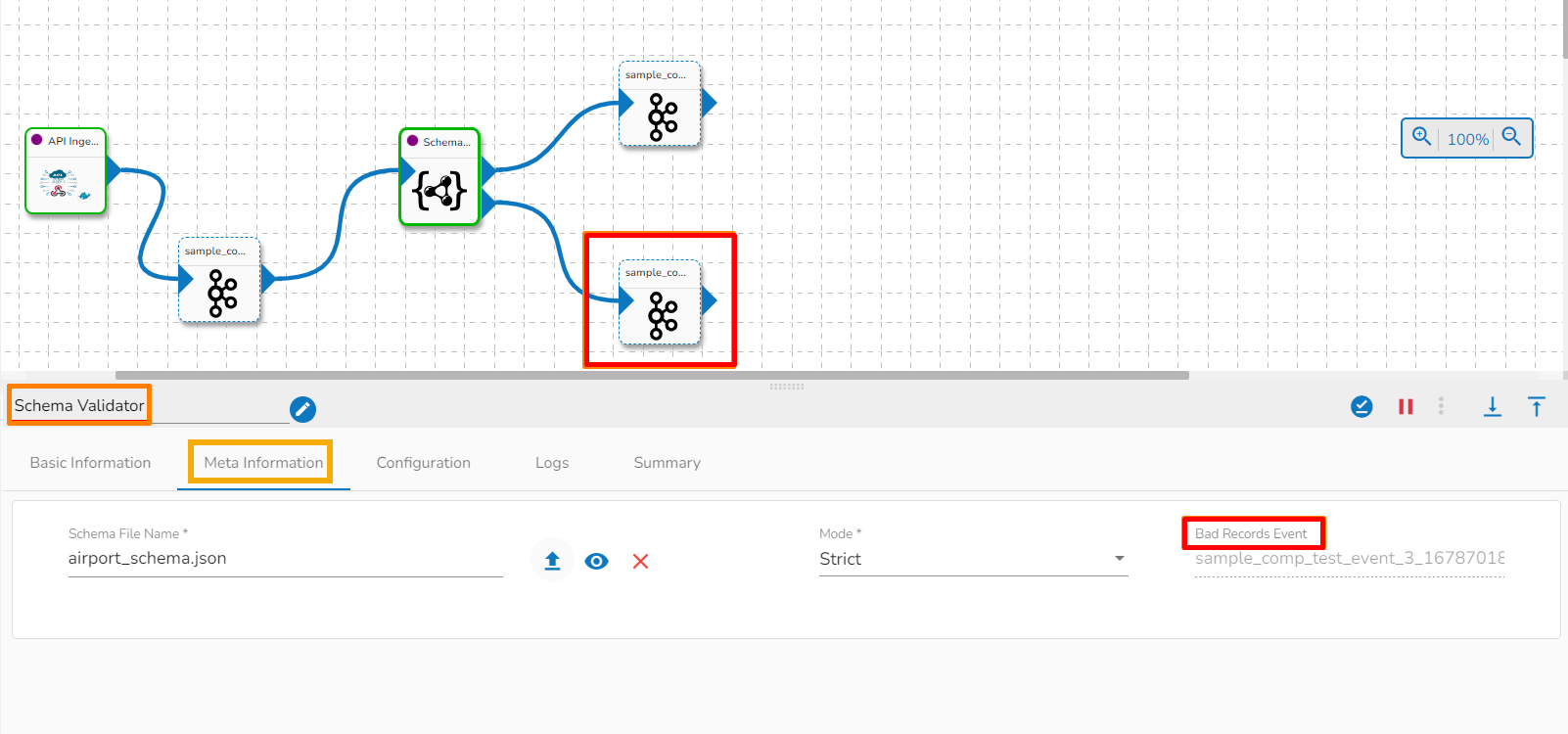
Please Note: The Event component connected to the second node of the Schema Validator component automatically gets mapped as the Bad record Event in the workflow.
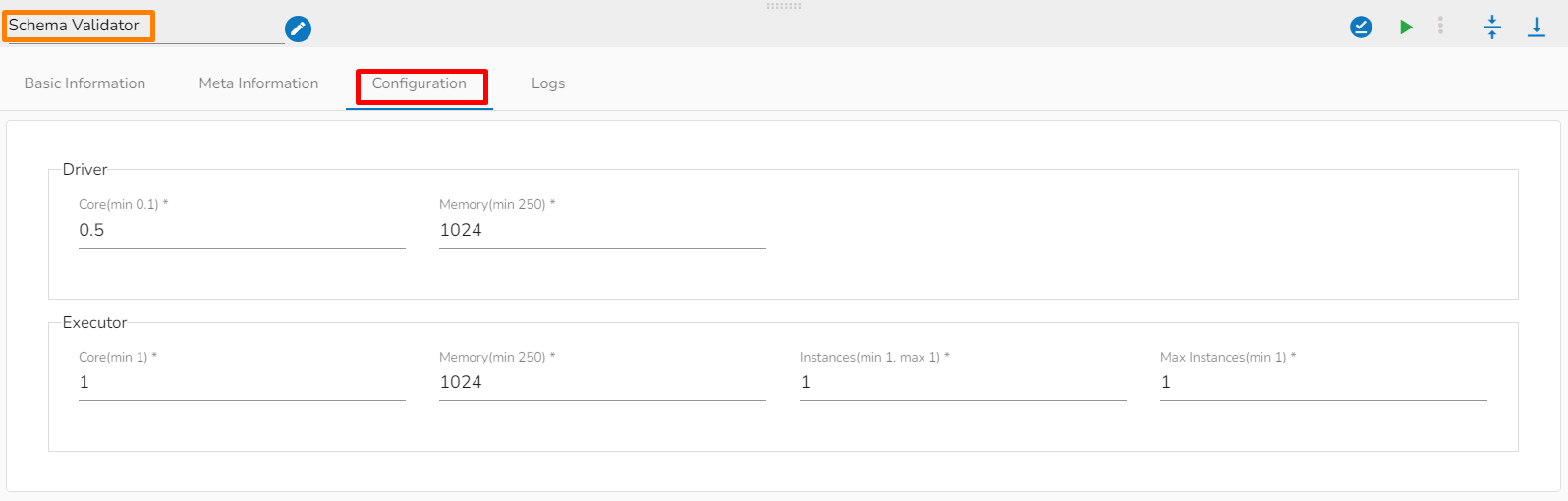
Resource Configuration
The Schema Validator is a Spark Component, so its configuration is slightly different from the Docker components. When the spark components are deployed, there are two pods that come up:
Driver
Executor
Instances: It provides the number of instances used for parallel processing. If the user gives N no. of instances in the Executor's configuration those many executor pods will be deployed.
Please Note:
Give the separate configurations for Driver and Executor.
After configuring the Schema Validator component, the user can save and activate the pipeline to run the created Pipeline workflow.
Future Plan: Schema Validator will be able to process nested JSON data.