
Sandbox Writer
A Sandbox writer is used to write the data within a configured sandbox environment.
All component configurations are classified broadly into the following sections:
Meta Information
Check out the given Walk-through on the Sandbox Writer component.
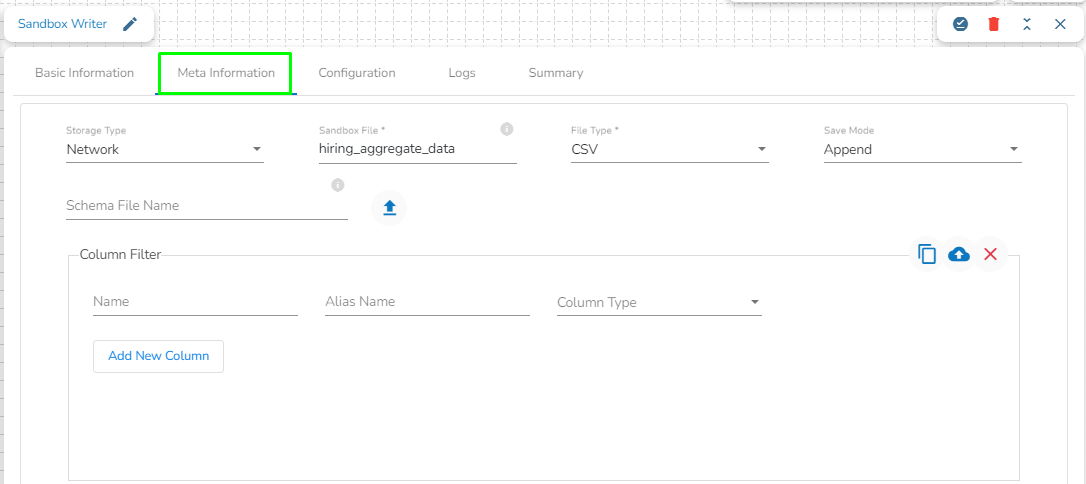
Configuring the Meta Information Tab
Please follow the below mentioned steps to configure the Meta Information Tab of Sandbox Writer:
Storage Type: The user will find two options here:
Network: This option will be selected by default. In this mode, a folder corresponding to the Sandbox file name provided by the user will be created at the Sandbox location. Data will be written into part files within this folder, with each part file containing data based on the specified batch size.
Platform: If the user selects the "Platform" option, a single file containing the entire dataset will be created at the Sandbox location, using the Sandbox file name provided by the user.
Sandbox File: Enter the file name.
File Type: Select the file type in which the data has to be written. There are 4 files types supported here:
CSV
JSON
Text
ORC
Save Mode: Select the save mode from the drop-down menu:
Append: It will append the data in the blob.
Overwrite: It will overwrite the data in the blob.
Schema File Name: Upload a Spark schema file of the data which has to be written in JSON format.
Column Filter: Enter the column names here. Only the specified columns will be fetched from the data from the previous connected event to the Sandbox Writer. In this field, the user needs to fill in the following information:
Name: Enter the name of the column which has to be written from the previous event. The user can add multiple columns by clicking on the "Add New Column" option.
Alias: Enter the alias name for the selected column name. The column name given here will be written in the Sandbox file.
Column Type: Enter the data type of the column.
Upload: This option allows the user to upload a data file in CSV, JSON, or EXCEL format. The column names will be automatically fetched from the uploaded data file and filled out in the Name, Alias, and Column Type fields.
Download Data: This option will download the data filled in the Column Filter field in JSON format.
Delete Data: This option will clear all the information filled in the Column Filter field.
Last updated