# Sandbox Reader
This task can read the data from the Network pool of Sandbox.
**Please follow the below steps to configure the meta information of ES Reader:**
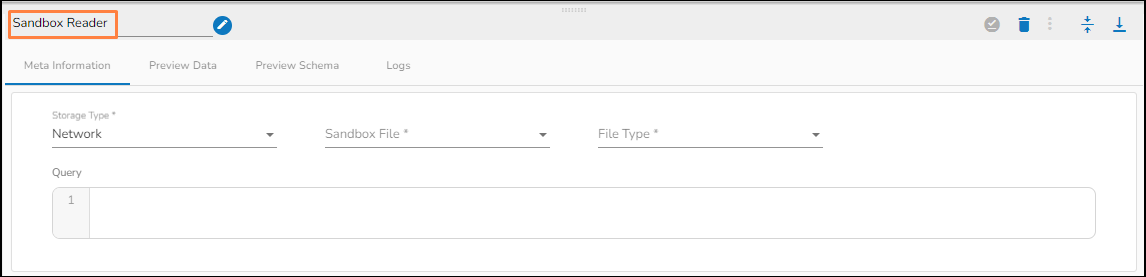
Sandbox Reader Task
* **Storage Type:** This field is pre-defined.
* **Sandbox File:** Select the file name from the drop-down.
* **File Type:** Select the file type from the drop down.
* There are four(5) types of file extensions are available under it:
* ***CSV:*** The ***Header*** and ***Infer Schema*** fields get displayed with ***CSV*** as the selected File Type. Enable ***Header*** option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
* ***JSON***: The **Multiline** and **Charset** fields get displayed with ***JSON*** as the selected File Type. Check-in the **Multiline** option if there is any multiline string in the file.
* ***PARQUET***: No extra field gets displayed with PARQUET as the selected File Type.
* ***AVRO***: This File Type provides two drop-down menus.
* ***Compression***: Select an option out of the ***Deflate*** and ***Snappy*** options.
* ***Compression Level***: This field appears for the Deflate compression option. It provides **0** to **9** levels via a drop-down menu.
* **XML:** Select this option to read XML file. If this option is selected, the following fields will get displayed:
* **Query:** Provide Spark SQL query in this field.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.bdb.ai/data-pipeline-2/getting-started/homepage/create/creating-a-new-job/task-components/readers/sandbox-reader.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.