
GCS Monitor
The GCS Monitor continuously monitors a specific folder. When a new file is detected in the monitored folder, the GCS Monitor reads the file's name and triggers an event. Subsequently, the GCS Monitor copies the detected file to a designated location as defined and then removes it from the monitored folder. This process is repeated for each file that is found.
Basic Information Tab
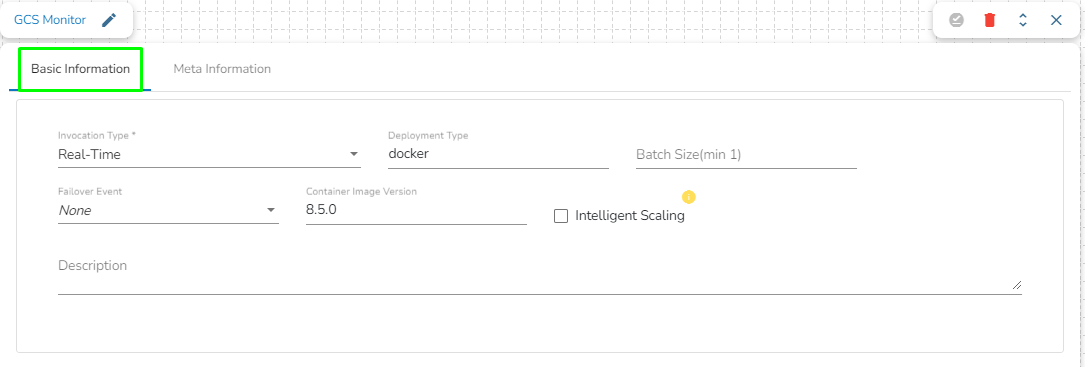
It is the default tab to open for the component while configuring it.
Invocation Type: Select an invocation mode as Real-Time.
Deployment Type: It displays the deployment type for the reader component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu.
Batch Size (min 10): Provide the maximum number of records to be processed in one execution cycle (Min limit for this field is 10).
Steps to configure the meta information of GCS Monitor
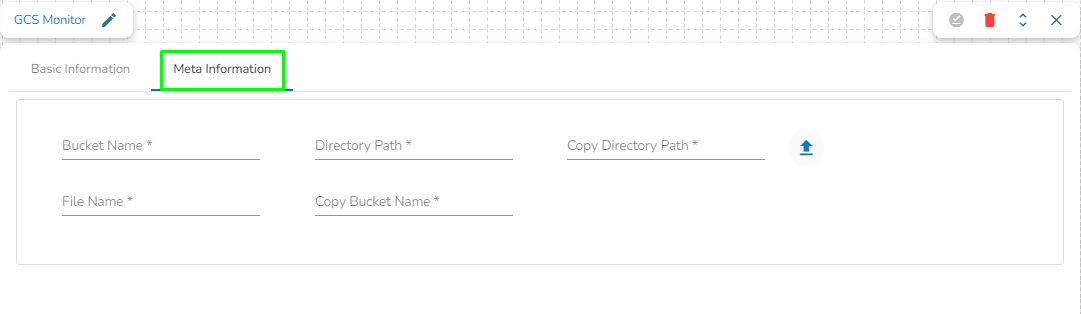
Bucket Name: Enter the source bucket name.
Directory Path: Fill in the monitor folder path using a forward-slash (/). For example, "monitor/".
Copy Directory Path: Specify the copy folder name where you want to copy the uploaded file. For example, "monitor_copy/".
Choose File: Upload a Service Account Key(s) file.
File Name: After the Service Account Key file is uploaded, the file name is auto-generated based on the uploaded file.
Copy Bucket Name: Fill in the destination bucket name where you need to copy the files.