
SFTP Reader
SFTP Reader is designed to read and access files stored on an SFTP server. SFTP readers typically authenticate with the SFTP server using a username and password or SSH key pair, which grants access to the files stored on the server
All component configurations are classified broadly into the following sections:
Meta Information
Please follow the demonstration to configure the SFTP Reader and its meta information.
Please go through the below given steps to configure SFTP Reader component:
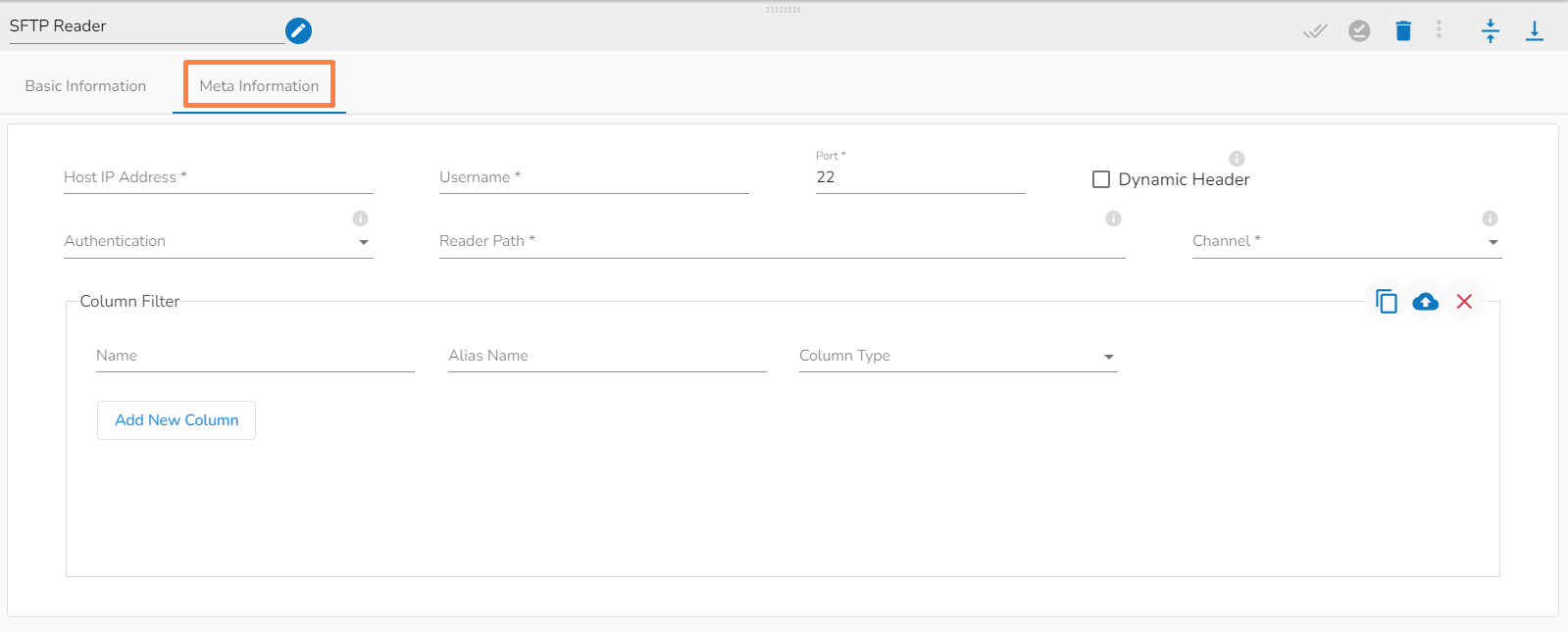
Host: Enter the host.
Username: Enter username for SFTP reader.
Port: Provide the Port number.
Dynamic Header: It can automatically detect the header row in a file and adjust the column names and number of columns as necessary.
Authentication: Select an authentication option using the drop-down list.
Password: Provide a password to authenticate the SFTP component
PEM/PPK File: Choose a file to authenticate the SFTP component. The user must upload a file if this authentication option is selected.
Reader Path: Enter the path from where the file has to be read.
Channel: Select a channel option from the drop-down menu (the supported channel is SFTP).
Column filter: Select the columns that you want to read and if you change the name of the column, then put that name in the alias name section otherwise keep the alias name the same as the column name and then select a Column Type from the drop-down menu.
Use the Download Data and Upload File options to select the desired columns.
Upload File: The user can upload the existing system files (CSV, JSON) using the Upload File icon.
Download Data (Schema): Users can download the schema structure in JSON format by using the Download Data icon.
Last updated