
ClickHouse Writer (Docker)
Along with the Spark Driver in RDBMS Writer we have Docker writer that supports TCP port.
ClickHouse writer component is designed to write or store data in a ClickHouse database. ClickHouse writers typically authenticate with ClickHouse using a username and password or other authentication mechanisms supported by ClickHouse.
All component configurations are classified broadly into the following sections:
Meta Information
Please go through the given walk-through to understand the configuration steps for the ClickHouse Writer pipeline component.
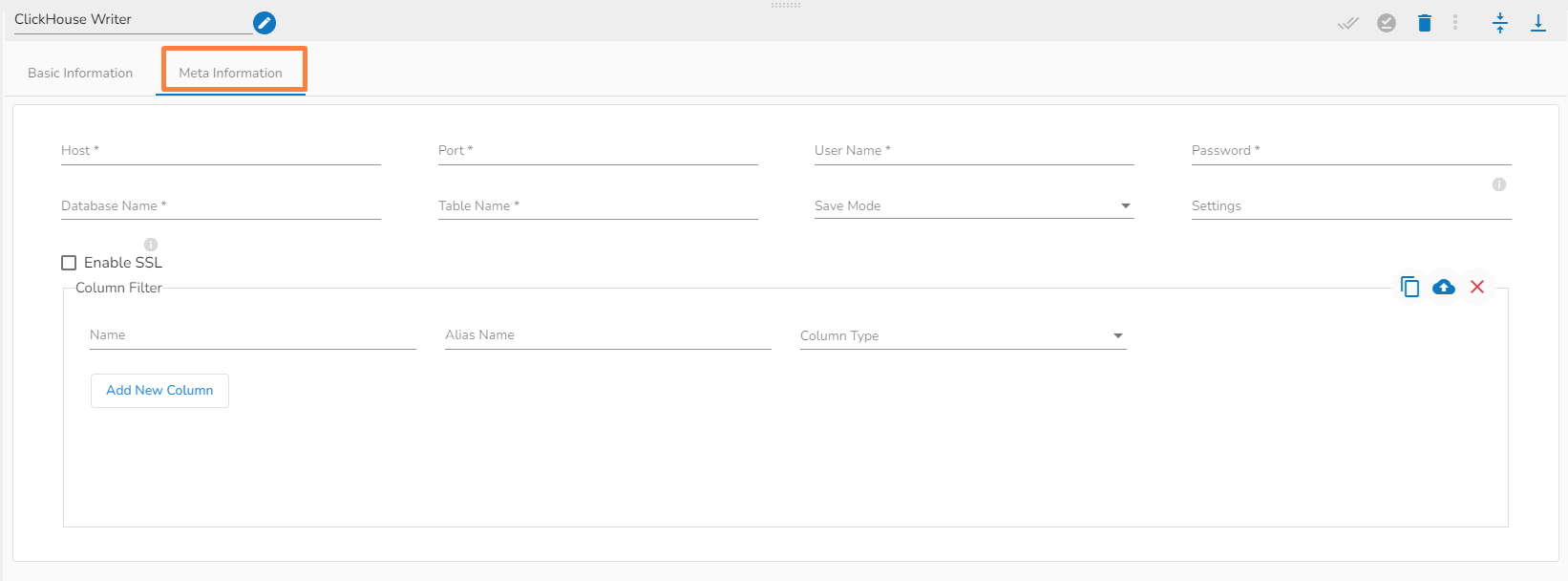
Configuring the Meta information tab of ClickHouse writer
Host IP Address: Enter the Host IP Address.
Port: Enter the port for the given IP Address.
User name: Enter the user name for the provided database.
Password: Enter the password for the provided database.
Database name: Enter the Database name.
Table name: Provide a single or multiple table names. If multiple table name has be given, then enter the table names separated by comma(,). Settings: Option that allows you to customize various configuration settings for a specific query.
Enable SSL: Enabling SSL with ClickHouse writer involves configuring the writer to use the Secure Sockets Layer (SSL) protocol for secure communication between the writer and the ClickHouse server.
Save Mode: Select the Save mode from the drop down.
Column Filter: There is also a section for the selected columns in the Meta Information tab if the user can select some specific columns from the table to read data instead of selecting a complete table so this can be achieved by using the Column Filter section. Select the columns which you want to read and if you want to change the name of the column, then put that name in the alias name section otherwise keep the alias name the same as of column name and then select a Column Type from the drop-down menu.
Use Download Data and Upload File options to select the desired columns.
Upload File: The user can upload the existing system files (CSV, JSON) using the Upload File icon (file size must be less than 2 MB).
Download Data: Users can download the schema structure in JSON format by using the Download Data icon.
Please Note:
ClickHouse Writer component supports only TCP port.
If the user is using Append as the Save mode in ClickHouse Writer (Docker component) and Data Sync (ClickHouse driver), it will create a table in the ClickHouse database with a table engine Memory.