
String
Add Prefix
The Add Prefix transform allows you to effortlessly incorporate custom text at the outset of each value. The seamless integration of personalized text at the beginning of each value empowers you to enhance and customize your data in a user-friendly manner.

Steps to perform the Add Prefix transformation:
Select the Transforms tab.
Open the Add Prefix transform from the Column category.
Pass the prefix value that is needed.
Select one or multiple columns where the prefix needs to be added.
Result will come as a new column or on the same column by adding the prefix value on the selected columns.
Add Suffix
The implementation of the Add Suffix transform enables the effortless inclusion of custom text at the end of every value. This transformative technique offers a user-friendly approach to enrich and modify the original data, allowing for the seamless integration of personalized text at the end of each value. By leveraging the flexibility of the Add Suffix transform, you can tailor and enhance your data with ease, ensuring it aligns perfectly with your specific requirements and desired outcomes.
Steps to perform the Add Suffix transformation:
Select the transform.
Select the Create a New Column (Optional).
Pass the suffix value that is needed.
Select one or multiple columns where the suffix to be added.
Result will come as a new column or on the same column by adding the suffix value on the selected columns.

Change to Lowercase
The Change to Lowercase transform converts the values from the selected column into lowercase. This transform can either replace the existing column value entirely or be added as a new column alongside the original data. This flexibility allows for seamless integration and customization of the transformed values within your dataset, giving you the option to either update the existing column or introduce a new column with the lowercase representation of the data.
When the Change to lower case transform is applied on the Source column,

The Source column gets displayed in the lower case:

Change to Title Case
The Change to Title Case transform converts the selected column value into title case, resulting in a transformed value where the first letter of each word is capitalized. This transformed value can either replace the existing column value or be added as a new column within the dataset. This flexibility empowers you to smoothly incorporate the title case representation of the data, allowing for enhanced readability and consistency.
The Change to Title Case transform is applied to the Source column,

the Source values get changed into the title case:

Change to Upper Case
The Change to Upper Case transform is a data manipulation operation that converts the selected column value to capital letters. This transformation can be applied in two ways: by replacing the existing column value or by adding the transformed value as a new column.
The Change to Upper Case transform is applied to the Source column by creating a new column,

A new column gets created with the values mentioned in Upper case:

Convert Values To Column
Each unique value in the original column will be represented by a separate column, and the presence or absence of that value will be indicated by a binary value (0 or 1) in the corresponding column.
Steps to perform the transformation:
Select the Column which is required to convert.
Select the transform.
Result will come as new columns for every unique value in a column.

Please Note: It is advisable to use columns with Categorical variables/ with String data type to apply the Convert Values to Column transform.
Extract Substring at Position
The Extract Substring at Position transform allows you to extract a portion of a selected column based on the starting position and the length of the substring to be extracted. The transformed value can replace the existing column value or be added as a new column.
Here's how the transform works based on the provided parameters:
Position: The starting position of the substring. It can be a positive or negative number.
If the position is positive, the substring extraction starts from the beginning of the string. For example, if the position is 2, the extraction will begin from the second character.
If the position is negative, the substring extraction starts from the end of the string. For example, if the position is -3, the extraction will begin from the third-to-last character.
Length: (Optional) The number of characters to extract from the string. If omitted, the whole string starting from the given position will be returned.
Let's see an example to better understand the transformation:
Suppose you have a column named "Text" with the value "Hello, World!".
If you apply the substring extraction transform by replacing the existing column value and setting the position to 2, the transformed value will be "ello, World!" because it starts from the second character onward.
If you apply the substring extraction transform by adding a new column and setting the position to -6 and the length to 5, the transformed value in the new column will be "World" because it starts from the third-to-last character and extracts 5 characters.
Keep in mind that the exact implementation of this transformation may vary depending on the data manipulation tool or programming language you are using.
The Extract Substring at Position transform is applied to the expected_joining_date with the 0 position and 7 as length value in the below-given image:

It returns a new column expected_joining_date_extract_substring_1 with the first 7 positions as the split string value is 0.

Extract Substring before Delimiter
The Extract Substring before Delimiter transform allows you to extract a substring from a selected column based on the count of occurrences of a delimiter. It creates a new column that contains the extracted substring.
Here's how the transform works based on the provided parameters:
Delimiter: The character or sequence of characters that separates the substrings in the selected column.
Count: The count of occurrences of the delimiter before which the extraction should happen. This value is mandatory.
Let's look at an example to understand the transformation:
Suppose you have a column named expected_joining_date with values like 2018-06-12. You want to extract only the year from this column.
To achieve this, you can use the Extract Substring Before Delimiter transform with the following parameters:
Delimiter: "-"
Count: 1
By applying this transform, a new column named expected_joining_date_extract_substring_before_delimiter1 will be created. It will contain only the first substring (year) extracted from the original column.
The below given example displays how the Extract Substring before Delimiter transform extracts the first string from the expected_joining_date column and creates a new column.
As a result, the expected_joining_date_extract_substring_before_delimiter1 displaying only the first string (only the year) value before the first delimiter of the selected column.

Get Domain
To extract the domain from a valid URL, you can use the Get Domain transform. This transform allows you to retrieve the domain portion of a URL and can be used to replace the existing column value or add the extracted domain as a new column.
Here's how the Get Domain transform works:
Input: The selected column containing the URLs from which you want to extract the domain.
Output: The transformed value will be the extracted domain, which can replace the existing column value or be added as a new column.
Let's see an example to better understand how this transformation works:
E.g., For the URL: https://www.google.com the extracted Domain value is google.

Get Host
The Get Host transform is designed to extract the host name from a URL, including the subdomains but excluding the path and query parameters. It helps to isolate the host from the complete URL.
Here's an example to demonstrate how the Get Host transform works:
E.g., For the URL: https://www.google.com the extracted Host value is www.google.com.

Get Subdomain Name
To extract the subdomain name from a valid URL, you can use the Get Subdomain Name transform. This transform specifically focuses on extracting the subdomain portion from a URL.
Here's an example to demonstrate how the Get Subdomain Name transform works:
E.g., For the URL: https://www.google.com the extracted Sub-domain Value is www.

Insert Character
The Insert Character transform allows you to insert a specified character after a specified position in a cell value. This transformation can either replace the existing column value or add the modified value as a new column.
Here's how the Insert Character transform works based on the provided parameters:
Position: The position(s) in the cell value after which the character should be inserted. You can specify a single position or multiple positions as comma-separated values.
Character: The character that should be inserted after the specified positions.
Let's see an example to understand the transformation better:
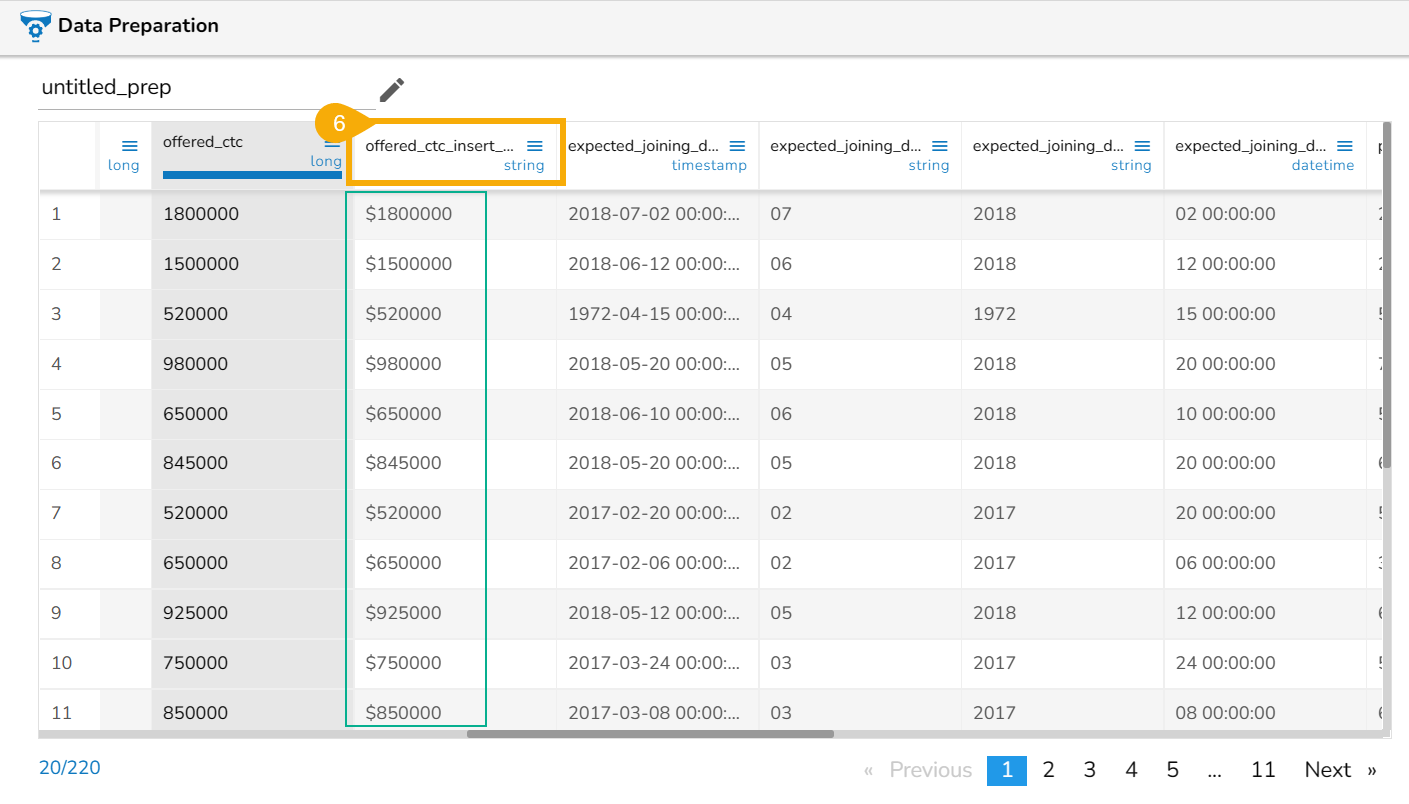
The Insert Character transform has been applied in the below-given column to the offered_ctc column. The selected position is 0 and character to be added is $:

A new column gets added in this case to the dataset with the set configuration for the Insert Character transform:
Is Even
The Is Even transform is a data manipulation operation that checks whether an integer is even or not. It evaluates the given integer and returns a Boolean value indicating whether it is an even number.
Please Note: It returns True for the even number and False for the non-even values.
Steps to perform the transformation:
Select an Integer column.
Select the Is Even transform.
Result will come as a new column if the integer is Even then True else False

Is Odd
The Is Odd transform is a data manipulation operation that checks whether an integer is odd or not. It evaluates the given integer and returns a Boolean value indicating whether it is an odd number.
Steps to perform the transformation:
Select an Integer column.
Select the Is Odd transform.
Result will come as a new column if the integer is Odd then True else False.

Negate Boolean Value
The Negate Boolean Value transform is a data manipulation operation that returns the opposite value of a given Boolean value. It negates or flips the Boolean value from True to False or from False to True.
Please Note: It supports the Boolean column where True/ False values are mentioned.
Steps to perform the Negate Boolean Value transformation:
Select a Boolean column where values are mentioned as True/ False.
Select the Negate Boolean Value transform.
Result will get on the same column where the output is the opposite of the source value.
E.g., if a value was True in Source -> then after applying the Negate Boolean Value transform it would get changed to False and vice versa.

Remove Accents
The Remove Accents transform is a data manipulation operation that helps clean text by removing accented characters. Accented characters are special characters that appear above or below a letter, modifying its pronunciation or meaning in some languages. Removing accents can be useful for tasks such as text normalization or language processing.
Steps to perform the Remove Accents transformation:
Select the transform.
Select the Create a New Column.
Select one or multiple columns where the accents need to be cleaned.
Result will come as a new column by cleaning all the accented characters.

Remove Consecutive Characters
The Remove Consecutive Characters transform is a data manipulation operation that removes repeated whitespace or characters from a selected column. It modifies the selected source column by removing the repetition or adds the modified result as a new column.
Here's how the Remove Consecutive Characters transform works based on the provided parameters:
Separator: This parameter specifies whether the transform should search for repeated whitespace or other characters. If "whitespace" is selected, the transform searches for multiple consecutive whitespace characters and returns a single-spaced value. If "other" is selected, the transform allows you to specify a custom repeated character.
Custom Repeated Character: This parameter is applicable only when "other" is selected as the separator. It allows you to specify the character whose consecutive occurrence must be searched and removed.
Submit: Click the Submit option to apply the transform specification to the selected column.
The Remove consecutive characters transform is applied to the current_status column in the below-given image:

The consecutive character 'r' gets removed from the cells that contain the value 'Transferred'. It returns a new column auto-named as current_status_remove_consecutive_character_1 column as shown below:

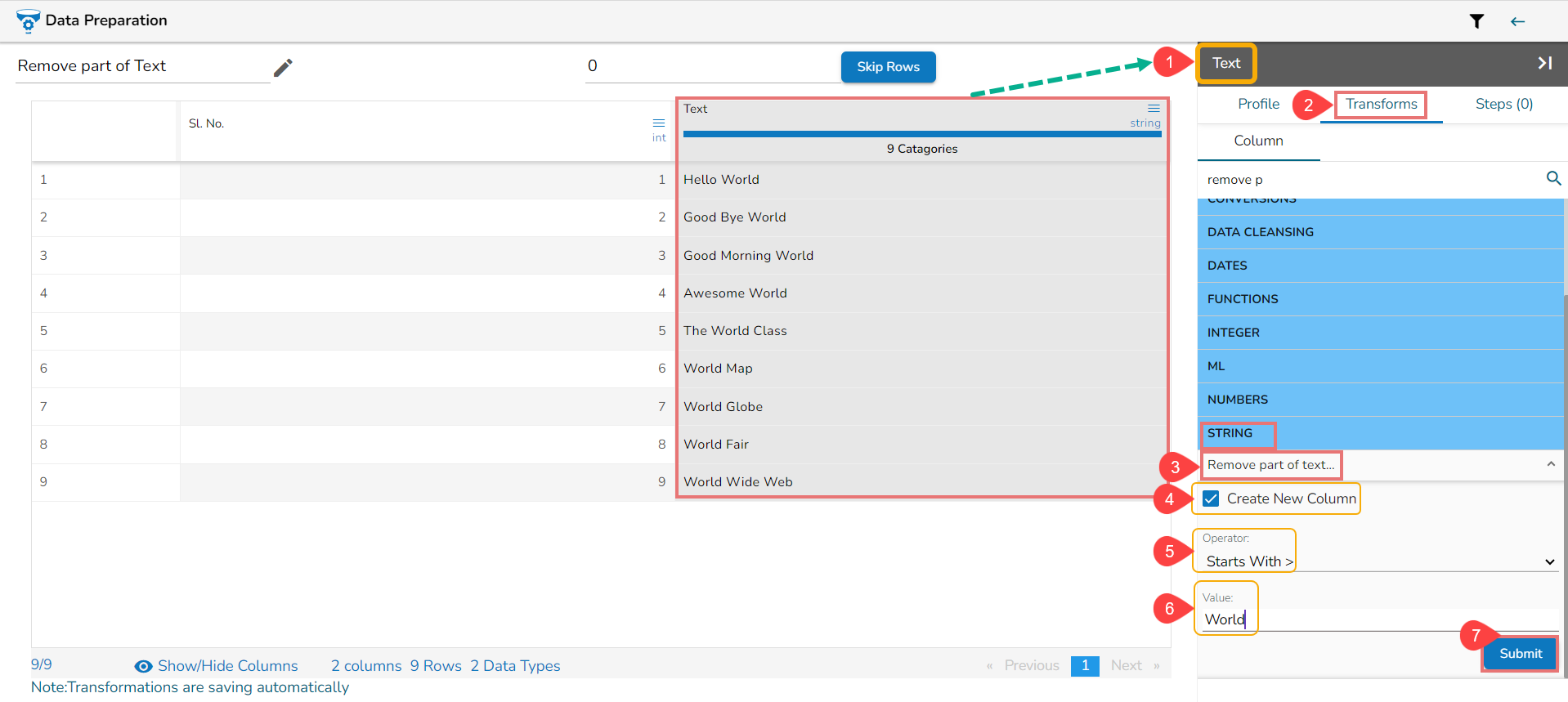
Remove Part of Text
The Remove Part of Text transform is a data manipulation operation that matches and removes a specific part or the entire value from a selected column based on a given condition. This transformation can be used to replace the existing column value or add the modified value as a new column.
Select a column containing some text in the Dataset.
Open the Transforms tab.
Search and Select the Remove Part of Text.
Create New Column: Enable this option to create a new column.
Operator: Select the operator required for matching the text from the list. The supported operators are contains, equals, starts with, ends with, regex.
Value: The value or pattern to be searched for in the selected text/ string column.
Submit: Click the Submit option to apply the transform.
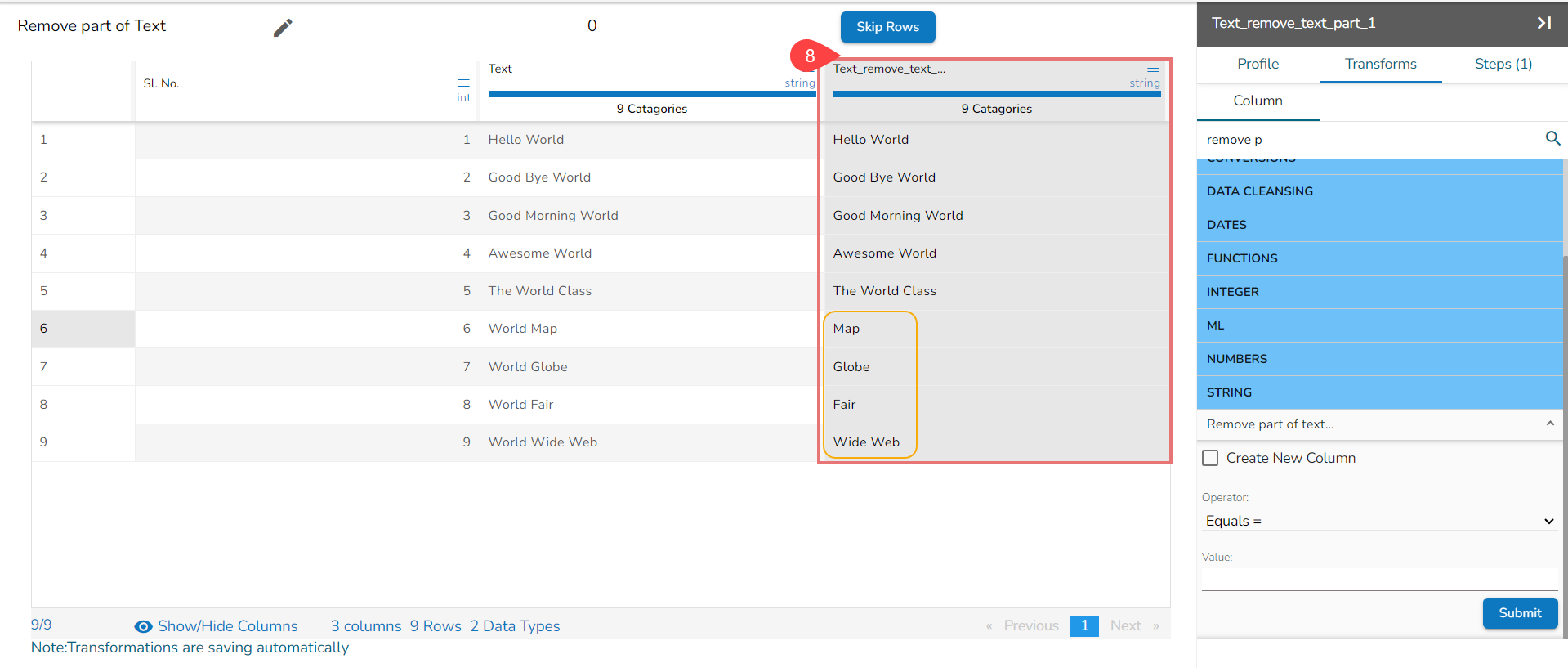
Based on the selected value the part of the text will get removed in the newly added column.
Remove Trailing and Leading Characters
The Remove Trailing and Leading Characters transform is a data manipulation operation that removes leading and trailing characters from a selected column. This transformation can replace the existing column value or add the modified value as a new column.
Here's how the Remove Leading and Trailing Characters transform works based on the provided parameters:
Padding Character: This parameter allows you to specify whether to remove whitespace or another character from the leading and trailing positions of the column values. You can choose the desired option from the drop-down menu.
Custom Padding Character: This parameter is applicable only when other is selected as the padding character. It allows you to specify the specific character to be removed from the leading and trailing positions.
Submit: Click the Submit option after providing the required fields.
By applying the transform and specifying the desired parameters, the leading and trailing characters, including whitespace or a custom character, are removed from the selected column, or the modified data gets added as a new column.
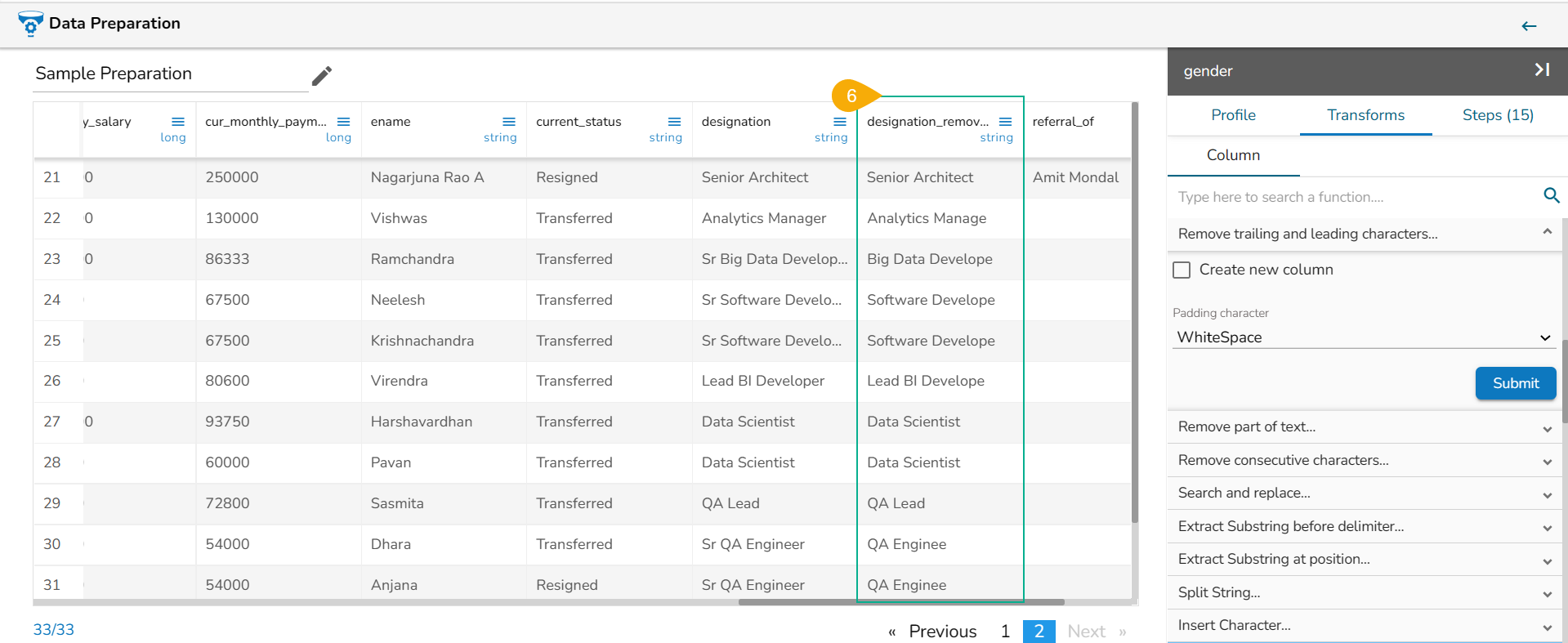
The Remove Trailing and Leading Characters transform is applied on the designation column where the preface 'Sr' custom padding is set to be removed from the new column,

A new column with designation values gets added without the 'Sr' prefix:
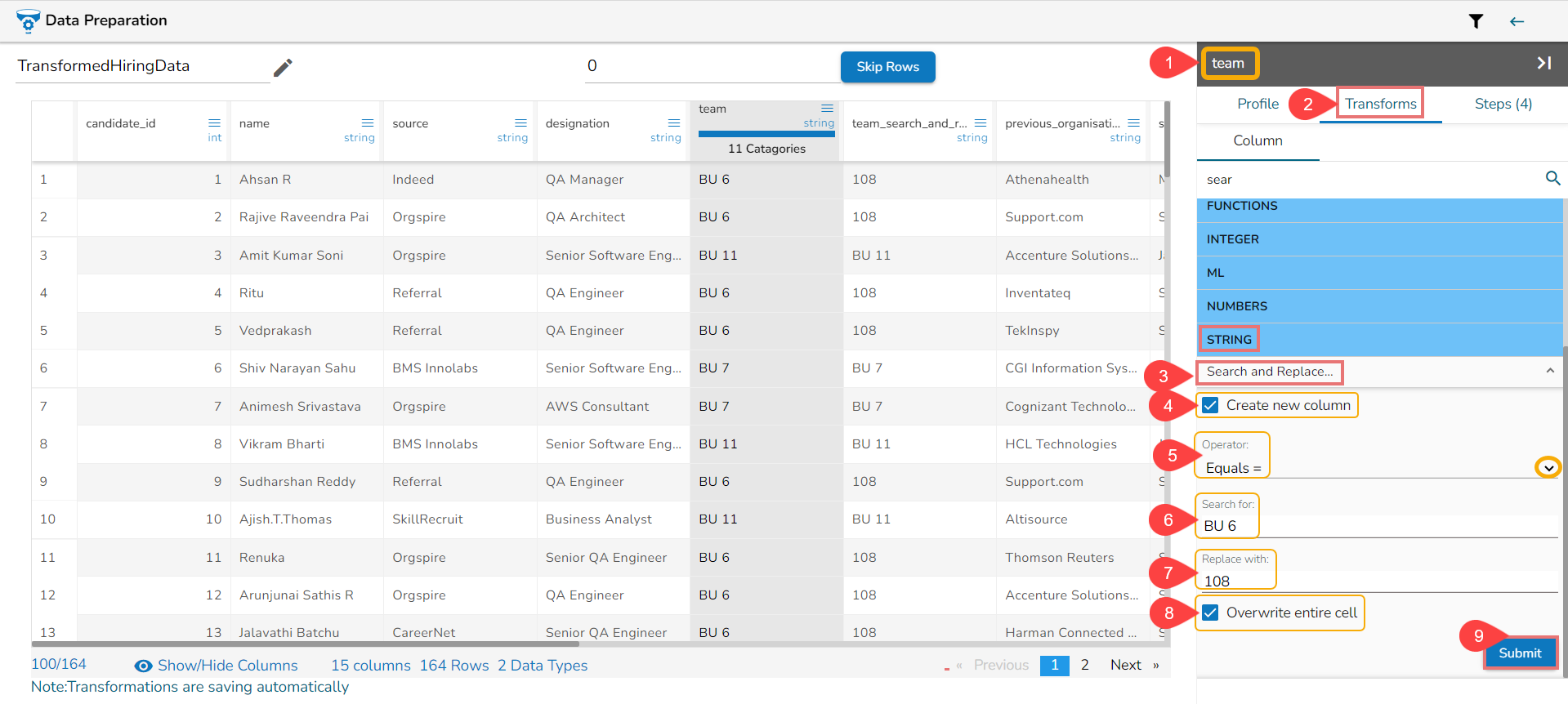
Search and Replace
The Search and Replace transform is a data manipulation operation that searches for a matching part or the entire value in a selected column and replaces it based on the chosen option. This transformation can replace the existing column value or add the modified value as a new column.
Here's how the Search and Replace transform works based on the provided parameters:
Operator: Select the operator required for matching from the provided list. The available operators typically include "contains," "equals," "starts with," "ends with," and "regex match." Each operator determines the matching criteria for the search.
Value: Specify the value or pattern to be searched for in the selected column. The value you provide will be used in conjunction with the selected operator to identify the matching part or value.
By applying the transform and providing the necessary parameters, the matching part or the entire value will be replaced in the selected column or added as a new column.
Steps to apply Search and Replace transform:
Select a column from the displayed Dataset using the Data Preparation grid.
Open the Transforms tab.
Select Search and Replace transform from the STRINGS category.
Use the checkmark to create a new column.
Select an operator using the drop-down icon.
Provide a specific value to be Searched for from the selected column.
Provide a specific value to be replaced with for the searched value.
Use the checkbox to enable overwrite entire cell option.
Click the Submit option.
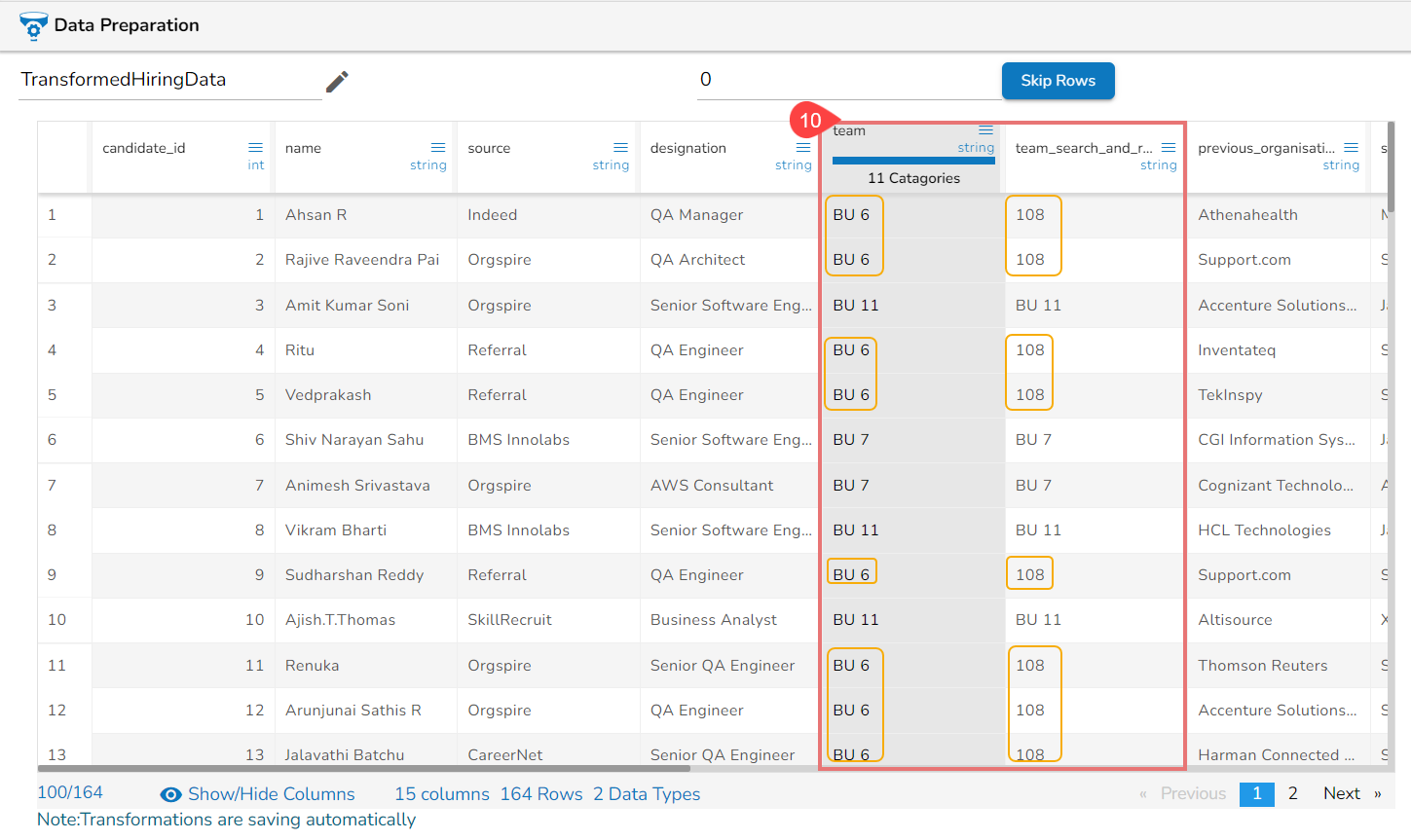
The Search and Replace transform gets applied to the provided value and a new column gets added with the modified data as per the selected Replace with value.
Split String
The Split String transform is a data manipulation operation that splits a string based on a specified condition. It creates new columns based on the number of occurrences of the delimiter or at a specific position.
Here's how the Split String transform works based on the provided parameters:
Use With: This parameter allows you to specify whether the split should happen using a delimiter or at a specific position.
Delimiter: If you select "Delimiter" as the option for "Use With," you need to specify the separator on which the split should occur. The string will be split into multiple parts whenever the delimiter is encountered.
Position: If you select "Position" as the option for "Use With," you need to specify the position after which the split should occur. The string will be split into two parts, with the split happening at the specified position.
By applying the transform and providing the necessary parameters, the string will be split based on the chosen condition, resulting in new columns based on the number of delimiter occurrences or at a specific position.
Here splitting of the column is done based on Delimiter. The applied Separator is '-' and the selected splitting rule is first 3 no. of fields.
Select a column from the Data Preparation grid view.
Open the Transform tab.
Select the Split String transform from the String category.
Provide the required parameters:
Use With: Select Delimiter or Position as an option. Please note that based on the selected option, the next field will appear.
Click the Submit option.

The values from the expected_joining_date get splitted in 3 columns as displayed below:

Last updated