This page is for the Advanced configuration of the Data Pipeline. The following list of the configurations get displayed on the Settings Page:
Logger
Default Configuration
System Component Status
Data Sync
Job BaseInfo
List Components
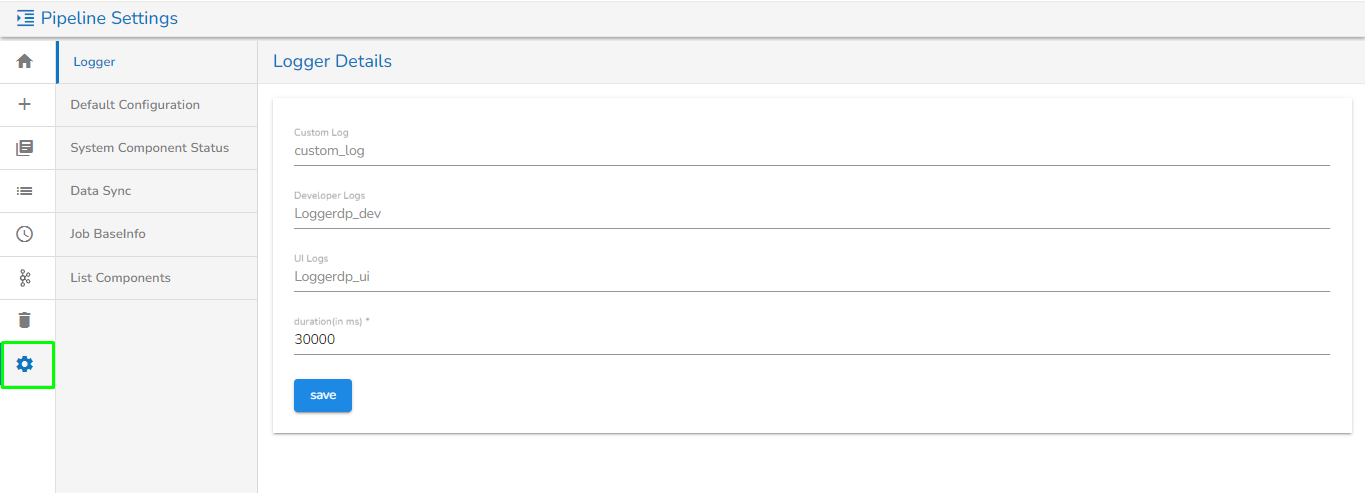
Logger
This gives the info and config details of the Kafka topic that is set for logging.
Logger Configuration
Default Configuration
This page enables users to view or set the default resource configuration in Low, Medium, and High resource allocation types for pipelines and jobs.
Default Configuration Page
To access the Default Configuration, click on the settings option on the pipeline homepage and select it from the settings page.
There will be two tabs on this page:
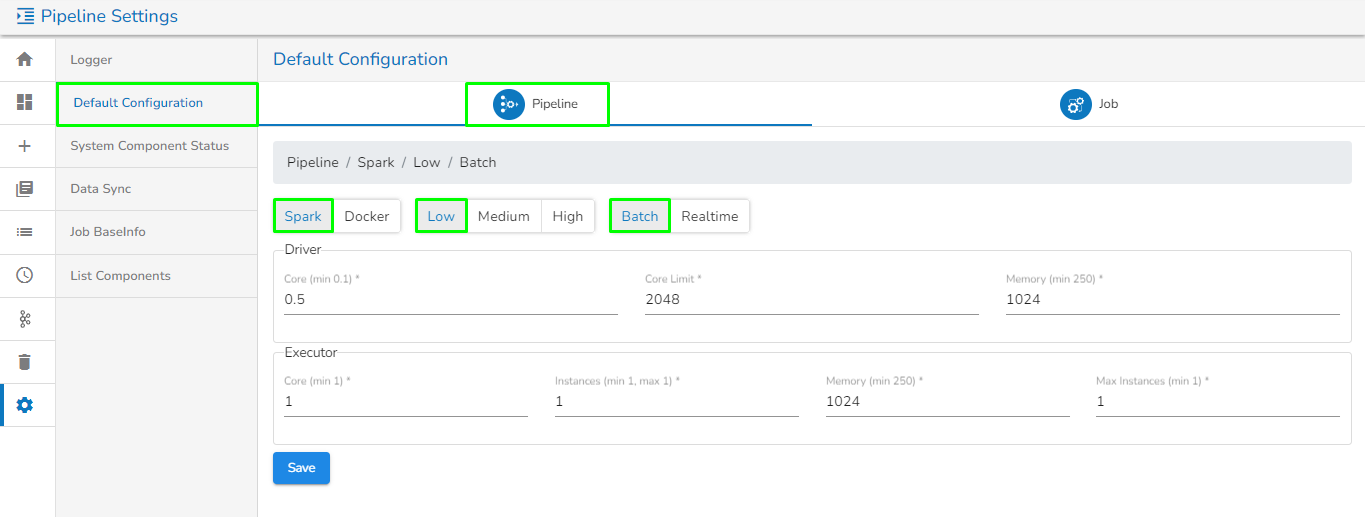
Pipeline: The Pipeline tab opens by default.
This tab shows the default configuration set for Spark and Docker components in different resource allocation types (Low, Medium, High) and in different invocation types such as Real-time and Batch.
Users can change this default configuration as per their requirement, and the same default resource configuration will be applied to newly added components when used in the pipeline.
Default configuration for Spark component in Batch mode with Low as Resource Type
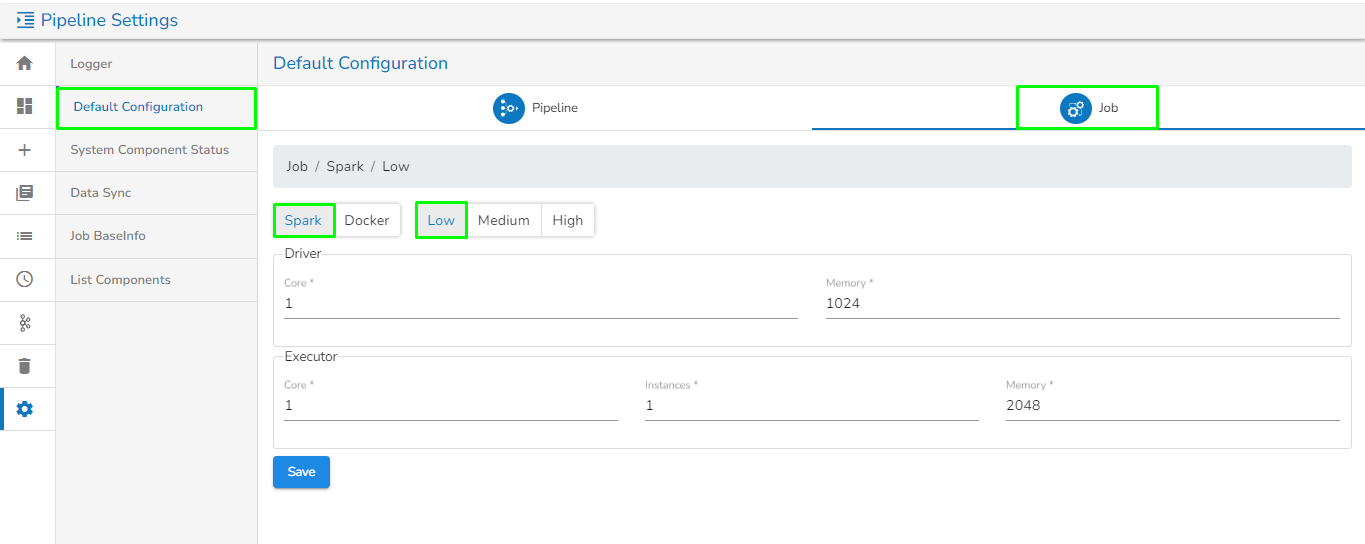
Job: Navigate to this tab to view or set the default configuration for Jobs.
This tab shows the default configuration set for Spark and Docker Jobs in different resource allocation types (Low, Medium, High).
Users can change this default configuration as per their requirement, and the same default resource configuration will be applied to newly created jobs.
Default configuration for Spark job configured with Low resource type
System Component Status
The SystemComponent Status page under the Settings option gives us monitoring capability on the health of the System Components.
System logs are essential for monitoring and troubleshooting systems pods. They provide a record of system events, errors, and user activities. Here’s an overview of key concepts and types of system logs, along with best practices for managing them.
System Component Status
Accessing System Logs
Navigate to the Logger Details page by clicking the Settings icon from the left menu bar.
Click on the System Component Status Tab. The user will navigate to the System Pod Details page.
Click on any one System Pod. The System Logs drawer will open.
Key Features and Functionality
System logs are files that record events and messages from the operating system, applications, and other components.
Search Bar: Users can search the relevant log entries in the search bar.
Time Range Filter: This filter allows users to specify a time frame to view system pod logs. This feature is essential for isolating issues, monitoring performance, or auditing activities over specific periods.
Filter Options: Users get two ways to specify the time range.
Predefined Ranges: Select from the displayed options that include commonly used options like last minutes, last hour, or last days, etc. E.g., the Last 24 hours is selected as a Time Range in the following image.
Custom Range: Users can specify a start and end date/time to filter logs using the Calendar.
Applying a Time Range
Select a time range.
It will be displayed as the selected time range.
Click the Apply Time Range option.
The logs within the selected time range will be displayed. Logs may be displayed in a list format, showing timestamps, log levels, and relevant messages.
Log Formats: Logs can be in plain text format.
Log Levels: Logs are often categorized by severity (e.g., DEBUG, INFO, WARN, ERROR, CRITICAL).
Please Note:
Download Logs: You can download the logs files of the system logs using the Download Logs icon.
Refresh: You can refresh the system log list using the Refresh option.
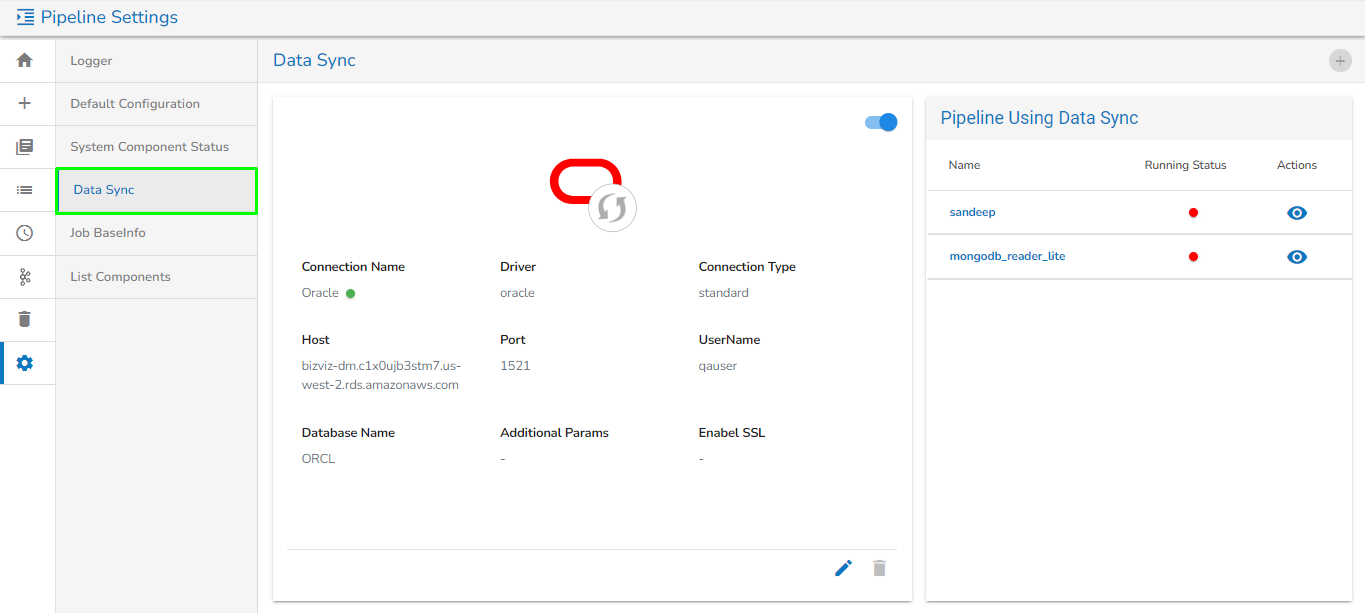
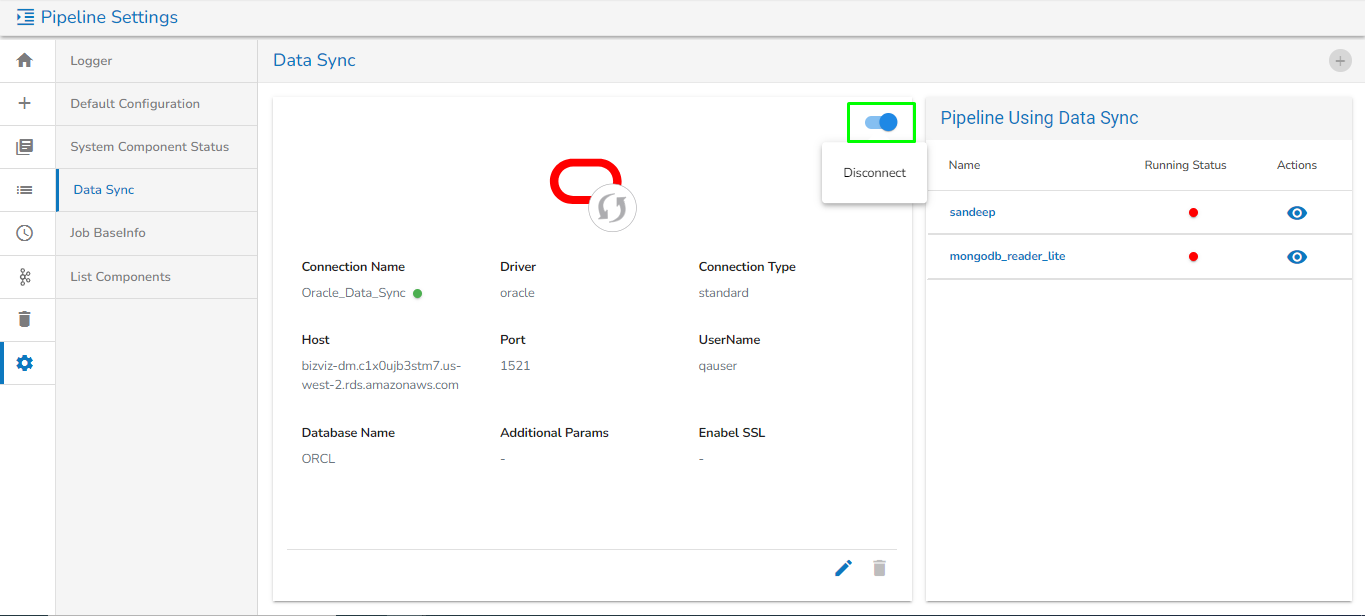
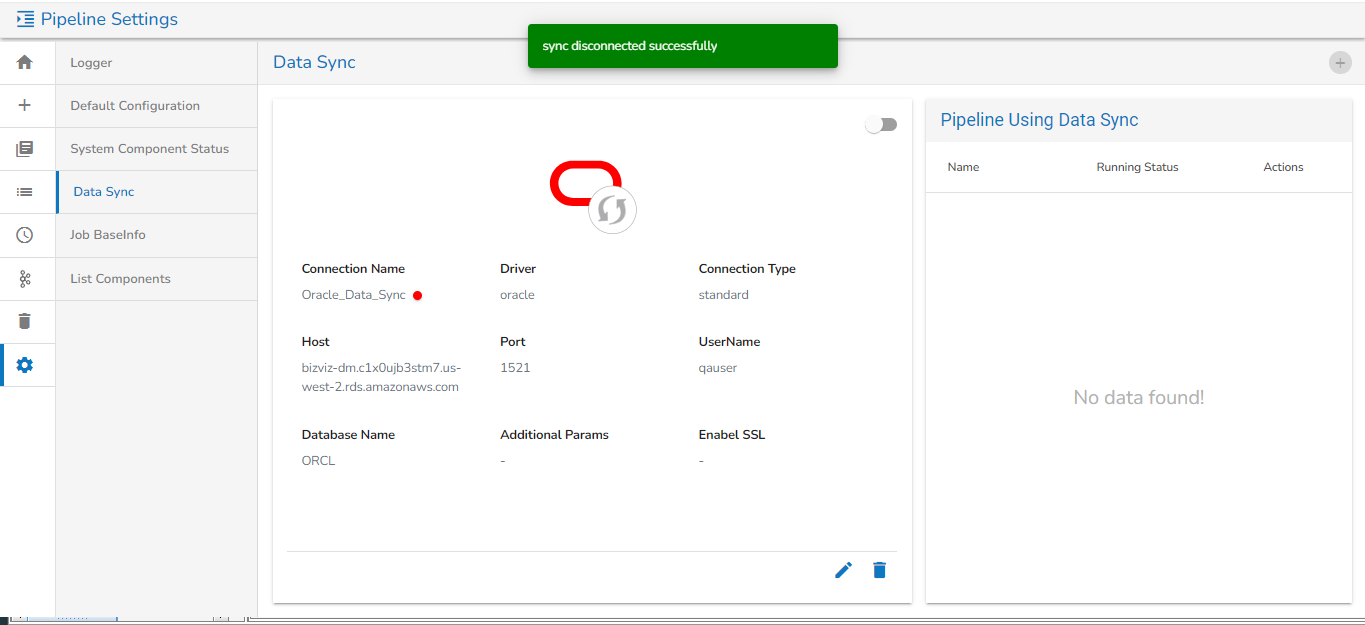
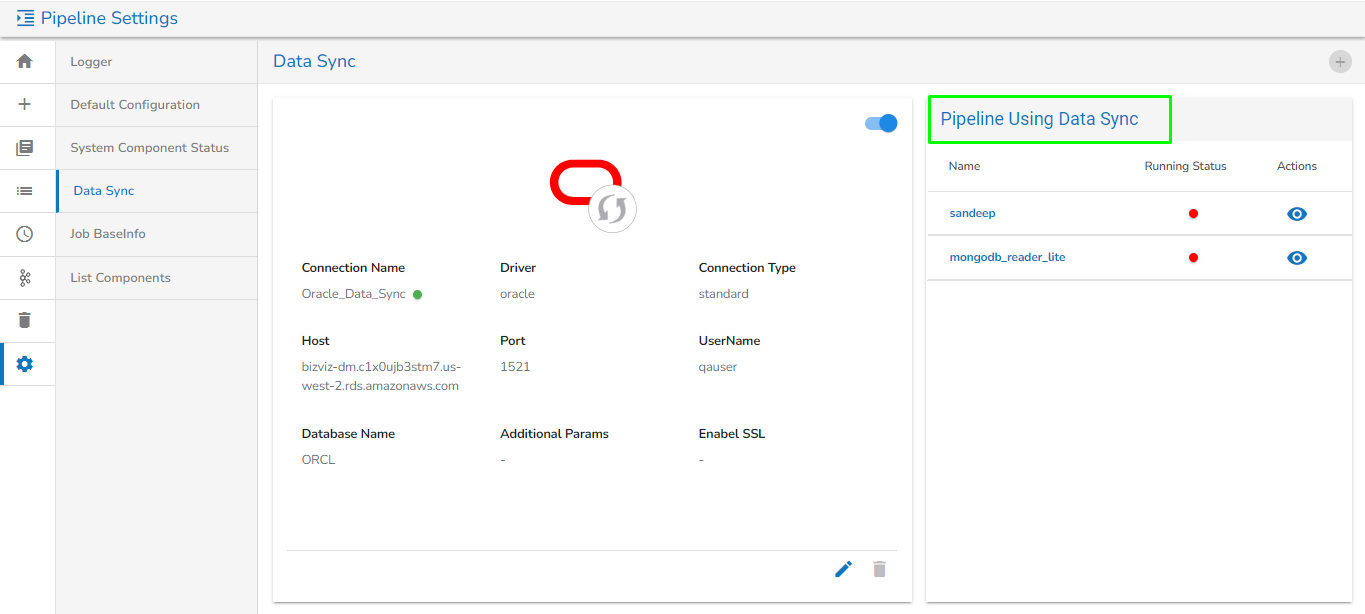
Data Sync
Data Sync in Settings is given to globally configure the Data Sync feature. This way the user can enable a DB connection and use the same connection in the pipeline workflow without using any extra resources.
Data Sync page under the Pipeline Settings option
Please Note:The supported drivers are:
MongoDB
Postgres
MySQL
MSSQL
Oracle
ClickHouse
Snowflake
Redshift
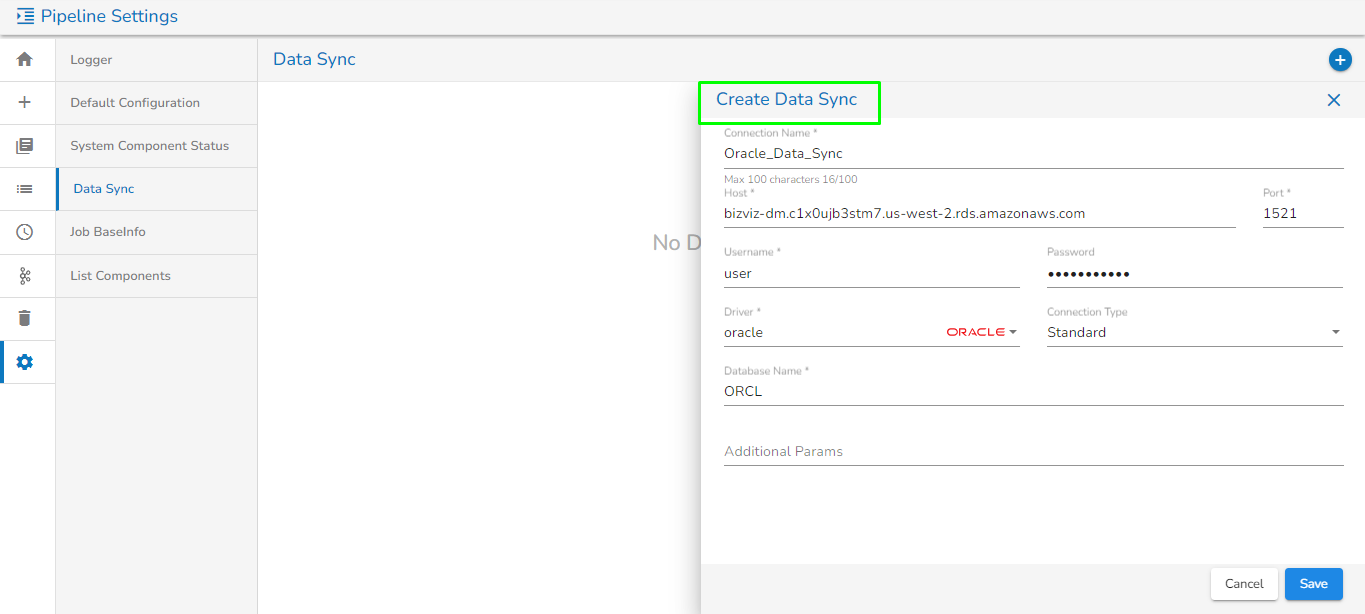
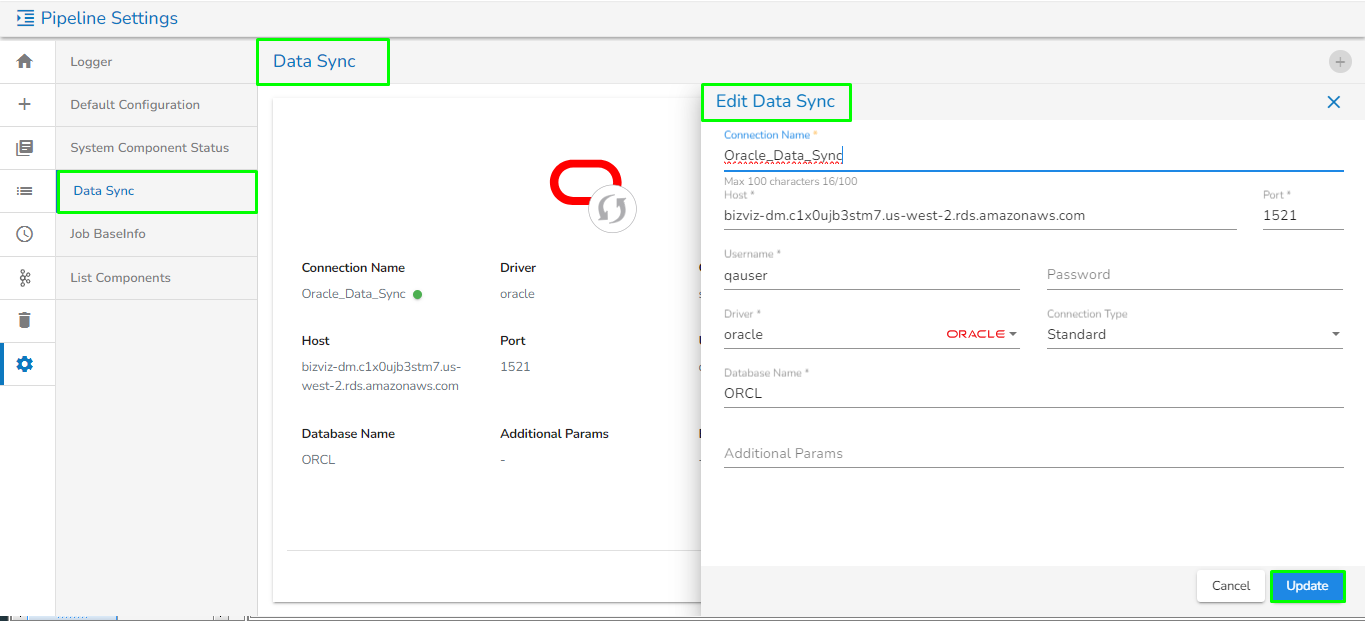
Creating a new Data Sync Connection:
Creating a new data sync connection
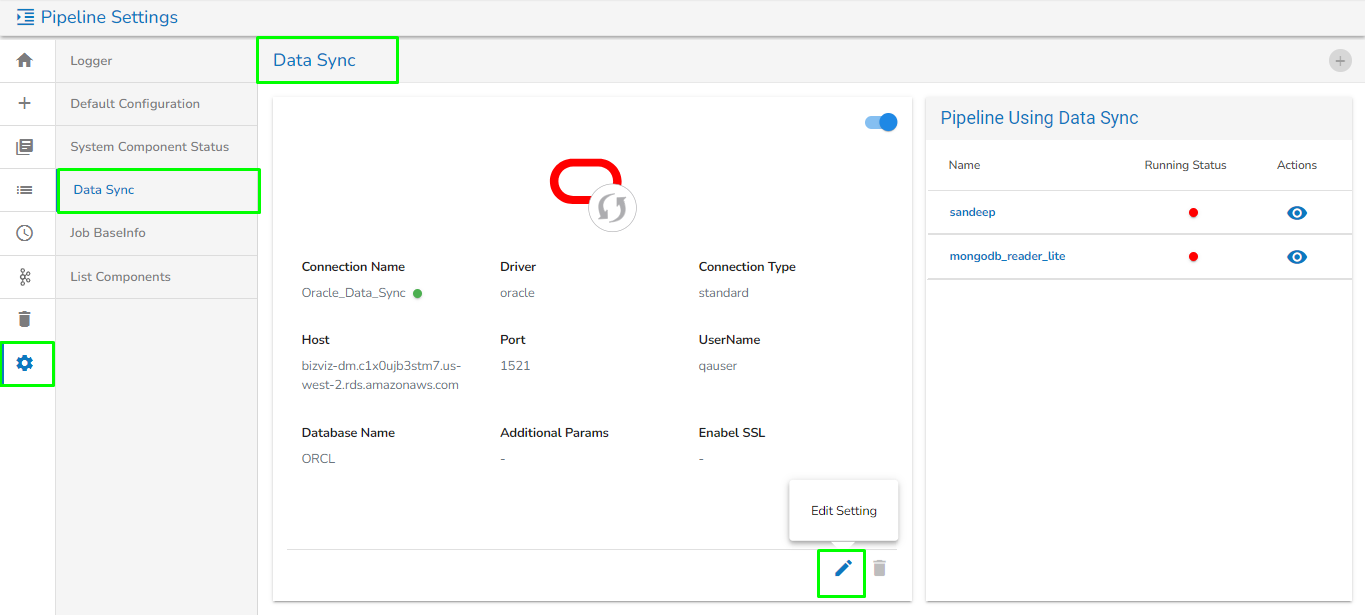
Go to the Settings page.
Click the Data Sync option.
The Data Sync page opens.
Click the Plus icon.
The Create Data Sync Connection dialog box appears.
Specify all the required connection details.
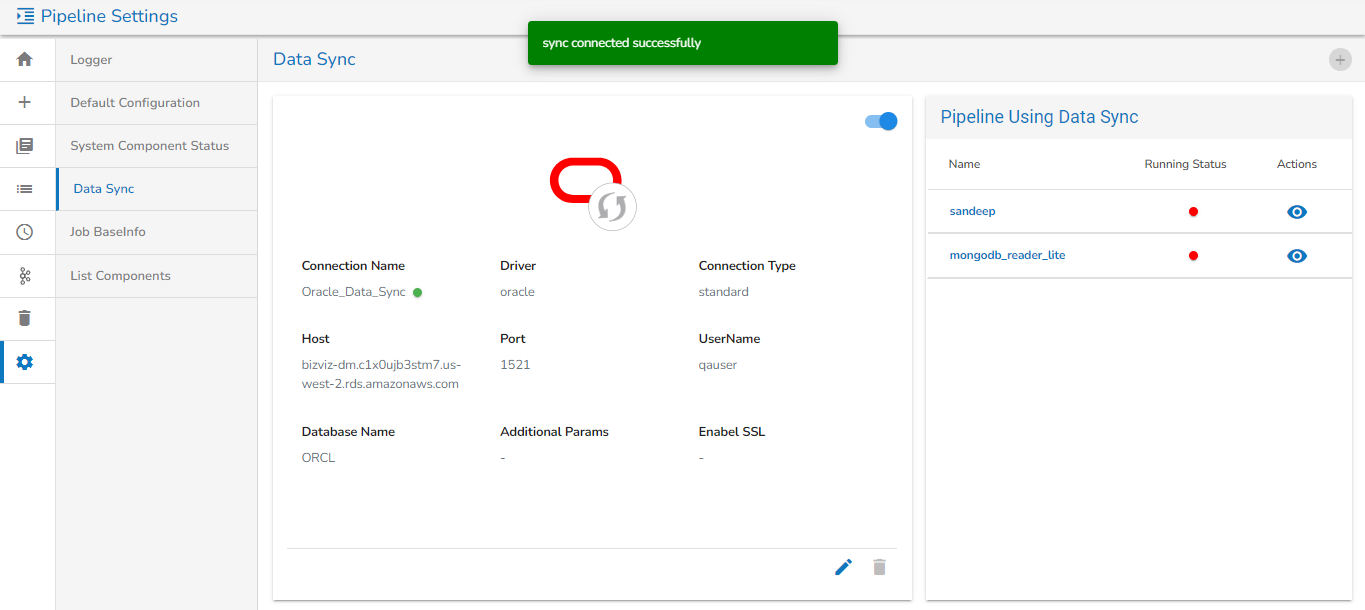
Click the Save option.
Please Note:
Please use TCP Port If you are using ClickHouse as a Driver in Data Sync.
These jobs are configured in the Job BaseInfo page under the Settings menu.
Please Note:The Job BaseInfo has been created from the admin side, and the user is not supposed to create it in the settings menu.
Steps to create a new Job BaseInfo:
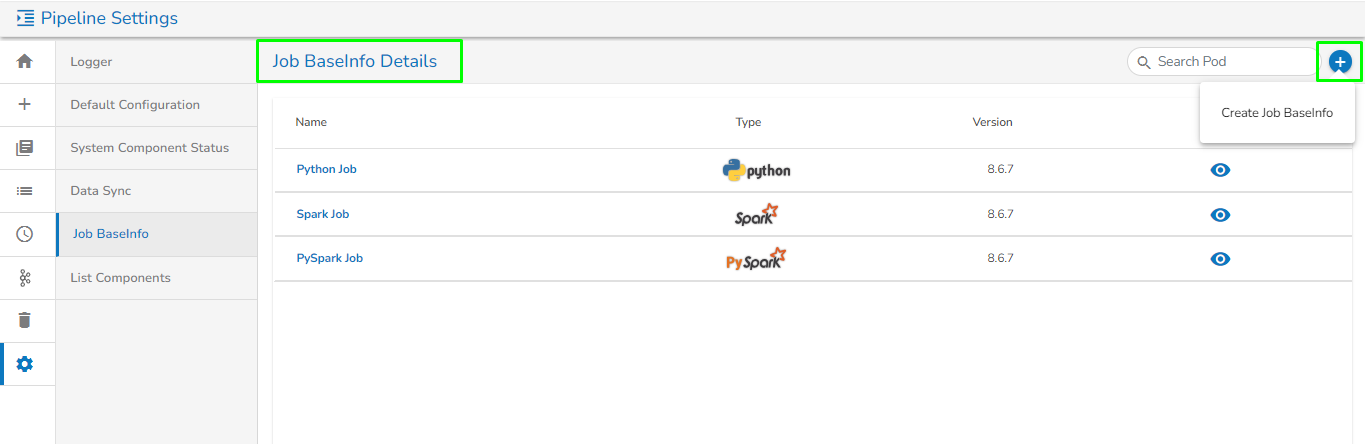
To create a new Job BaseInfo, click on the Create Job BaseInfo option, as shown in the image below:
Create Job BaseInfo
Once clicked, it will redirect to the page for creating a new Job BaseInfo and the user will be asked to fill in details in the following Tabs:
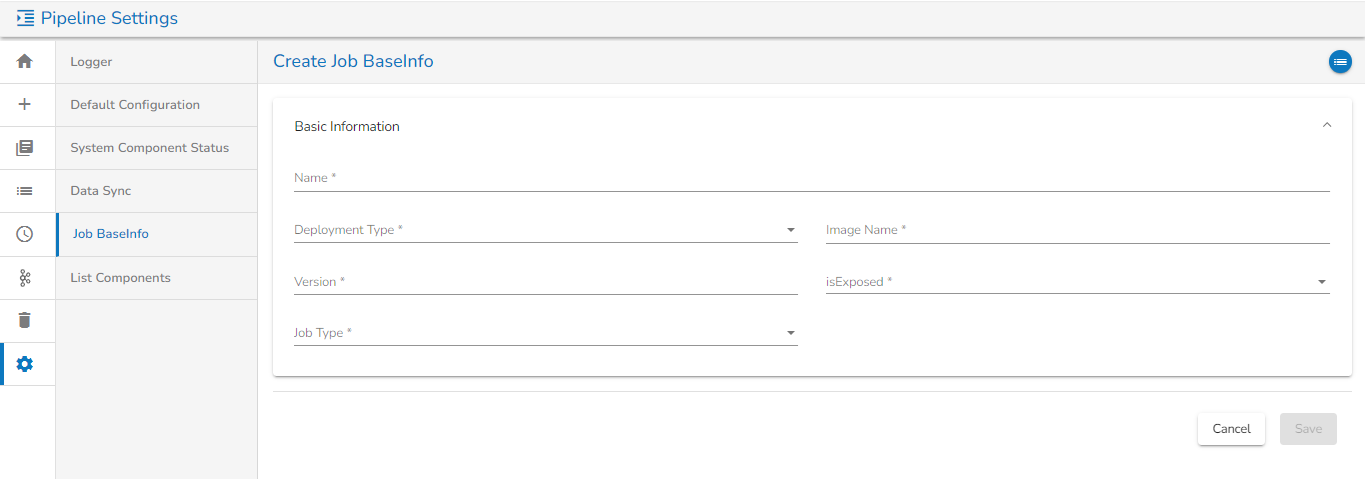
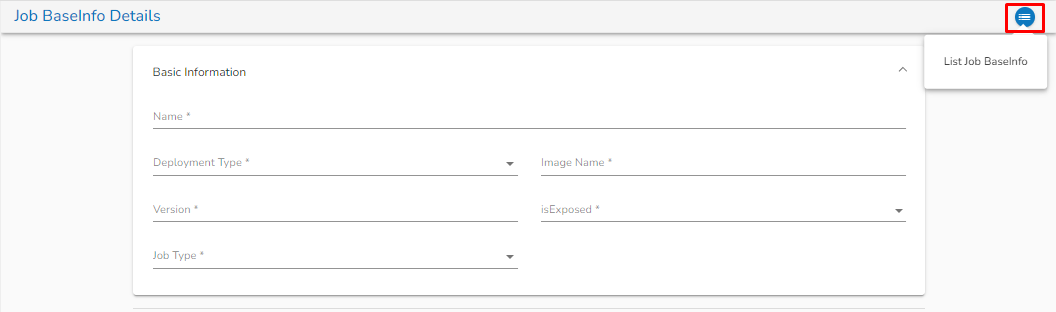
Basic Information Tab:
Basic Information Tab while Creating Job BaseInfo
Name: Provide a Name for the Job BaseInfo.
Deployment type: Select the Deployment type from the drop-down.
Image Name: Enter the Image name for the Job BaseInfo.
Version: Specify the version.
isExposed: This option will be automatically filled as True once the deployment type is selected
Job type: Select the job type from the drop-down.
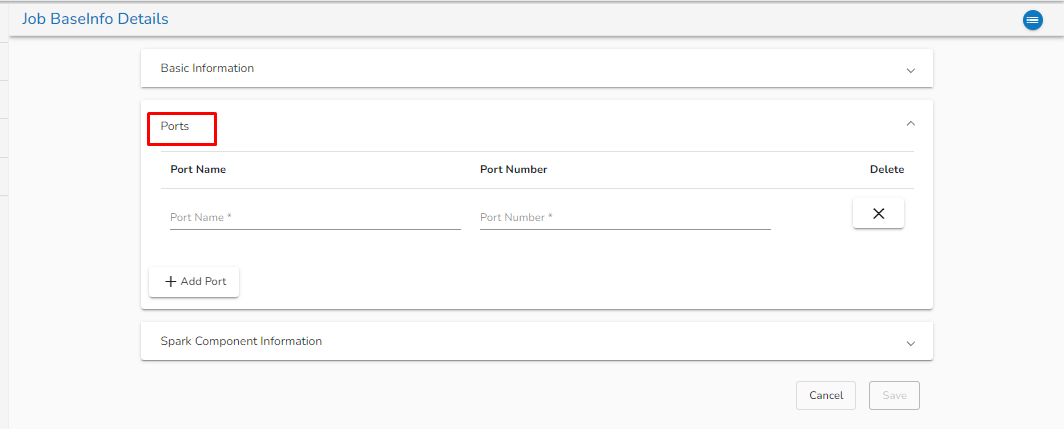
Ports Tab:
Ports Tab
Port Name: Enter the Port name.
Port Number: Enter the Port number.
Delete: The user can delete the port details by clicking on this option.
Add Port: The user can add the Port by clicking on this option.
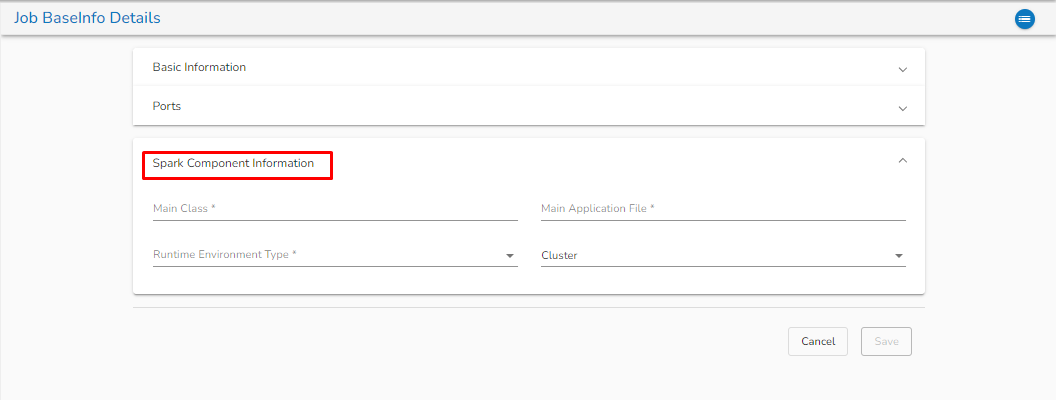
Spark component information:
Main class: Enter the Main class for creating the Job BaseInfo.
Main application file: Enter the main application file.
Runtime Environment Type: Select from the drop-down. There are three options available: Scala, Python, and R.
Now, click on the Save option to create the Job BaseInfo.
Once the Job BaseInfo is created, the user can redirect to the List Job BaseInfo page by clicking on the List Job BaseInfo icon as shown in the below image:
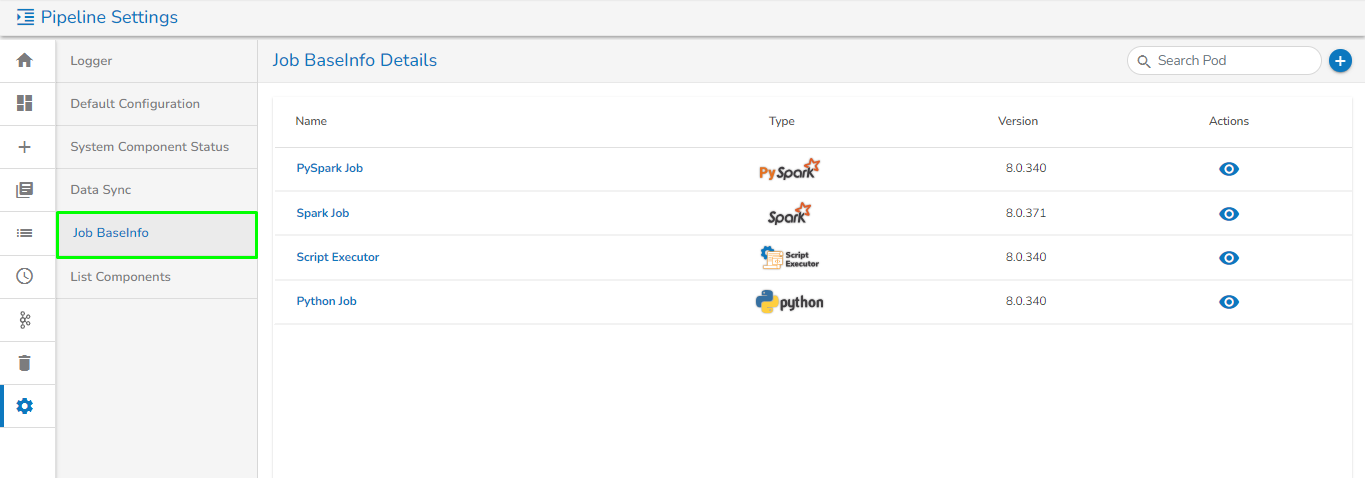
List Job BaseInfo Page:
This Page will show the list of all created Job BaseInfo as shown in the below image:
The Name column represents the Name of the Job BaseInfo.
The Status column will display the status of the Job BaseInfo.
The Version column displays the version of the Job BaseInfo.
The user can see the details of Job Baseinfo by clicking on the View icon. Once clicked on the View icon, the user can see the details of Job BaseInfo provided while creating that Job.
List Components
All the components being used in the pipeline are listed on this page.
Please Note:Please go through the below-given walk-through for the list components page.
List Component Page
There is a provision to create a component. At the top right corner, we have a Create Component icon. Clicking on this takes you to a different page where you can configure your component.
Creating a system Component
Check out the steps in the below-shared walk-through to configure the custom component.
Creating a custom component
Please Note: You should have your docker image created and stored in the docker repository where all other pipeline components are present. Little Help from DevOps will be required to push those images.








 icon. Once clicked on the View icon, the user can see the details of Job BaseInfo provided while creating that Job.
icon. Once clicked on the View icon, the user can see the details of Job BaseInfo provided while creating that Job.