
Sandbox Reader
A Sandbox reader is used to read and access data within a configured sandbox environment.
All component configurations are classified broadly into the following sections:
Meta Information
Before using the Sandbox Reader component for reading a file, the user needs to upload a file in Data Sandbox under the Data Center module.
Please go through the given walk-through for uploading the file in the Data Sandbox under the Data Center module.
Check out the given video on how to configure a Sandbox Reader component.
Steps to configure Sandbox Reader
Navigate to the Data Pipeline Editor.
Expand the Readers section provided under the Component Pallet.
Drag and drop the Sandbox Reader component to the Workflow Editor.
Click on the dragged Sandbox Reader to get the component properties tabs.
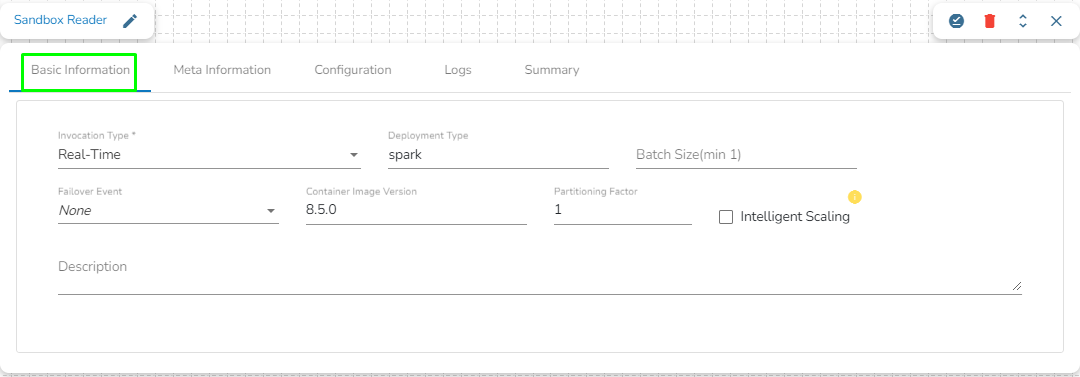
Basic Information
It is the default tab to open for the component while configuring it.
Invocation Type: Select an invocation mode from the Real-Time or Batch options by using the drop-down menu.
Deployment Type: It displays the deployment type for the reader component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu.
Batch Size (min 10): Provide the maximum number of records to be processed in one execution cycle (Minimum limit for this field is 10).
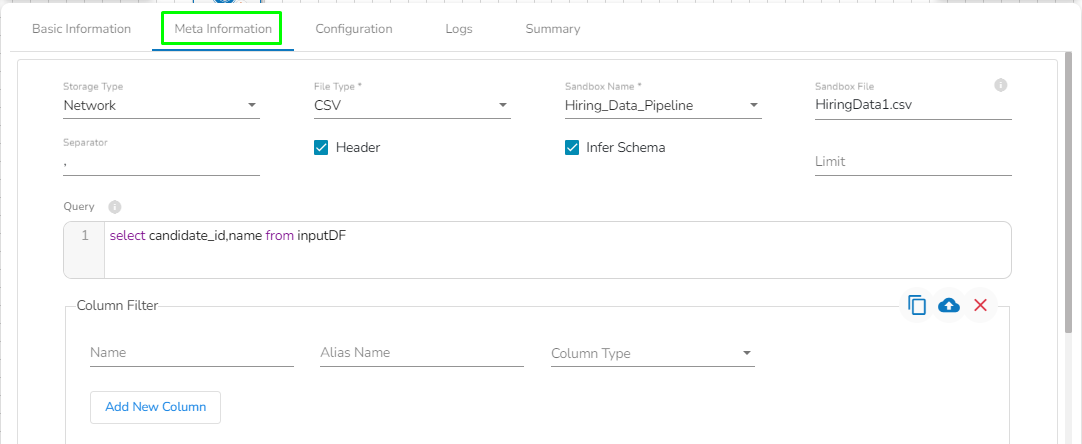
Configuring meta information of Sandbox Reader component:
Storage Type: The user will find two options here:
Network: This option will be selected by default. In this option, the following fields will be displayed:
File Type: Select the type of the file to be read. Supported file types include CSV, JSON, PARQUET, AVRO, XML, and ORC.
Schema: Enter the Spark schema of the file in JSON format.
Sandbox Folder Path: Enter the Sandbox folder name where the data is stored in part files.
Limit: Enter the number of records to be read.
Platform: In this option, the following fields will be displayed:
File Type: Select the type of the file to be read. The supported file types are CSV, JSON, PARQUET, AVRO, XML, and ORC.
Sandbox Name: This field will display once the user selects the file type. It will show all the Sandbox names for the selected file type, and the user has to select the Sandbox name from the drop-down.
Sandbox File: This field displays the name of the sandbox file to be read. It will automatically fill when the user selects the sandbox name.
Limit: Enter the number of records to be read.
Query: Enter a spark SQL query. Take inputDf as a table name.
Column Filter: There is also a section for the selected columns in the Meta Information tab if the user can select some specific columns from the table to read data instead of selecting a complete table so this can be achieved by using the Column Filter section. Select the columns that you want to read and if you want to change the name of the column, then put that name in the alias name section otherwise keep the alias name the same as of column name and then select a Column Type from the drop-down menu.
Use the Download Data and Upload File options to select the desired columns.
Upload File: The user can upload the existing system files (CSV, JSON) using the Upload File icon (file size must be less than 2 MB).
Download Data (Schema): Users can download the schema structure in JSON format by using the Download Data icon.
or
Use the Download Data and Upload File options to select the desired columns.
Partition Columns: To read a specific partition, enter the name of the partitioned column.
Sample Query for Sandbox Reader:
Please Note:
(*) the symbol indicates that the field is mandatory.
Either table or query must be specified for the data readers except for SFTP Reader.
Column Filter- There should not be a data type mismatch in the Column Type for all the Reader components.
Fields in the Meta Information tab may vary based on the selected File Type. All the possibilities are mentioned below:
CSV: The following fields will display when CSV is selected as File Type:
Header: Enable the Header option to retrieve the header of the reading file.
Infer Schema: Enable the Infer Schema option to obtain the true schema of the columns in the CSV file.
Multiline: Enable the Multiline option to read multiline strings in the data.
Schema: This field will be visible only when the Header option is enabled. Enter the Spark schema in JSON format in the schema field to filter out the bad records. To filter the bad records, the user needs to map the failover Kafka event in the Failover Event field in the Basic Information tab.

JSON: The Multiline and Charset fields are displayed with JSON as the selected File Type. Check in the Multiline option to see, if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read the XML file. If this option is selected, the following fields will be displayed:
Infer schema: Enable this option to get the true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
ORC: Select this option to read the ORC file. If this option is selected, the following fields will be displayed:
Push Down: In ORC (Optimized Row Columnar) file format, "push down" typically refers to the ability to push down predicate filters to the storage layer for processing. There will be two options in it:
True: When push-down is set to True, it indicates predicate filters can be pushed down to the ORC storage layer for filtering rows at the storage level. This can improve query performance by reducing the amount of data that needs to be read into memory for processing.
False: When push down is set to False, predicate filters are not pushed down to the ORC storage layer. Instead, filtering is performed after the data has been read into memory by the processing engine. This may result in more data being read and potentially slower query performance compared to when push-down is enabled.
Last updated