
PySpark Job
Please go through the below given demonstration to create and configure a Pyspark Job.
Creating a PySpark job
Open the pipeline homepage and click on the Create Job option.
The New Job page opens.
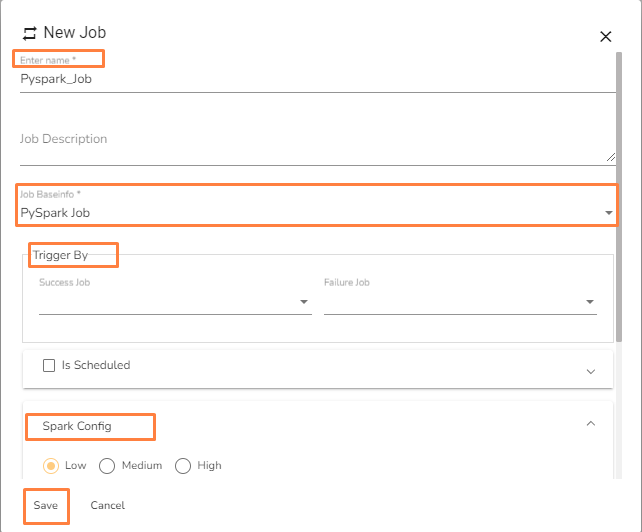
Provide the following information:
Enter name: Enter the name for the job.
Job Description: Add description of the Job (It is an optional field).
Job Baseinfo: Select PySpark Job option from the drop in Job Base Information.
Trigger By: The PySpark Job can be triggered by another Job or PySpark Job. The PySpark Job can be triggered in two scenarios from another jobs:
On Success: Select a job from drop-down. Once the selected job is run successfully, it will trigger the PySpark Job.
On Failure: Select a job from drop-down. Once the selected job gets failed, it will trigger the PySpark Job.
Is Schedule: Put a checkmark in the given box to schedule the new Job.
Spark config: Select resource for the job.
Click on Save option to save the Job.
The PySpark Job gets saved and it will redirect the user to the Job workspace.
Configuring a PySpark Job:
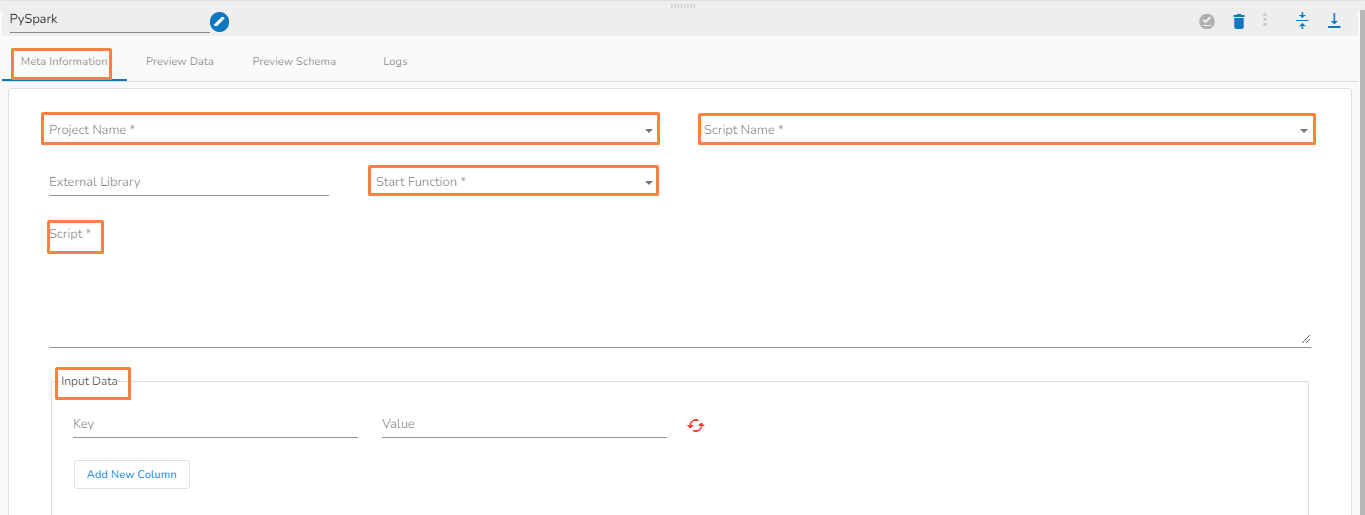
Once the PySpark Job is created, follow the below given steps to configure the Meta Information tab of the PySpark Job.
Project Name: Select the same Project using the drop-down menu where the concerned Notebook has been created.
Script Name: This field will list the exported Notebook names which are exported from the Data Science Lab module to Data Pipeline.
Please Note: The script written in DS Lab module should be inside a function. Refer the Export to Pipeline page for more details on how to export a PySpark script to the Data Pipeline module.
External Library: If any external libraries are used in the script the user can mention it here. The user can mention multiple libraries by giving comma(,) in between the names.
Start Function: Select the function name in which the script has been written.
Script: The Exported script appears under this space.
Input Data: If any parameter has been given in the function, then the name of the parameter is provided as Key and value of the parameters has to be provided as value in this field.
Please note: We are currently supporting JDBC connector like ClickHouse, PostgreSQL and MongoDB Spark connector.