
Kafka Consumer
The Kafka Consumer component consumes the data from the given Kafka topic. It can consume the data from the same environment and external environment with CSV, JSON, XML, and Avro formats. This comes under the Consumer component group.
All component configurations are classified broadly into the following sections:
Meta Information
Check out the steps provided in the demonstration to configure the Kafka Consumer component.
Please Note: It currently supports SSL and Plaintext as Security types.

This Component can read the data from external Brokers as well with SSL as the security type and host Aliases:

Steps to Configure
Drag and drop the Kafka Consumer Component to the Workflow Editor.

Click on the dragged Kafka Consumer component to get the component properties tabs.
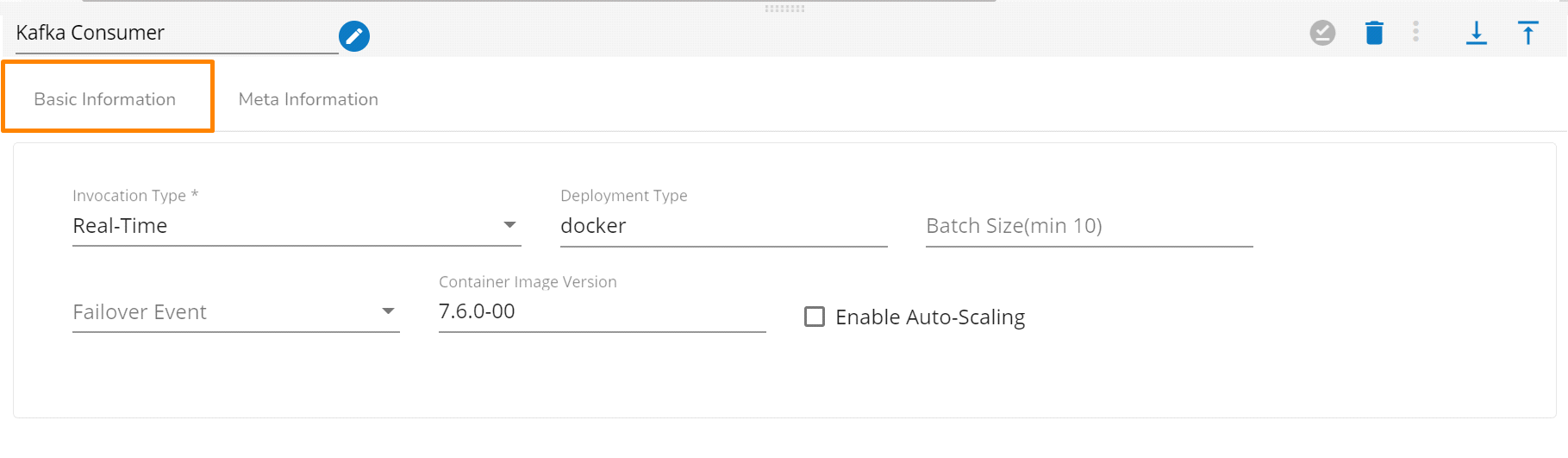
Configure the Basic Information tab.
Select an Invocation type from the drop-down menu to confirm the running mode of the component. Select the Real-Time option from the drop-down menu.
Deployment Type: It displays the deployment type for the component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu.
Batch Size (min 10): Provide the maximum number of records to be processed in one execution cycle (Min limit for this field is 10
Enable Auto-Scaling: Component pod scale up automatically based on a given max instance, if component lag is more than 60%.
Configuring meta information of Kafka Consumer:
Topic Name: Specify the topic name that the user wants to consume data from Kafka.
Start From: The user will find four options here. Please refer at the bottom of the page for a detailed explanation along with an example.
Processed:
It Represents the offset that has been successfully processed by the consumer.
This is the offset of the last record that has been successfully read and processed by the consumer.
By selecting this option, the consumer initiates data consumption from the point where it previously successfully processed, ensuring continuity in the consumption process.
Beginning:
It Indicates the earliest available offset in a Kafka topic.
When a consumer starts reading from the beginning, it means it will read from the first offset available in the topic, effectively reading all messages from the start.
Latest:
It represents the offset at the end of the topic, indicating the latest available message.
When a consumer starts reading from the latest offset, it means it will only read new messages that are produced after the consumer starts.
Timestamp:
It refers to the timestamp associated with a message. Consumers can seek to a specific timestamp to read messages that were produced up to that timestamp.
To utilize this option, users are required to specify both the Start Time and End Time, indicating the range for which they intend to consume data. This allows consumers to retrieve messages within the defined time range for processing.
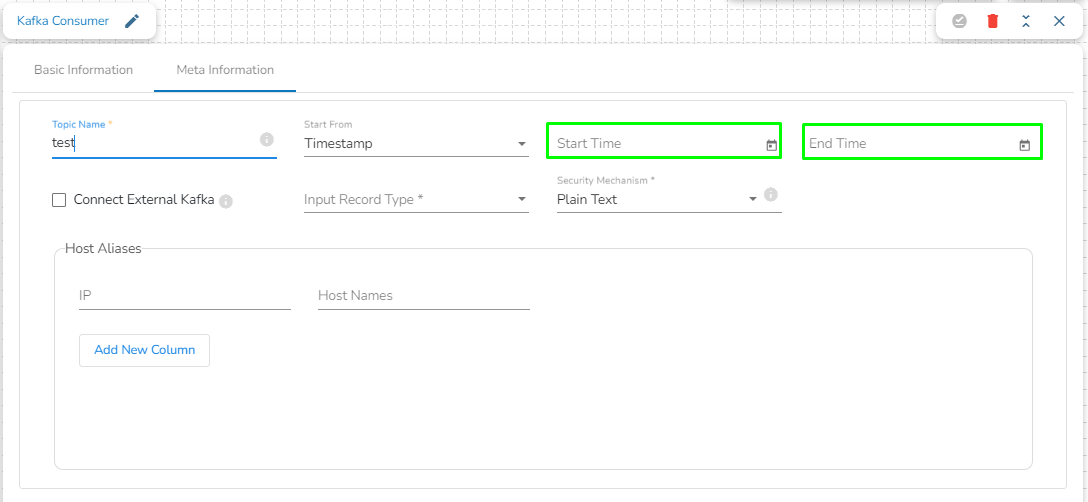
Timestamp Is External: The user can consume external topic data from the external bootstrap server by enabling the Is External option. The Bootstrap Server and Config fields will display after enabling the Is External option.
Bootstrap Server: Enter external bootstrap details.
Config: Enter configuration details of external details.
Input Record Type: It contains the following input record types:
CSV: The user can consume CSV data using this option. The Headers and Separator fields will display if the user selects choose CSV input record type.
Header: In this field, the user can enter column names of CSV data that consume from the Kafka topic.
Separator: In this field, the user can enter separators like comma (,) that are used in the CSV data.
JSON: The user can consume JSON data using this option.
XML: The user can consume parquet data using this option.
AVRO: The user can consume Avro data using this option.
Security Type: It contains the following security types:
Plain Text: Choose the Plain Text option if there environment without SSL.
Host Aliases: This option contains the following fields:
IP: Provide the IP address.
Host Names: Provide the Host Names.
SSL: Choose the SSL option if there environment with SSL. It will display the following fields:
Trust Store Location: Provide the trust store path.
Trust Store Password: Provide the trust store password.
Key Store Location: Provide the key store path.
Key Store Password: Provide the key store password.
SSL Key Password: Provide the SSL key password.
Host Aliases: This option contains the following fields:
IP: Provide the IP.
Host Names: Provide the host names.
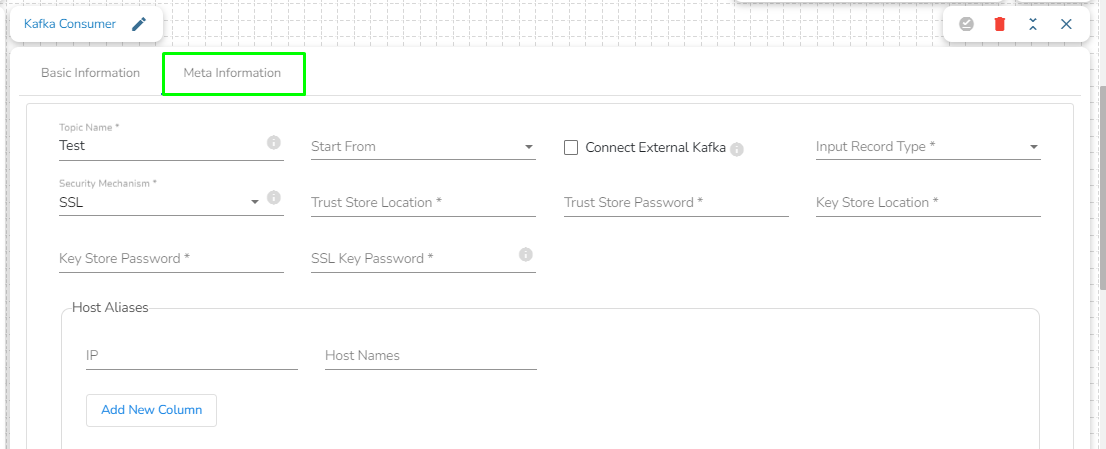
Please Note: The Host Aliases can be used with the SSL and Plain text Security types.
Processed:
If a consumer has successfully processed up to offset 2, it means it has processed all messages up to and including the one at offset 2 (timestamp 2024-02-27 01:00 PM). Now, the consumer will resume processing from offset 3 onwards.
Beginning:
If a consumer starts reading from the beginning, it will read messages starting from offset 0. It will process messages with timestamps from 2024-02-27 10:00 AM onward.
Latest:
If a consumer starts reading from the latest offset, it will only read new messages produced after the consumer starts. Let's say the consumer starts at timestamp 2024-02-27 02:00 PM; it will read only the message at offset 3.
Timestamp:
If a consumer seeks to a specific timestamp, for example, 2024-02-27 11:45 AM, it will read messages with offsets 2 and 3, effectively including the messages with timestamps 2024-02-27 01:00 PM and 2024-02-27 02:30 PM, while excluding the messages with timestamps 2024-02-27 10:00 AM and 2024-02-27 11:30 AM.
Last updated