DB Writer
The DB writer is a spark-based writer component which gives you capability to write data to multiple database sources.
All component configurations are classified broadly into the following sections:
Meta Information
Please check out the given demonstration to configure the component.
Drivers Available
Please Note:
The ClickHouse driver in the Spark components will use the HTTP Port and not the TCP port.
It is always recommended to create the table before activating the pipeline to avoid errors as RDBMS has a strict schema and can result in errors.
When using the Redshift driver with a Boolean datatype in JDBC, the table is not created unless you pass the create table query. Alternatively, you can use a column filter to convert a Boolean value to a String for the desired operation.
Configuring the Meta Information of Azure Writer
Database name: Enter the Database name.
Table name: Provide a table name where the data has to be written.
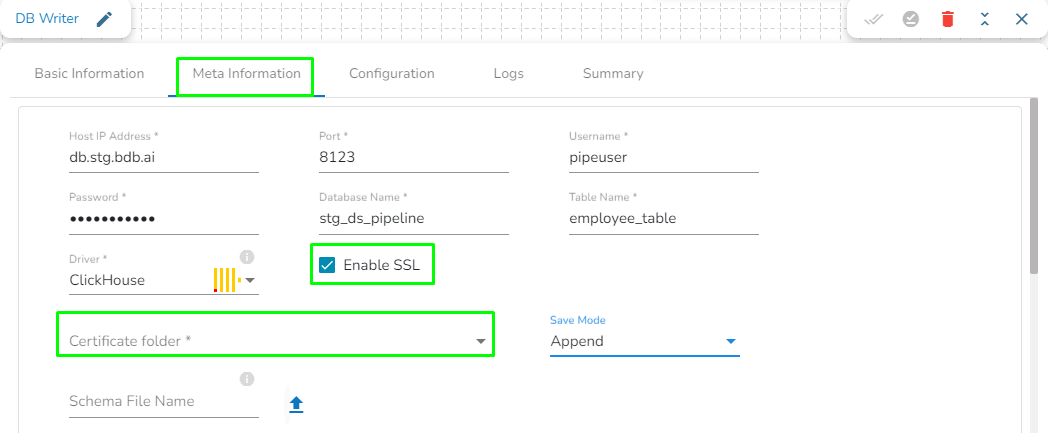
Enable SSL: Check this box to enable SSL for this components. Enable SSL feature in DB reader component will appear only for three(3) drivers: MongoDB, PostgreSQL and ClickHouse.
Certificate Folder: This option will appear when the Enable SSL field is checked-in. The user has to select the certificate folder from drop down which contains the files which has been uploaded to the admin settings. Please refer the below given images for the reference.
Schema File Name: Upload a Spark schema file of the data which has to be written in JSON format.
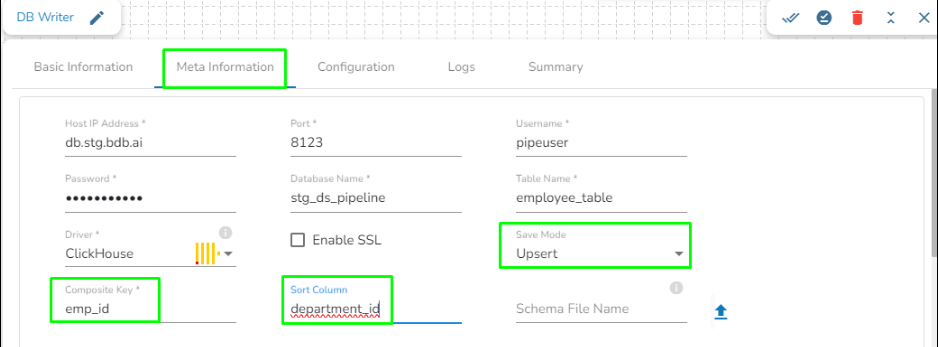
Save Mode: Select the save mode from the drop-down menu:
Append: It will append the data in the table.
Overwrite: It will overwrite the data in the table.
Upsert: This operation allows the users to insert a new record or update existing data into a table. For configuring this, we need to provide the Composite Key.
Sort Column: This field will appear only when Upsert is selected as Save mode. If there are multiple records with the same composite key but different values in the batch, the system identifies the record with the latest value based on the Sort column. The Sort column defines the ordering of records, and the record with the highest value in the sort column is considered the latest.
Column Filter: Enter the column names here. Only the specified columns will be fetched from the data from the previous connected event to the DB Writer. In this field, the user needs to fill in the following information:
Name: Enter the name of the column which has to be written from the previous event. The user can add multiple columns by clicking on the "Add New Column" option.
Alias: Enter the alias name for the selected column name.
Column Type: Enter the data type of the column.
Upload: This option allows the user to upload a data file in CSV, JSON, or EXCEL format. The column names will be automatically fetched from the uploaded data file and filled out in the Name, Alias, and Column Type fields.
Download Data: This option will download the data filled in the Column Filter field in JSON format.
Delete Data: This option will clear all the information filled in the Column Filter field.
Query: In this field, we can write a DDL for creating the table in database where the in-event data has to be written. For example, please refer the below image:
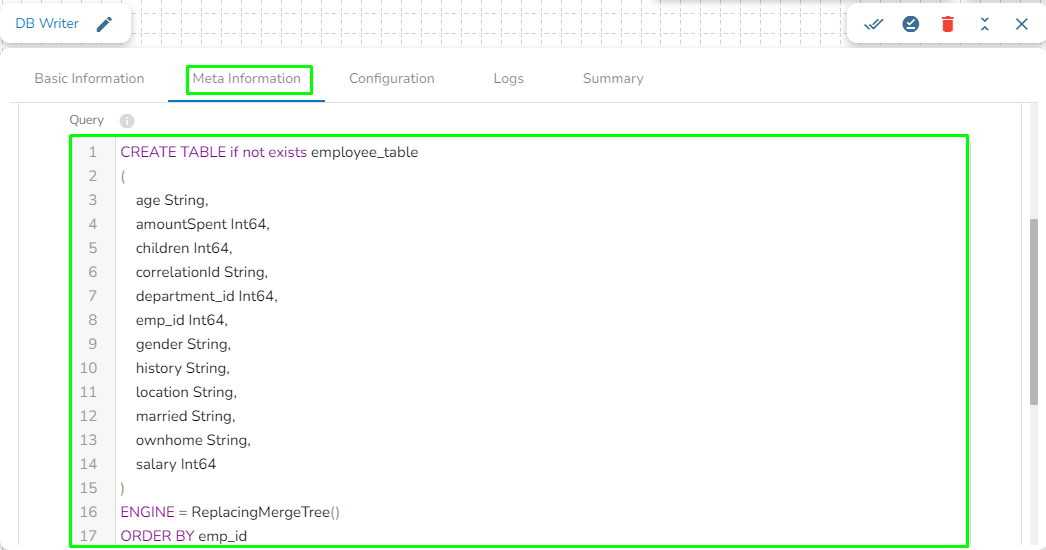
Please Note:
In DB Writer component, the Save Mode for ClickHouse driver is as follows:
Append: It will create a table in ClickHouse database with a table engine StripeLog.
Upsert: It will create a table in ClickHouse database with a table engine ReplacingMergeTree.
If the user is using Append as the Save mode in ClickHouse Writer (Docker component) and Data Sync (ClickHouse driver), it will create a table in the ClickHouse database with a table engine Memory.
Currently, the Sort column field is only available for the following drivers in the DB Writer: MSSQL, PostgreSQL, Oracle, Snowflake, and ClickHouse.