
Pandas Query Component
The Pandas query component is designed to filter the data by applying pandas query on it.
All component configurations are classified broadly into the following sections:
Meta Information
Follow the steps given in the demonstration to configure the Pandas Query component.
Steps to Configure the Pandas Query Component
This component helps the users to get data as per the entered query.
Drag and Drop the Pandas Query component to the Workflow Editor.
The transformation component requires an input event (to get the data) and sends the data to an output event.
Create two Events and drag them to the Workspace.
Connect the input event and the output event to the component (The data in the input event can come from any Ingestion, Reader, or shared events).
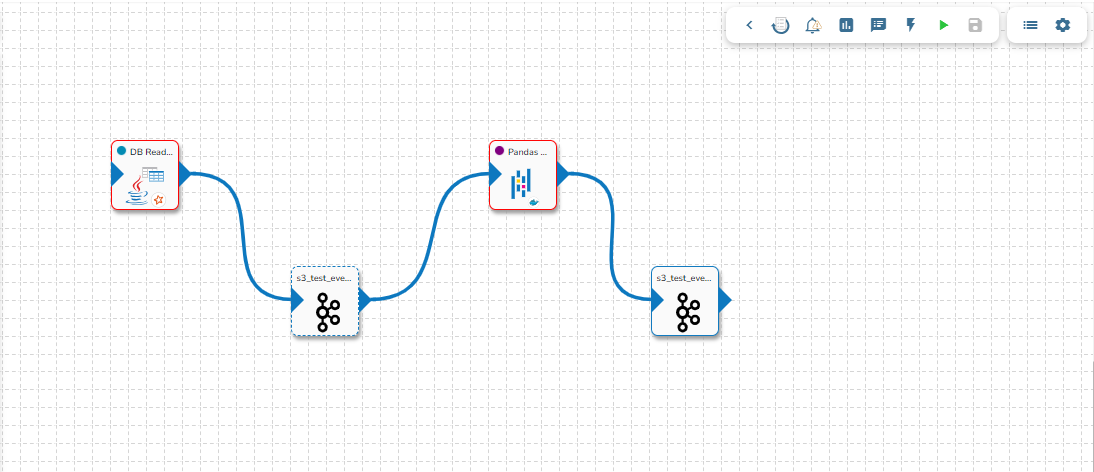
Click the Pandas Query component to get the component properties tabs.
Basic Information Tab
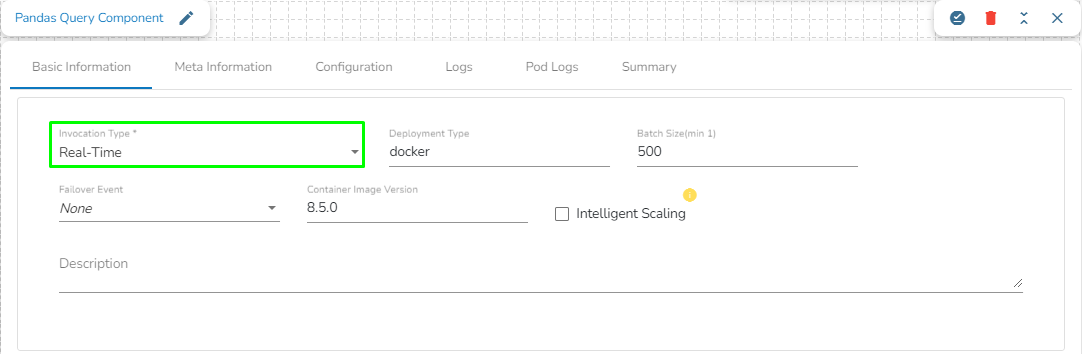
The Basic Information tab opens by default while clicking the dragged component.
Select an Invocation type from the drop-down menu to confirm the running mode of the Pandas Query component. Select ‘Real-Time’ or ‘Batch’ from the drop-down menu.
Deployment Type: It displays the deployment type for the component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu.
Batch Size (min 10): Provide the maximum number of records to be processed in one execution cycle (Min limit for this field is 10).
Meta Information Tab
Open the Meta Information tab and provide the connection-specific details.
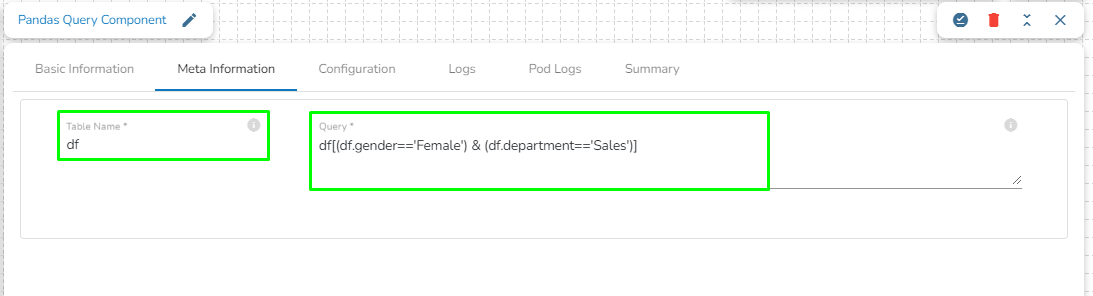
Enter a Pandas query to fetch data from in-event.
Provide the Table Name.
Sample Pandas Query:
In the above given Pandas Query, df is the table name which contains the data from previous event. It will fetch all the rows having gender= 'Female' and department= 'Sales'.
Saving the Component Configuration
Click the Save Component in Storage icon to save the component properties.
A Notification message appears to notify the successful update of the component.

Please Note: The samples of Pandas Query are given below together with the SQL query for the same statements.
Samples Query Examples
SQL Query
Pandas Query
select id from airports where ident = 'KLAX'
airports [airports.ident == 'KLAX'].id
select * from airport_freq where airport_ident = 'KLAX' order by type
airports[(airports.iso_region == 'US-CA') & (airports.type == 'seaplane_base')]
select type, count(*) from airports where iso_country = 'US' group by type having count(*) > 1000 order by count(*) desc
airports[airports.iso_country == 'US'].groupby('type').filter(lambda g: len(g) > 1000).groupby('type').size().sort_values(ascending=False)