
Exporting a Script From Data Science Lab
This feature enables users to export their written scripts from DS Lab notebook in order to use them in Pipeline and Jobs
Prerequisite: The user needs to create a project under the DS Lab module before using this feature.
Follow the below-given steps to export a script from the DS Lab notebook:
Activate and open a project under the DS Lab module.
The user can create or open the previously created notebook where the scripts have been written.
Go to the Notebook options and click the Export option.
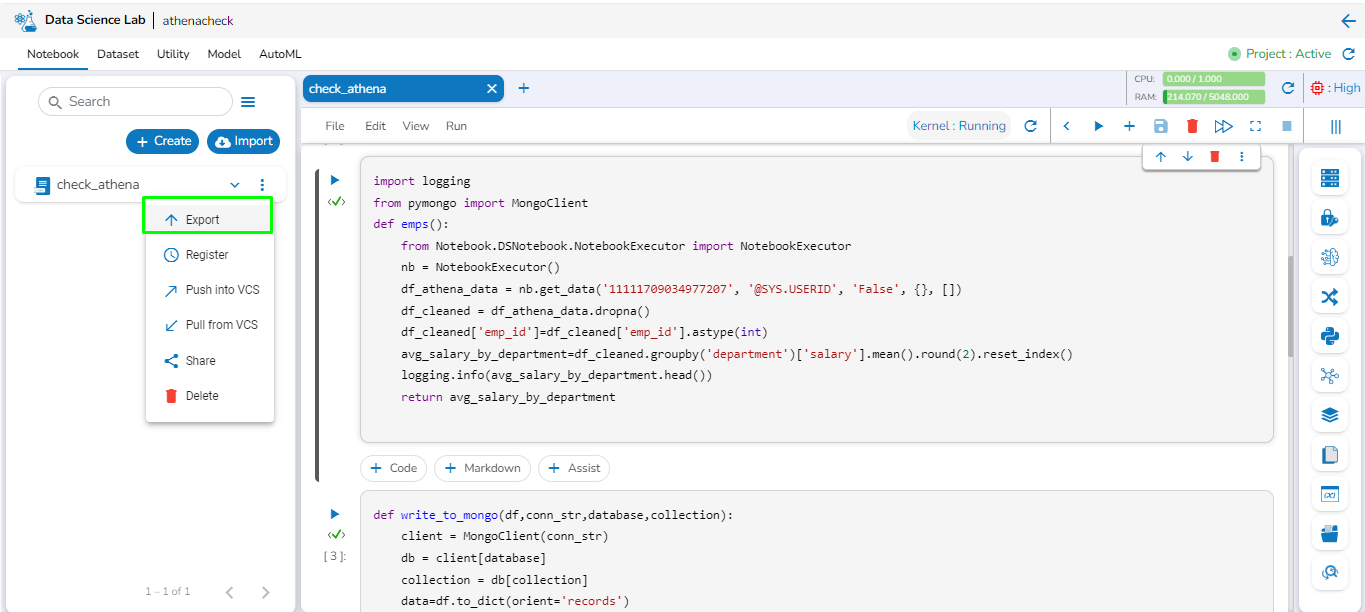
The Export to Pipeline/Git panel opens from the right side of the window; select Export to Pipeline option.
Select the scripts using the check boxes to export them.
Click the Next option.
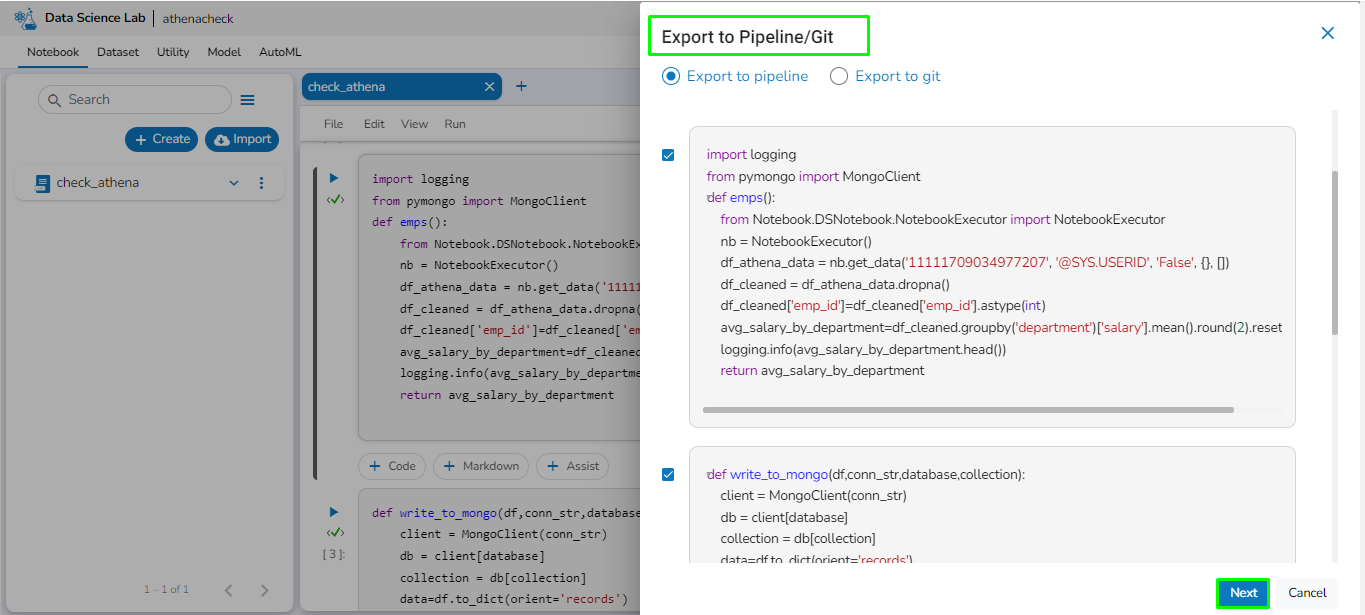
Click the Validate icon to validate the selected scripts.
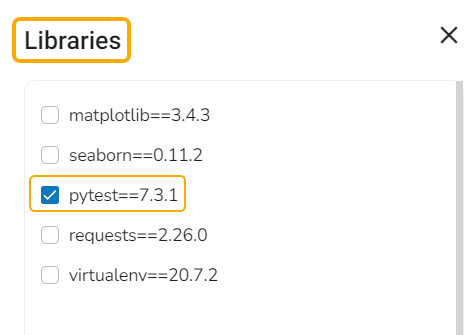
The user can also export External Libraries used in the project along with scripts.
Click the External Libraries
 icon.
icon. The Libraries panel opens. Select the necessary libraries to be exported along with the scripts.
A notification message appears to ensure the user for the validation of the script.
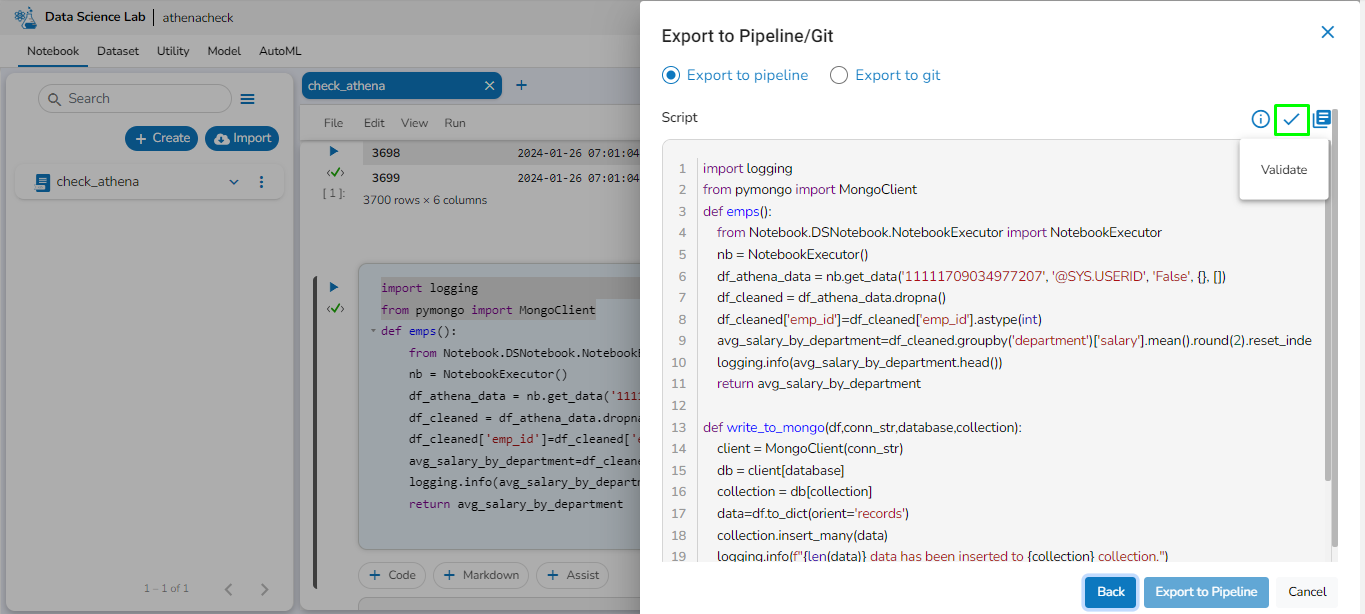
After that, click on the Export to Pipeline option, and the selected scripts will be exported along with the chosen external libraries.
The user can use the exported scripts in the Pipeline, Jobs (Python Job, PySpark Job).
Please Note: Files with the .ipynb extension can be exported to the pipelines and jobs for the further user, while those with the .py extension can only be utilized as the utility files. Additional information on utility files can be found here: Utility
Last updated