
Pipeline Overview
This page provides an overview of all the components used in the pipeline in a single place.
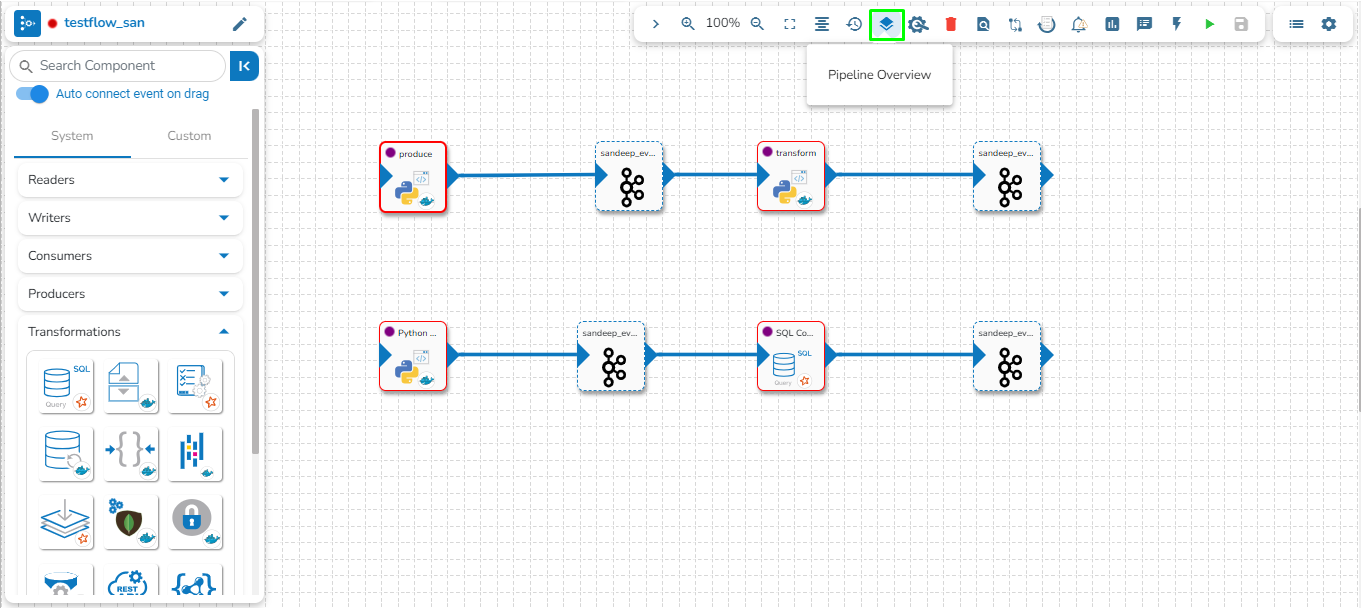
There are following options on the pipeline overview page:
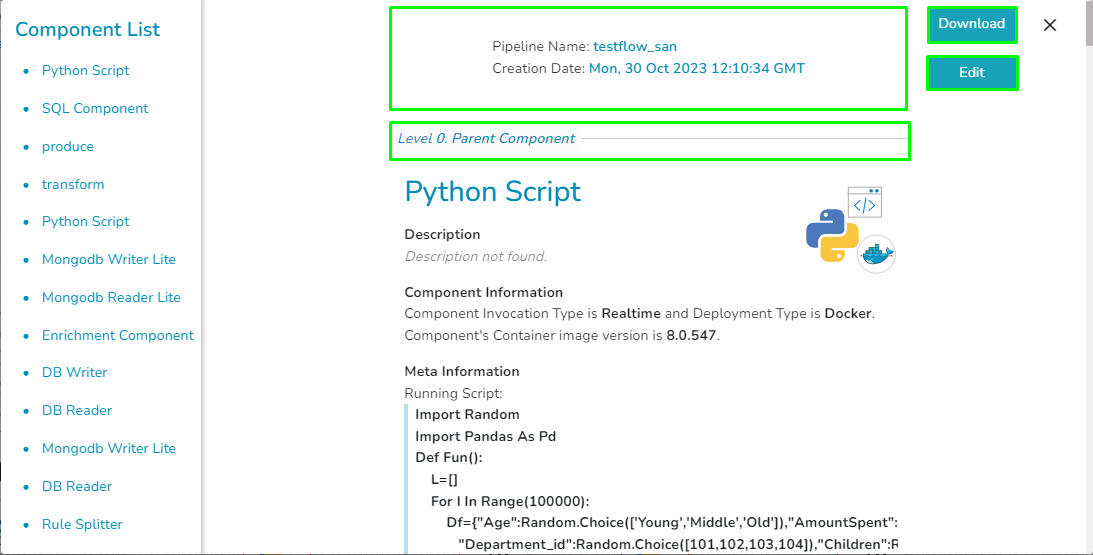
This page provides an overview of all the components used in the pipeline in a single place.