> For the complete documentation index, see [llms.txt](https://docs.bdb.ai/data-pipeline-2/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.bdb.ai/data-pipeline-2/data-pipeline/real-time-and-batch-orchestration.md).
# Real-time and Batch Orchestration
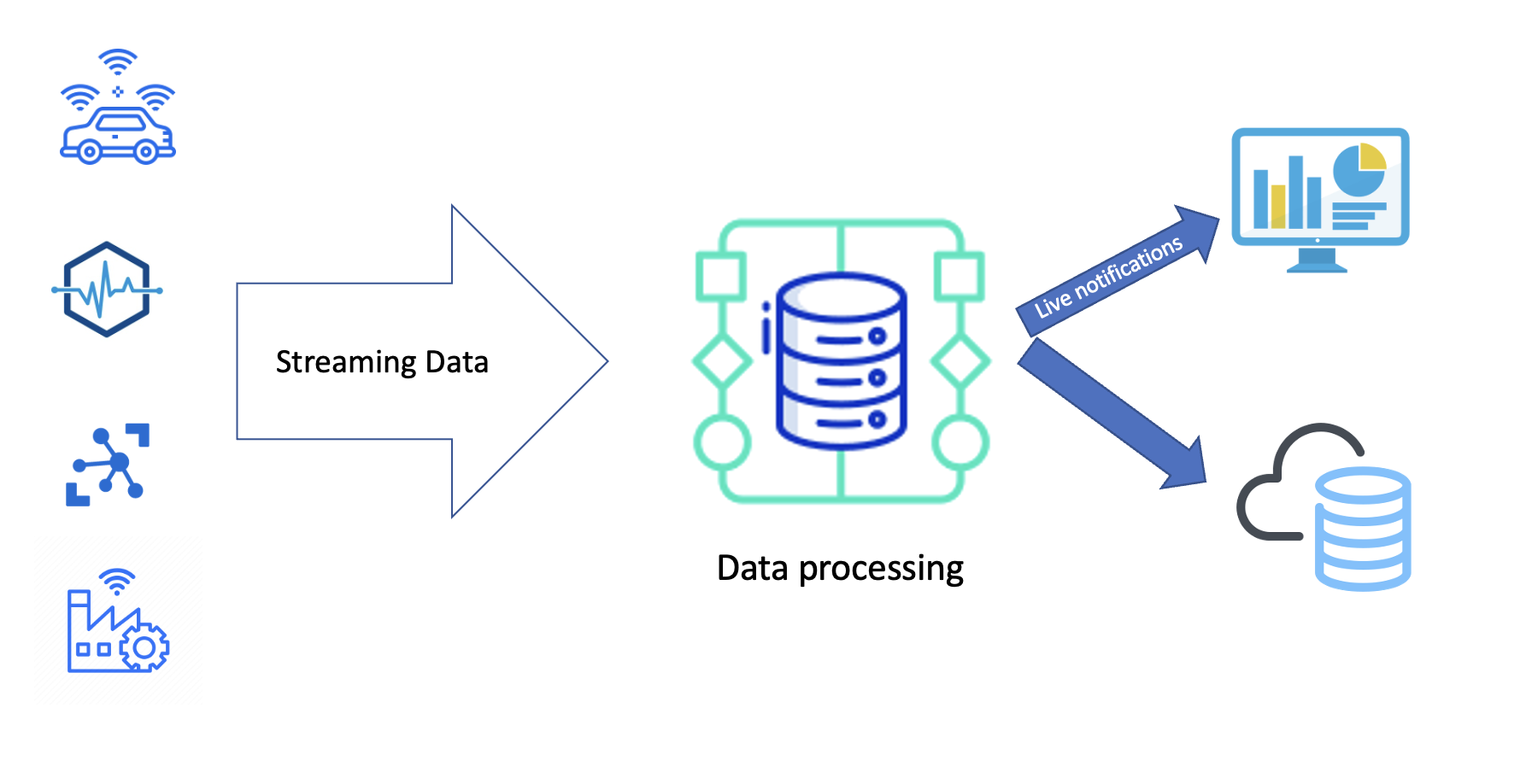
Real-time processing deals with streams of data that are captured in real-time and processed with minimal latency. These processes run continuously and stay live even if the data info has stopped.
Real time data pipeline
Batch job orchestration runs the process based on a trigger. In the BDB Data Pipeline, this trigger is the input event. Anytime data is pushed to the input trigger, the job will kick start. After completing the job, the process is gracefully terminated. This process can be near real-time. Also, it allows you to effectively utilise the compute resources.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.bdb.ai/data-pipeline-2/data-pipeline/real-time-and-batch-orchestration.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.