
MQTT Consumer
MQTT(Message Queuing Telemetry Transport) is a lightweight, publish-subscribe, machine to machine network protocol for message queue/message queuing service. It is designed for connections with remote locations that have devices with resource constraints or limited network bandwidth, such as in the Internet of Things.
All component configurations are classified broadly into the following sections:
Meta Information
Follow the given demonstration to configure the MQTT component.
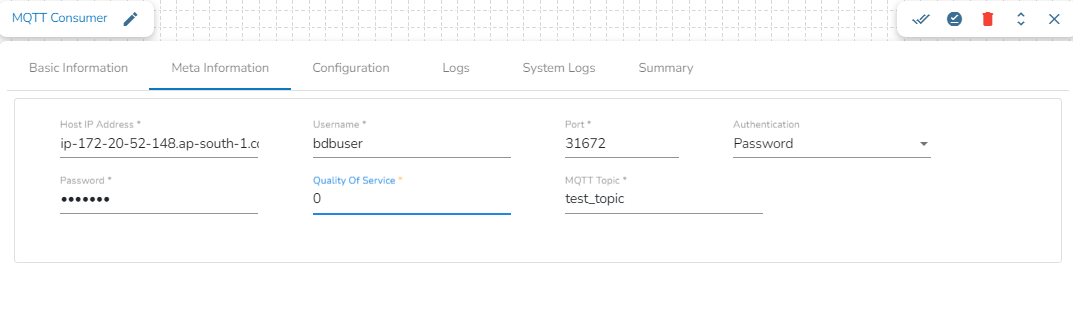
Configuring the Meta Information tab of MQTT Consumer:
Host IP Address: Provide the IP Address of MQTT broker.
Username: Enter the username.
Port: Enter the port for the given IP address.
Authenticator: There are 2 options in it, select any one to authenticate.
Password: Enter the password to authenticate.
PEM/PPK File: Upload the PEM/PPK File to authenticate.
Quality of service(QoS): Enter the values either 0, 1 or 2. The Quality of Service (QoS) level is an agreement between the sender of a message and the receiver of a message that defines the guarantee of delivery for a specific message. There are 3 QoS levels in MQTT:
At most once (0): The minimal QoS level is zero. This service level guarantees a best-effort delivery. There is no guarantee of delivery. The recipient does not acknowledge receipt of the message and the message is not stored and re-transmitted by the sender.
At least once (1): QoS level 1 guarantees that a message is delivered at least one time to the receiver. The sender stores the message until it gets a PUBACK packet from the receiver that acknowledges receipt of the message.
Exactly once (2): QoS 2 is the highest level of service in MQTT. This level guarantees that each message is received only once by the intended recipients. QoS 2 is the safest and slowest quality of service level. The guarantee is provided by at least two request/response flows (a four-part handshake) between the sender and the receiver. The sender and receiver use the packet identifier of the original PUBLISH message to coordinate delivery of the message.
MQTT topic: Enter the name of the MQTT topic from where the messages have been published and to which the messages have to be consumed.
Please Note: Kindly perform the following tasks to run a Pipeline workflow with the MQTT consumer component:
After configuring the component click the Save Component in Storage option for the component.
Update the Pipeline workflow and activate the pipeline to see the MQTT consumer working in a Pipeline Workflow. The user can get details through the Logs panel when the Pipeline workflow starts loading data.
Last updated