
S3 Reader
This task reads the file from Amazon S3 bucket.
Please follow the below mentioned steps to configure meta information of S3 reader task:
Drag the S3 reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
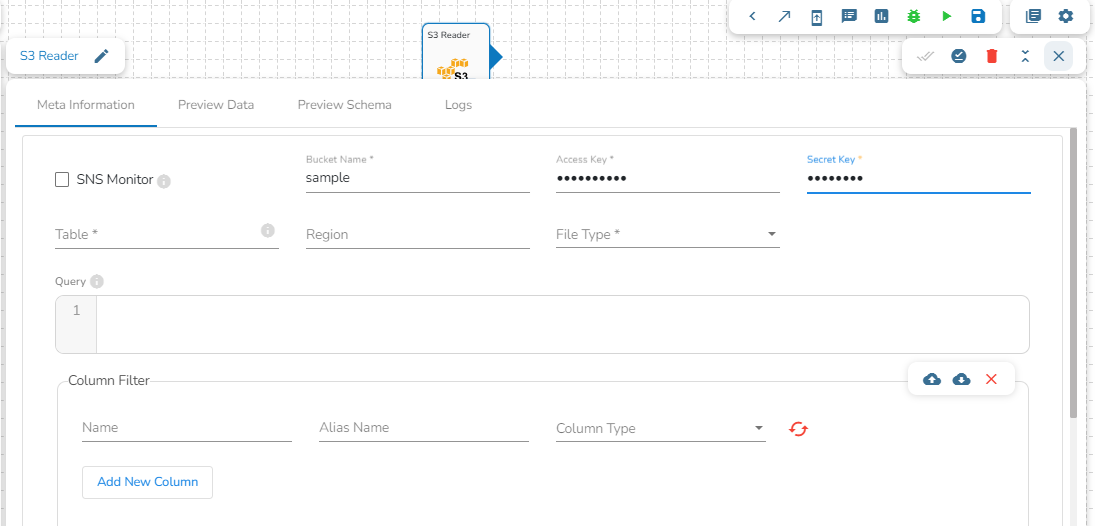
Configuration fields when SNS Monitor is disabled
Bucket Name (*): Enter S3 bucket name.
Region (*): Provide the S3 region.
Access Key (*): Access key shared by AWS to login..
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which is to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO, XML are the supported file types)
Limit: Set a limit for the number of records.
Query: Insert an SQL query (it supports query containing a join statement as well).
Configuration fields when SNS Monitor is enabled
Access Key (*): Access key shared by AWS to login
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which has to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO, XML are the supported file types)
Limit: Set limit for the number of records
Query: Insert an SQL query (it supports query containing a join statement as well)
Partition Columns
Provide a unique Key column name to partition data in Spark.
Please Note:
Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
Once file type is selected the multiple fields will appear. Follow the below steps for the selected different file types.
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.