
Python Job
Write Python scripts and run them flawlessly in the Jobs.
This feature allows users to write their own Python script and run their script in the Jobs section of Data Pipeline module.
Before creating the Python Job, the user has to create a project in the Data Science Lab module under Python Environment. Please refer the below image for reference:
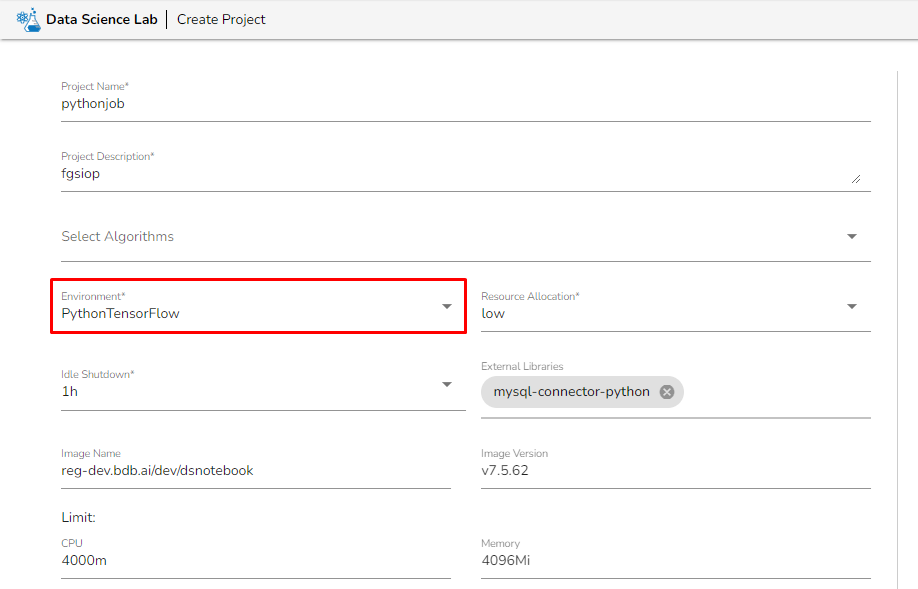
After creating the Data Science project, the users need to activate it and create a Notebook where they can write their own Python script. Once the script is written, the user must save it and export it to be able to use it in the Python Jobs.
Creating a Python Job
Navigate to the Data Pipeline module homepage.
Open the pipeline homepage and click on the Create option.

The new panel opens from right hand side. Click on Create button in Job option.
Enter a name for the new Job.
Describe the Job (Optional).
Job Baseinfo: Select Python Job from the drop-down.
Trigger By: There are 2 options for triggering a job on success or failure of a job:
Success Job: On successful execution of the selected job the current job will be triggered.
Failure Job: On failure of the selected job the current job will be triggered.
Is Scheduled?
A job can be scheduled for a particular timestamp. Every time at the same timestamp the job will be triggered.
Job must be scheduled according to UTC.
Docker Configuration: Select a resource allocation option using the radio button. The given choices are:
Low
Medium
High
Provide the resources required to run the python Job in the limit and Request section.
Limit: Enter max CPU and Memory required for the Python Job.
Request: Enter the CPU and Memory required for the job at the start.
Instances: Enter the number of instances for the Python Job.
Click the Save option to save the Python Job.
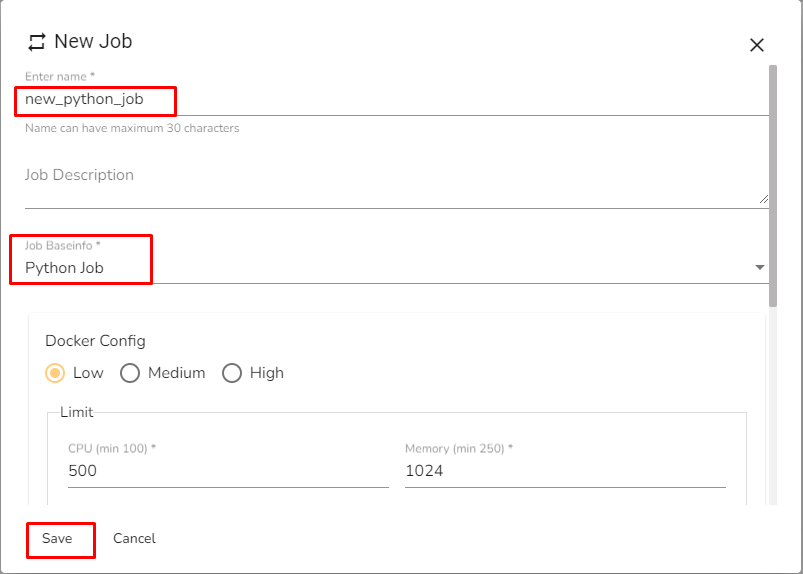
The Python Job gets saved, and it will redirect the users to the Job Editor workspace.

Check out the below given demonstration configure a Python Job.
Configuring the Meta Information of Python Job
Once the Python Job is created, follow the below given steps to configure the Meta Information tab of the Python Job.
Project Name: Select the same Project using the drop-down menu where the Notebook has been created.
Script Name: This field will list the exported Notebook names which are exported from the Data Science Lab module to Data Pipeline.
External Library: If any external libraries are used in the script the user can mention it here. The user can mention multiple libraries by giving comma (,) in between the names.
Start Function: Select the function name in which the script has been written.
Script: The Exported script appears under this space.
Input Data: If any parameter has been given in the function, then the name of the parameter is provided as Key, and value of the parameters has to be provided as value in this field.
Pod Logs: The user can see the pods logs of the job in the Pod Logs tab while the job is running.

Last updated