.png)
Dragging the DS Lab Runner to the Pipeline canvas
Dragging the DS Lab Runner to the Pipeline canvas
.png)
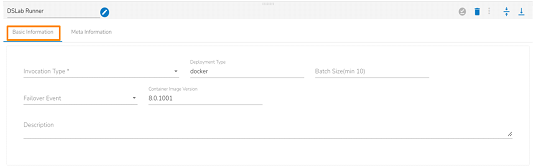
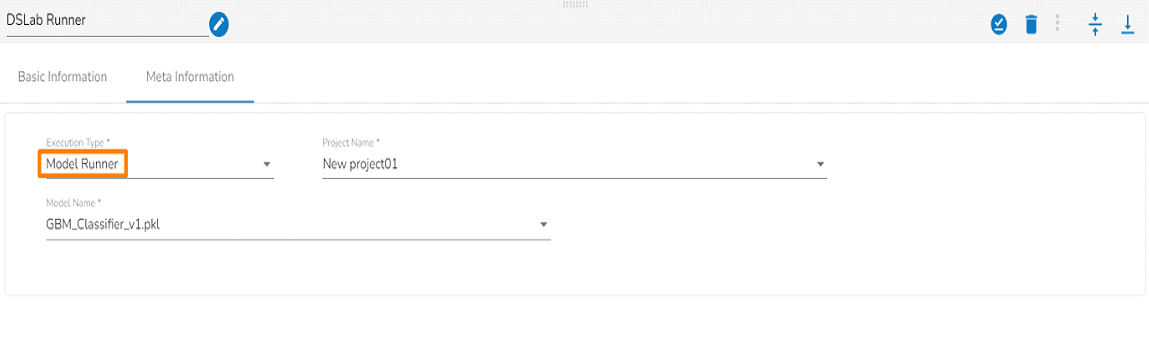
Configuring the Model Runner as an execution type in the Meta Information
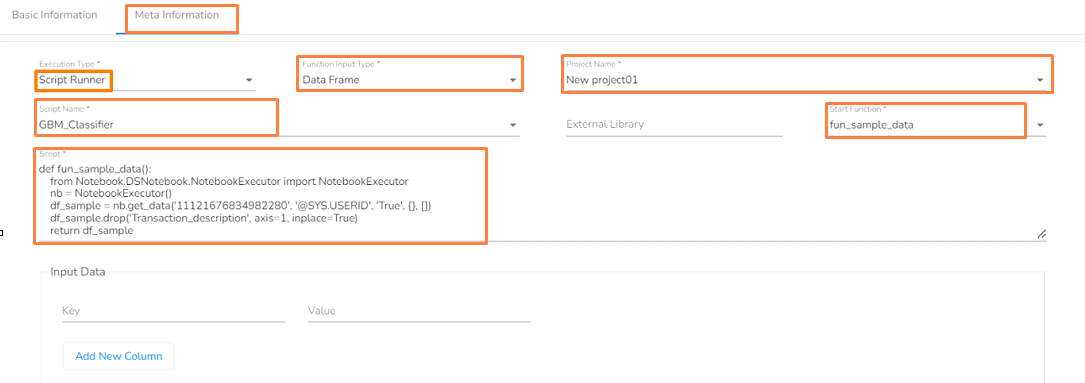
Configuring the Script Runner as an execution type in the Meta Information