Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
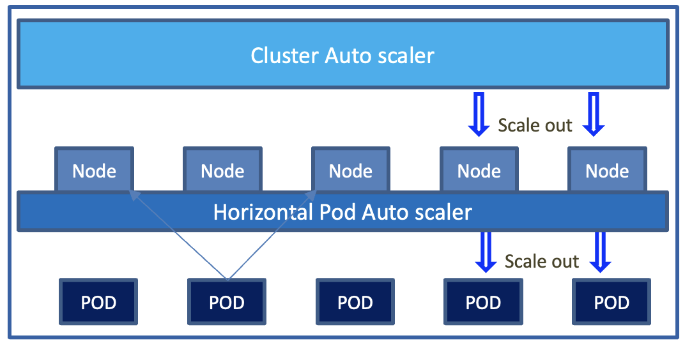
Kubernetes Cluster auto scaler will scale in and scale out the Nodes based on CPU and Memory Load.
Nodes are Virtual/Physical machines.
Each Microservice (Multiple services combined as container) is deployed as POD. Each POD is deployed into multiple Nodes for resilience.
PODs are enabled with autoscaling based on CPU and Memory Parameters.
All Pods are configured to have two instances, each deployed in different Nodes, using the node affinity parameter.
PODs are configured with self-healing, which mean when there is a failure a new POD is spun up.
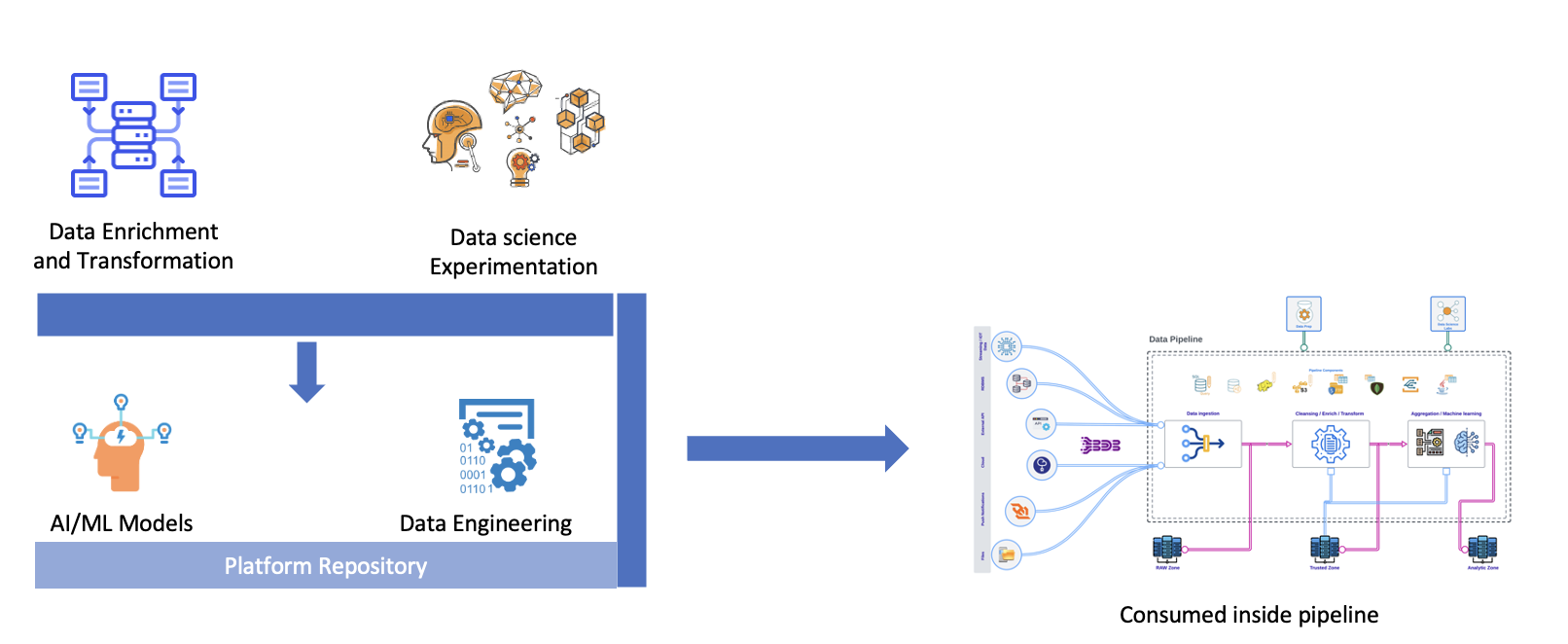
BDB Data Pipeline allows you to operationalize your AI/ML Models in few minutes. The Models can be attached to any pipeline to get the inferences in real-time. Then the inferences can either be used in any other process or get shared with the user instantly.
Data Science Lab Model & Script Runner
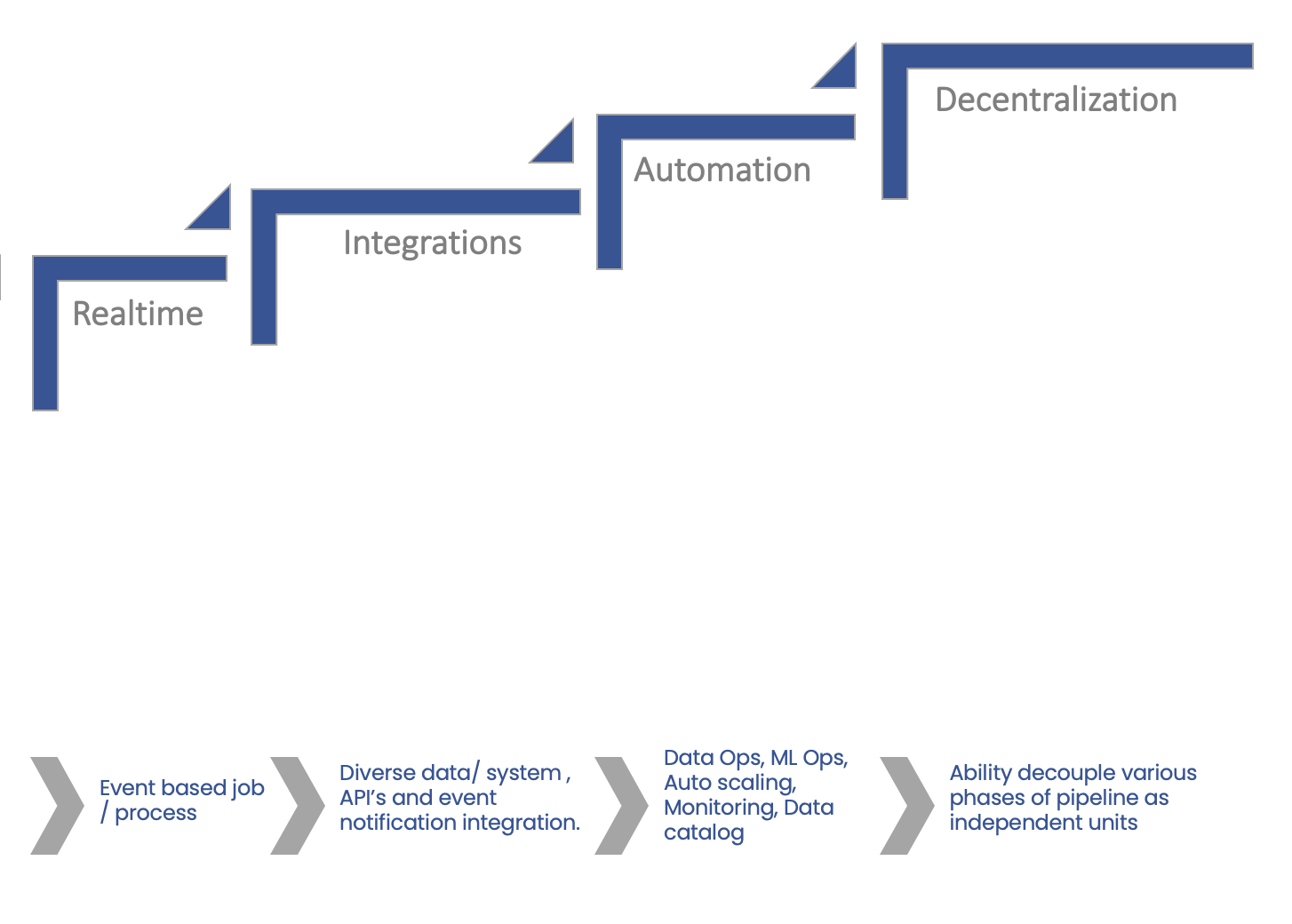
Traditional data transformation operation are sequential process where developer design and develop the logic and test and deploy it. BDB Data Pipeline allows the user to adopt the agile non-linear approach which reduces the time to market by 50 to 60 %
Distributed computing is the process of connecting multiple computers via a local network or wide area network so that they can act together as a single ultra-powerful computer capable of performing computations that no single computer within the network would be able to perform on its own.Distributed computers offer two key advantages:
Redundancy: Since many different machines are providing the same service, that service can keep running even if one (or more) of the computers goes down.
The user can run multiple instances of the same process to increase the process throughput. This can be done using the auto scaling feature.
Assembling a data pipeline is very simple. Just click and drag the component you want to use into editor canvas. Connect the component output to an event/topic.
Check out the given walk-through to understand the concept of Low Code Visual Authoring.
A wide variety of out-of-the-box components are available to read, write, transform, ingest data into the BDB Data Pipeline from a wide variety of data sources.
Components can be easily configured just by specifying the required metadata.
For extensibility, we have provided Python-based scripting support that allows the pipeline developer to build complex business requirements which cannot be met by out-of-the-box components.
Real-time processing deals with streams of data that are captured in real-time and processed with minimal latency. These processes run continuously and stay live even if the data info has stopped.
Batch job orchestration runs the process based on a trigger. In the BDB Data Pipeline, this trigger is the input event. Anytime data is pushed to the input trigger, the job will kick start. After completing the job, the process is gracefully terminated. This process can be near real-time. Also, it allows you to effectively utilise the compute resources.
Data pipelines are used to ingest and transfer data from different sources, transform unify and cleanse so that it’s suitable for analytics and business reporting.
“It is a collection of procedures that are carried either sequentially or even concurrently when transporting data from one or more sources to destination. Filtering, enriching, cleansing, aggregating, and even making inferences using AI/ML models may be part of these pipelines”.
Data pipelines are the backbone of the modern enterprise, Pipelines move, transform and store data so that enterprise can generate/take decision without delays. Some of these decisions are automated via AI/ML models in real-time.
It can handle both Streaming and batch data seamlessly. The Data pipeline offers an extensive list of data processing components that help you automate the entire data workflow, Ingestion, transformations, and running AI/ML models.
In the Data Pipeline plugin, we treat data as events. Data Processing components can listen to events, as data hits those events, the process kick starts automatically. These processes then publish the output to another event. This allows data engineers to chain the process and build large data flows.
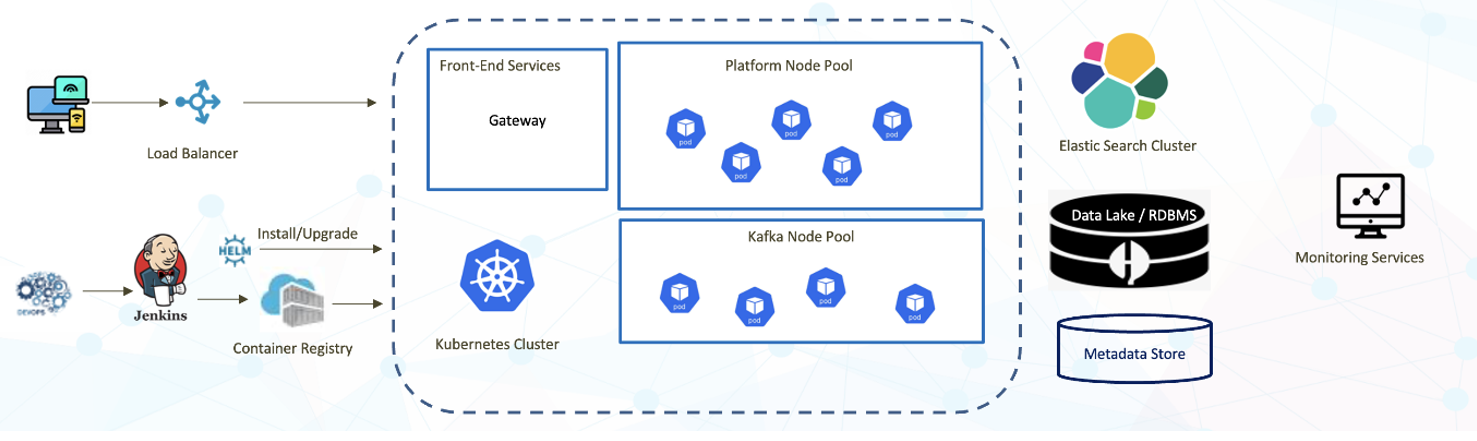
BDB Data Pipeline is available as a plugin to the BDB Platform. It can be deployed as a service in customers’ private accounts so that their data remains secure all the time.
There is in-build process scaler reads multiple process-metrics and automatically marks the scale-up or scale-down process. The BDB Pipelines consume data from your data source, transform it, and load it to your destination. You can send the processed data from your warehouse to any marketing, sales, or business application of your choice or vice versa. In-build process scaler reads multiple process-metrics and automatically marks the scale-up or scale-down process.
Readers: Your repository of data can be a reader for you. It could be a database, a file, or a SaaS application. Read
Connecting Components: The component that pulls or receives data from your source can be events/ connecting components for you. These Kafka-based messaging channels help to create a data flow. Read
Writers: The databases or data warehouses to which the Pipelines load the data. Read
Data Pipeline provides extensibility to create your transformation logic via the DS Lab module that acts as the innovation lab for data engineers and data scientists using which they can conduct modeling experiments, before productionizing the component using the Data Pipeline.
Please Note: Current version supports Python based scripting.
Transforms: The series of transformation components that help to cleanse, enrich, and prepare data for smooth analytics. Read Transformations.
Producers: Producers are the components that can be used to produce/generate streaming data to external sources. Read Producers.
Machine Learning: The Model Runner components allow the users to use the models created on the Python workspace of the Data Science Workbench or saved models from the Data Science Lab to be consumed in a pipeline. Read Machine Learning.
Consumers: These are the real-time / Streaming component that ingests data or monitor for changes in data objects from different sources to the pipeline. Read Consumers.
Alerts: These components facilitate user notification on various channels like Teams, Slack, and email based on their preferences. Notifications can be delivered for success, failure, or other relevant events, depending on the user's requirement. Read Alerts.
Scripting: The Scripting components allow users to write custom scripts and integrate them into the pipeline as needed. Read Scripting.
Scheduler: The Scheduler component enables users to schedule their pipeline at a specific time according to their requirements.
Each component has an in-event and out-event. Component consumes data from in event/topic, this data is then processed and pushed to another event/topic.
Every component in pipeline has a build-in consumer and producer functionality. This allows the component to consume data from an event process and send the output back to another Event/Topic.