
Push & Pull Pipeline
The Version Control feature has been provided for the user to maintain a version of the pipeline while the same pipeline undergoes further development and different enhancements.
The Push & Pull Pipeline from GIT feature are present on the List Pipeline and Pipeline Editor pages.
Pushing a Pipeline into VCS
Navigate to the Pipeline Editor page for a Pipeline.
Click the Push & Pipeline icon for the selected data pipeline.
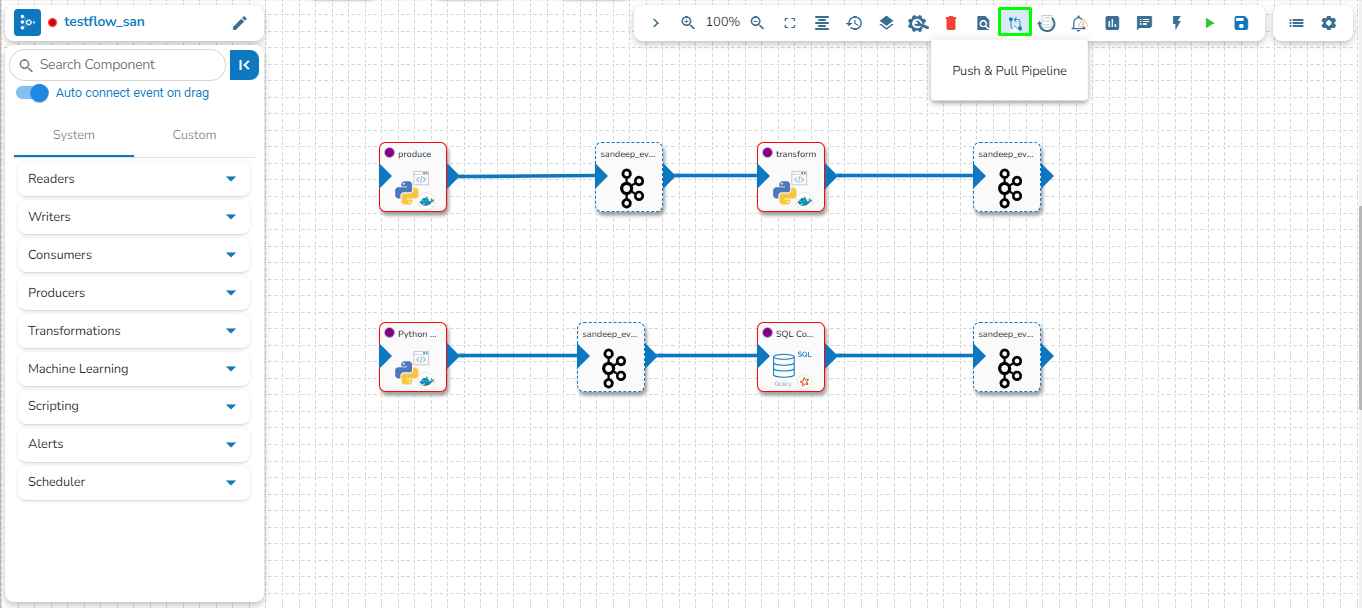
The Push/Pull dialog box appears.
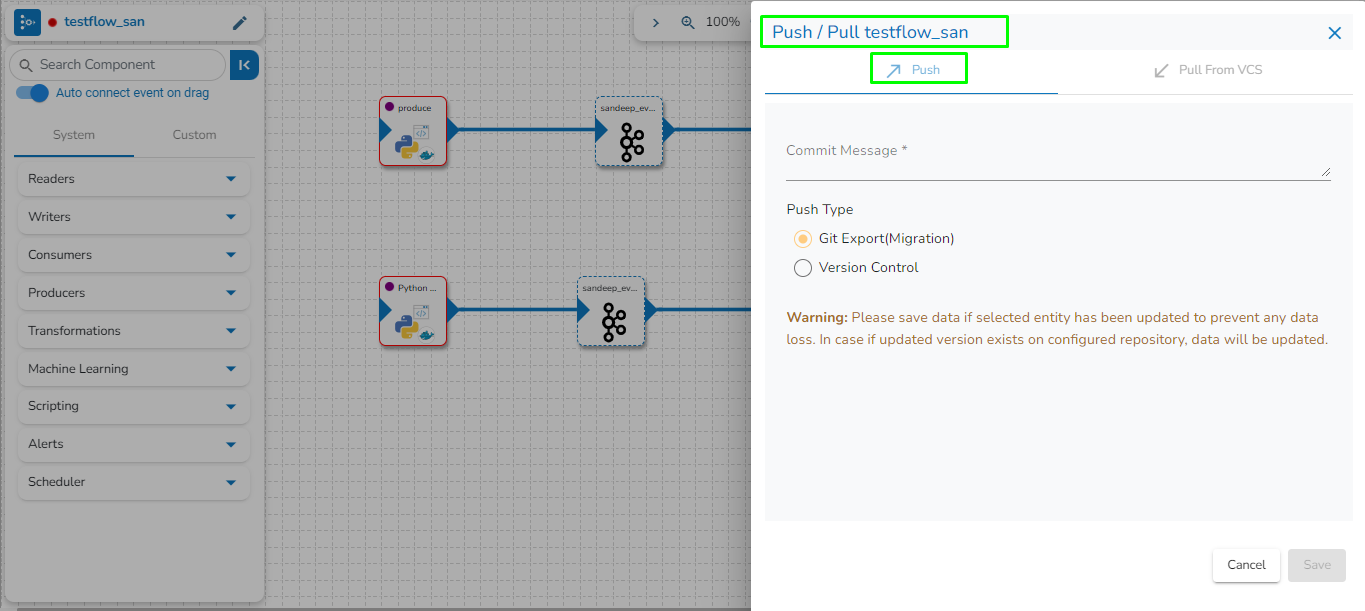
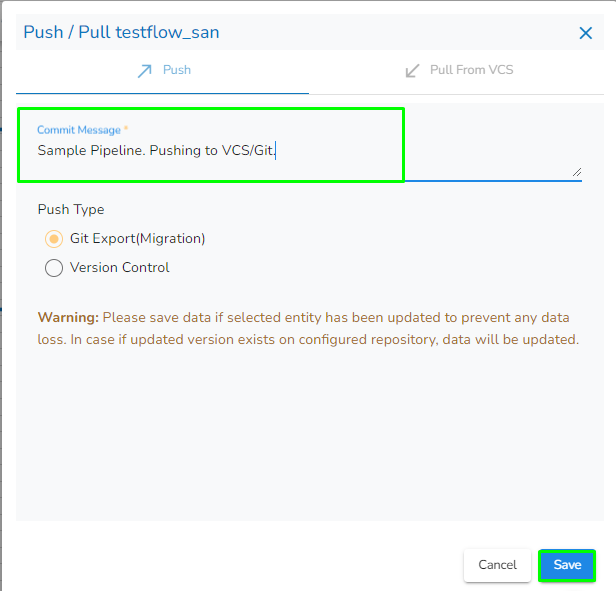
Provide a Commit Message (required) for the data pipeline version.
Select a Push Type out of the below-given choices to push the pipeline:
1.Version Control: For versioning of the pipeline in the same environment.
2.GIT Export (Migration): This is for pipeline migration. The pushed pipeline can be migrated to the destination environment from the migration window in Admin Module.
Click the Save option.
A notification message appears to confirm the completion of the action.

Please Note:
The pipeline pushed to the VCS using the Version Control option, can be pulled directly from the Pull Pipeline from GIT
 icon.
icon.The user also gets an option to Push the pipeline to GIT. This action will be considered as Pipeline Migration.
Pulling a Pipeline
This feature is for pulling the previously moved versions of a pipeline that are committed by the user. This can help a user significantly to recover the lost pipelines or avoid unwanted modifications made to the pipeline.
Navigate to the Pipeline Editor page.
Select a data pipeline from the displayed list.
Click the Push & Pipeline icon for the selected data pipeline.
Select Pull From VCS option.
The Push/Pull dialog box appears.
Select the data pipeline version by marking the given checkbox.
Click the Save option.

A confirmation message appears to assure the users that the concerned pipeline workflow has been imported.

Another confirmation message appears to assure the user that the concerned pipeline workflow has been pulled.

Please Note:
The pipeline that you pull will be changed to the selected version. Please make sure to manage the versions of the pipeline properly.
Refer Migrating Pipeline described as a part of the GIT Migration (under the Administration section) on how to pull an exported/migrated Pipeline version from the GIT.