Homepage
Default Homepage
It is the default landing page while selecting the Data Pipeline module. The Homepage of the Data Pipeline is a page that opens by default when you select the Data Pipeline module from the Apps menu.
Navigate to the Platform homepage.
Click on the Apps menu to open it.
Click on the Data Pipeline module.
You get redirected to the Homepage of the Data Pipeline module.
The Homepage of the Data Pipeline module offers a left-side menu panel with various options to begin with the Data Pipeline module.
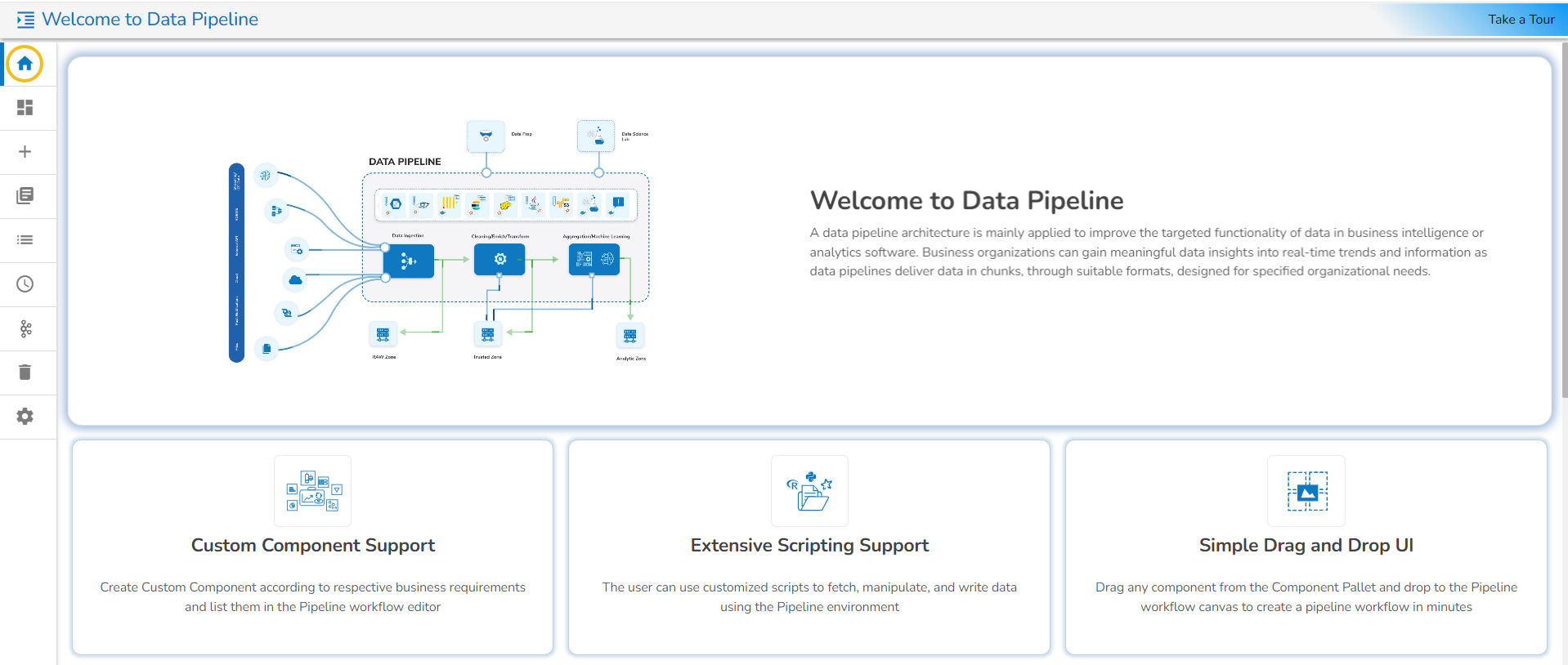
Various options provided on the left-side menu panel given on the Data Pipeline Homepage are as described below:
![]()
Home
Redirects the Pipeline Homepage.
![]()
Redirects to the page containing the information on Data Channel & Cluster Events.
Recently Visited
The Recently Visited section provides users with instant access to their most recent pipelines or jobs, displaying the last ten interactions. By eliminating the need to search through extensive menus or folders, this feature significantly improves workflow efficiency. Users can quickly resume work where they left off, ensuring a more seamless and intuitive experience on the pipeline homepage. It’s especially valuable for users managing multiple pipelines, as it reduces repetitive tasks, shortens navigation time, and increases overall productivity.
How to Access Recently Visited Pipelines or Jobs
Navigate to the Data Pipeline Homepage.
Locate the Recently Visited section on the Homepage.
You may review the list of recent items to find the one you wish to access.

Select a Pipeline or Job from the list.
Click on the View icon of the desired pipeline or job.

You will be redirected to the Workflow Editor page of the selected Pipeline or Job.

Last updated