# Data Pipeline Handling Petabytes of Data
## What is Data Pipeline?
The Data Pipeline is a series of steps that enables a smooth flow of data from one source to another. Data Pipeline helps us to extract data from different sources and then process, validate, transform, and store it in the format required for analytics or to a raw data lake.
We can have a look into a use case implemented for a multinational automobile manufacturer with the real-time use of the BDB Data Pipeline.
## Driving Pattern use case
The purpose aims to better understand driving patterns to mitigate more efficiently potential failures and help the quality engineers to understand the cause of the issues raised by the customers and do R & D on their driving pattern.
### Problem Statement
The key objective is to build a GDPR-compliant solution to use historically connected car data and drive pattern behavior to reduce the lead time from the first vehicle quality compliant to implement the countermeasure.
### Data Source
* Blob Storage (Trip Data)
* APIs (User consent and Device details)
The database used for analysis is MongoDB and the data volume to be handled/ingested is more
than 40 GB.
### Data Understanding & Assumptions
Using synthetic development data, the solution is built and is in production. The actual trip data gets processed, and the driving pattern dashboard is used for the analysis of the same.
Any connected vehicle can have 1 or more devices that store the events like start, acceleration/deceleration, braking, speed, engine oil details, etc. All the events related to a trip are stored as a trip file in the Azure BLOB storage. This was accessible directly with credentials and using API.
* The trip file is a JSON file that has the trip level information and the event-wise information as an array.
* Other data sources used were to enrich the trip file with vehicle information like Model, NMSC, distributor, etc.
* Any trip can have a maximum of up to 2000 events. If the trip has more than 2000 events, then that information is not stored and there will be a 2001 event added to the trip file marking the end of the trip.
## Solution Approach
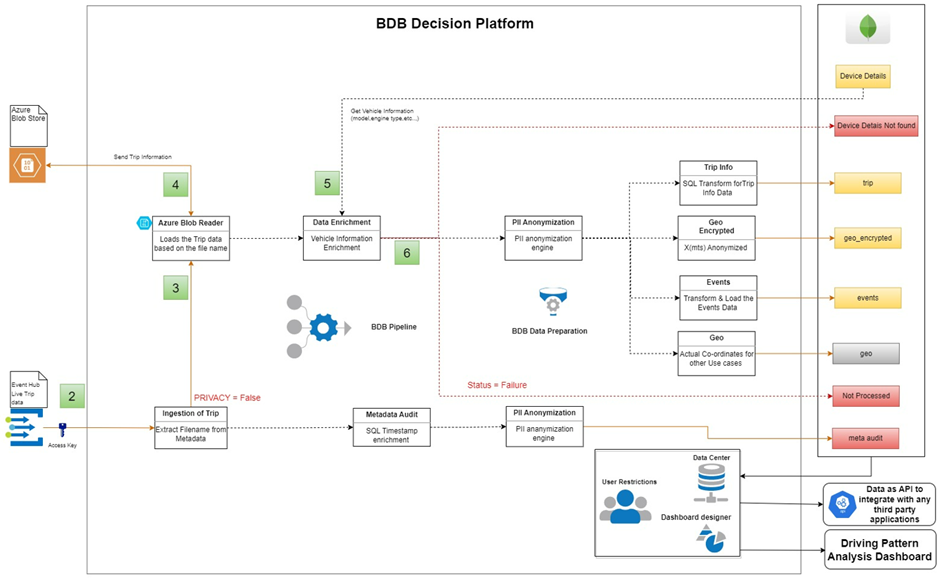
The below solution architecture image has detailed information on the solution planned for this use case. The trip data is received in real-time and enriched, and PII is anonymized and parallelly stored in multiple collections with respective data with Trip Key, VIN, and dates common across the collections.
### Why this Approach?
The trip data was stored in different collections as trip events are not required for every KPI used. Anonymization of geolocation was a requirement as exposing live locations is restricted as per GDPR.
### **Solution Architecture**
The pipeline makes use of multiple components, to ingest the data and perform the transformations required for analysis. Proper auditing is done for the ingestion. Failure in any component is captured in a failure event. These failover events can be later used for re-processing and tracing any errors or important alerts that need to be checked.
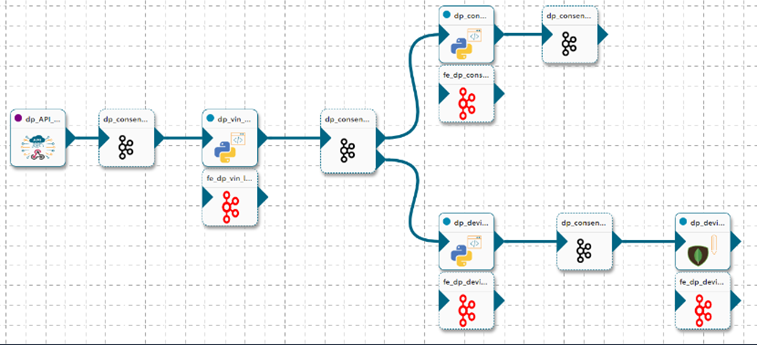
The solution also has a separate pipeline to collect the consent using an API ingestion component. The above flow works for only the consented Vehicles.
### Benefits Provided
With the help of this solution, the service engineers can access the Driving pattern of a consented car in the past six months and understand the complaints in the car based on the manufacturing defects as well as the driver's driving skills. With the warning light notification enabled based on the trips, they can granular point out the trip when the complaint has been raised and whether it is resolved automatically or needs any service person intervention. The R\&D department can monitor the vehicle performance and driving pattern for the next 6 months to understand the anomalies and provide a solution. This helps the engineers to understand whether this is any manufacturing defect from the company which can lead to calling the vehicles back due to it.
### Upscaling Possibilities
* As this is a solution for the Quality engineers, this information can be added with the driving score derived for the drivers and shared with each driver to assess the conditions and do optimal driving & usage of options in the vehicle.
* A driver suggestion model can be built and shared with the Drivers when they start the vehicle for a certain route. (Model as an API).
* A driver score model can be built and mapped with the driving license to know the pattern and find how the driver is obeying the traffic conditions. (Model as an API).
### Lesson Learnt with this implementation
* Optimize the pipelines to load huge data in less time. Make use of the monitoring to optimize the resource (core, memory, and instances).
* Transformation by python components, enrichment using APIs.
* Proper sharding and indexing help to improve the write/read performances of Mongo DB.
* Multiple modules in the platform could be well orchestrated to deliver a successful solution.
## Author's Details
* **Name**: Nitha P.
* **Designation**: Senior Data Warehouse Architect
* **Experience**: 15+ year of experience in BI industry and 10+ years in the BDB ecosystem.