Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
The role of data producers is to ensure a continuous flow of data into the pipeline, providing the necessary raw material for subsequent processing and analysis.
The Kafka producer acts as a data source within the pipeline, generating and publishing messages to Kafka for subsequent processing and consumption.
The Kafka producer plays a crucial role in the Data Pipeline module enabling reliable and scalable data ingestion into the Kafka cluster, where messages can be processed, transformed, and consumed by downstream components or applications.
Kafka's distributed and fault-tolerant architecture allows for scalable and efficient data streaming, making it suitable for various real-time data processing and analytics use cases.
This component is to produce messages to internal/external Kafka topics.
All component configurations are classified broadly into the following sections:
Meta Information
Follow the given demonstration to configure the Kafka Producer component.
Kafka Producer component consumes the data from the previous event and produce the data on a given Kafka topic. It can produce the data in same environment and external environment with CSV, JSON, XML and Avro format. This data can be further consumed by Kafka consumer in the data pipeline.
Drag and drop the Kafka Producer Component to the Workflow Editor.
Click on the dragged Kafka Producer component to get the component properties tabs.
Configure the Basic Information tab.
Select an Invocation type from the drop-down menu to confirm the running mode of the component. Select ‘Real-Time’ from the drop-down menu.
Deployment Type: It displays the deployment type for the component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu.
Batch Size (min 10): Provide maximum number of records to be processed in one execution cycle (Min limit for this field is 10.
Click on the Meta Information tab to open the properties fields and configure the Meta Information tab by providing the required fields.
Topic Name: Specify topic name where user want to produce data.
Is External: User can produce the data to external Kafka topic by enabling 'Is External' option. ‘Bootstrap Server’ and ‘Config’ fields will display after enable 'Is External' option.
Bootstrap Server: Enter external bootstrap details.
Config: Enter configuration details.
Input Record Type: It contain following input record type:
CSV: User can produce CSV data using this option. ‘Headers’ and ‘Separator’ fields will display if user select choose CSV input record type.
Header: In this field user can enter column names of CSV data that produce to the Kafka topic.
Separator: In this field user can enter separators like comma (,) that used for CSV data.
JSON: User can produce JSON data using this option.
XML: User can produce XML data using this option.
AVRO: User can produce AVRO data using this option. ‘Registry’, ‘Subject’ and ‘Schema’ fields will display if user selects AVRO as the input record type.
Registry: Enter registry details.
Subject: Enter subject details.
Schema: Enter schema.
Host Aliases: In Apache Kafka, a host alias (also known as a hostname alias) is an alternative name that can be used to refer to a Kafka broker in a cluster. Host aliases are useful when you need to refer to a broker using a name other than its actual hostname.
IP: Enter the IP.
Host Names: Enter the host names.
After doing all the configurations click the Save Component in Storage icon provides in the configuration panel to save the component.
A notification message appears to inform about the component configuration saved.
The EventHub Publisher serves as a bridge between the transformed data within the pipeline and the Azure Event Hubs service. It ensures the efficient and reliable transmission of data.
EventGrid producer component is designed to publish events to Azure EventGrid, which is a fully-managed event routing service provided by Microsoft Azure.
All component configurations are classified broadly in the following sections.
Meta Information
Follow the demonstration to configure the EventGrid Producer component.
Topic endpoint: It is a unique endpoint provided by Azure EventGrid that an EventGrid producer component can use to publish events to a specific topic.
Topic Secret Key: It is a security token that is used to authenticate and authorize access to an Azure EventGrid topic by an EventGrid producer component.
A WebSocket producer component is a software component that is used to send data over a WebSocket connection.
All component configurations are classified broadly into the following sections:
Meta Information
Follow the steps given in the demonstration to configure the WebSocket component.
This component can be used to produce data to the internal WebSocket to consume live data. The WebSocket Producer helps the user to get the message received by the Kafka topic.
Steps to configure the component:
Drag & Drop the WebSocket Producer component on the Workflow Editor.
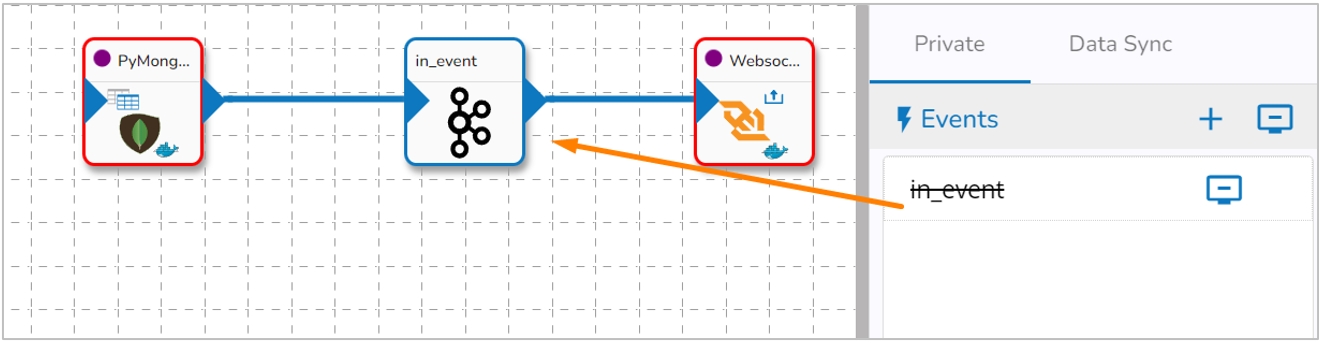
The producer component requires an input event (to get the data) and produces the data to the WebSocket location based on guid, ingestion Id, and ingestion Secret.
Create an event and drag them to the Workspace.
Connect the input event (The data in the input event can come from any Reader, Consumer, or Shared event).
Click on the dragged WebSocket Producer component to open the component properties tabs below.
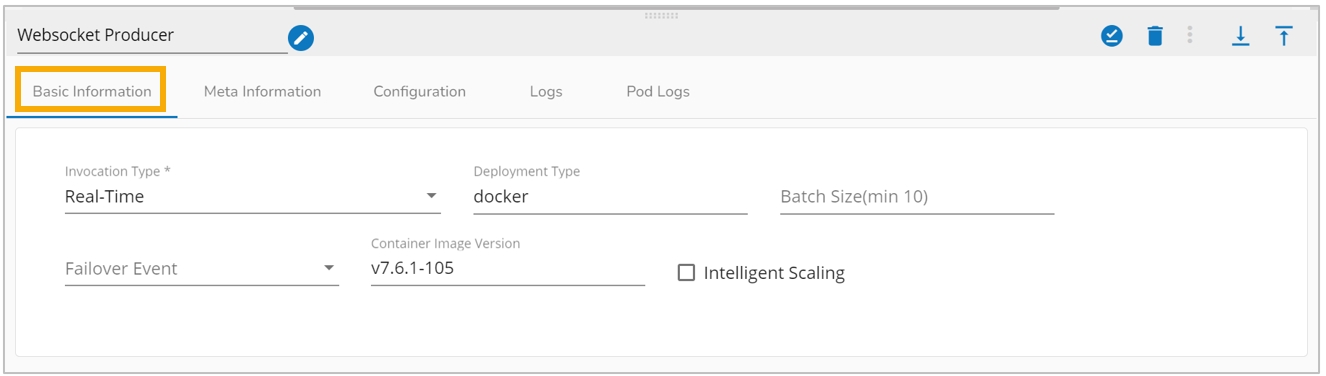
Basic Information: It is the default tab to open for the WebSocket Producer while configuring the component.
Invocation Type: Select an Invocation type from the drop-down menu to confirm the running mode of the WebSocket Producer component. The supported invocation type is ‘Real-Time’.
Deployment Type: It displays the deployment type for the component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover event from the drop-down menu.
Batch Size (min 10): Provide the maximum number of records to be processed in one execution cycle (Min limit for this field is 10).
Intelligent Scaling: Component pods scale up automatically based on the given max instance if the component lag is more than 60% and the pod goes down if the component lag is less than 10%.
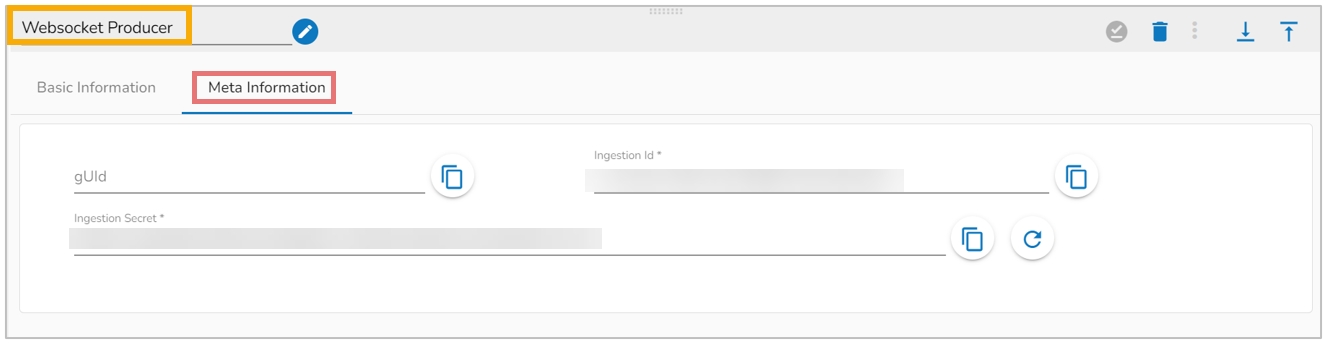
Open the Meta Information tab and configure the required fields:
GUID: It will be displayed after saving the component and updating the pipeline.
Ingestion Id: It will auto-generate with a new component.
Ingestion Secret: It will be auto-generated with a new component and regenerate after clicking on the Refresh Ingestion icon.
Click the Save Component in Storage icon provided in the WebSocket Producer configuration panel to save the component.
A message appears to notify the successful update of the component.
Click on the Update Pipeline icon to update the pipeline.
RabbitMQ producer plays a vital role in enabling reliable message-based communication and data flow within a data pipeline.
RabbitMQ is an open-source message-broker software that enables communication between different applications or services. It implements the Advanced Message Queuing Protocol (AMQP) which is a standard protocol for messaging middleware. RabbitMQ is designed to handle large volumes of message traffic and to support multiple messaging patterns such as point-to-point, publish/subscribe, and request/reply. In a RabbitMQ system, messages are produced by a sender application and sent to a message queue. Consumers subscribe to the queue to receive messages and process them accordingly. RabbitMQ provides reliable message delivery, scalability, and fault tolerance through features such as message acknowledgement, durable queues, and clustering.
In RabbitMQ, a producer is also referred to as a "publisher" because it publishes messages to a particular exchange. The exchange then routes the message to one or more queues, which can be consumed by one or more consumers (or "subscribers").
All component configurations are classified broadly into following section
Meta Information
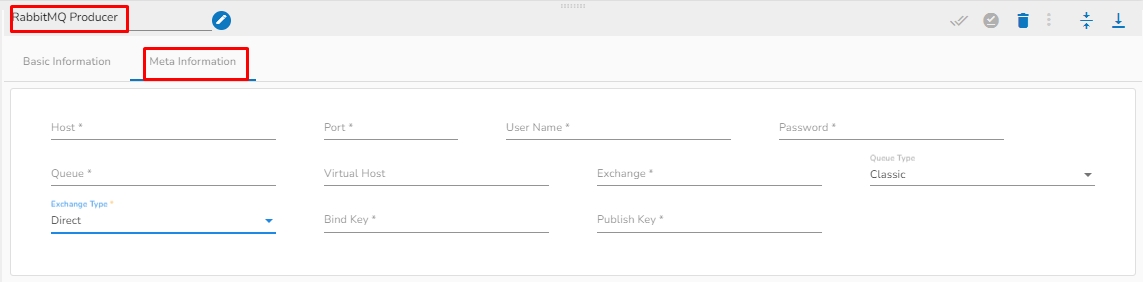
Host: Enter the host for RabbitMQ.
Port: Enter the port.
Username: Enter the username for RabbitMQ.
Password: Enter the password to authenticate with RabbitMQ Producer.
Queue: In RabbitMQ, a queue is a buffer that holds messages that are waiting to be processed by a consumer (or multiple consumers). In the context of a RabbitMQ producer, a queue is a destination where messages are sent for eventual consumption by one or more consumers.
Virtual host: Provide a virtual host. In RabbitMQ, a virtual host is a logical grouping of resources such as queues, exchanges, and bindings, which allows you to isolate and segregate different parts of your messaging system.
Exchange: Provide a Exchange. An exchange is a named entity in RabbitMQ that receives messages from producers and routes them to queues based on a set of rules called bindings. An exchange can have several types, including "direct", "fanout", "topic", and "headers", each of which defines a different set of routing rules.
Query Type: Select the query type from the drop-down. There are three(3) options available in it:
Classic: Classic queues are the most basic type of queue in RabbitMQ, and they work in a "first in, first out" (FIFO) manner. In classic queues, messages are stored on a single node, and consumers can retrieve messages from the head of the queue.
Stream: In stream queues, messages are stored across multiple nodes in a cluster, with each message being replicated across multiple nodes for fault tolerance. Stream queues allow for messages to be processed in parallel and can handle much higher message rates than classic queues.
Quorum: In quorum queues, messages are stored across multiple nodes in a cluster, with each message being replicated across a configurable number of nodes for fault tolerance. Quorum queues provide better performance than classic queues and better durability than stream queues.
Exchange Type: Select the query type from the drop-down. There are Four(4) exchange type supported:
Direct: A direct exchange type in RabbitMQ is one of the four possible exchange types that can be used to route messages between producers and consumers. In a direct exchange, messages are routed to one or more queues based on an exact match between the routing key specified by the producer and the binding key used by the queue. That is, the routing key must match the binding key exactly for the message to be routed to the queue.
Fanout: A fanout exchange routes all messages it receives to all bound queues indiscriminately. That is, it broadcasts every message it receives to all connected consumers, regardless of any routing keys or binding keys.
Topic: This type of exchange routes messages to one or more queues based on a matching routing pattern. Potential subtopics include how to create and bind to a topic exchange, how to use wildcards to match routing patterns, and how to publish and consume messages from a topic exchange. Two fields will be displayed when Direct, Fanout and Topic is selected as Exchange type:
Bind Key: Provide the Bind key. The binding key is used on the consumer (queue) side to determine how messages are routed from an exchange to a specific queue.
Publish Key: Enter the Publish key. The Publish key is used by the producer (publisher) when sending a message to an exchange.
Header: This type of exchange routes messages based on header attributes instead of routing keys. Potential subtopics include how to create and bind to a headers exchange, how to publish messages with specific header attributes, and how to consume messages from a headers exchange. X-Match: This field will only appear if Header is selected as Exchange type. There are two options in it:
Any: When X-match is set to any, the message will be delivered to a queue if it matches any of the header fields in the binding. This means that if a binding has multiple headers, the message will be delivered if it matches at least one of them.
All: When X-match is set to all, the message will only be delivered to a queue if it matches all of the header fields in the binding. This means that if a binding has multiple headers, the message will only be delivered if it matches all of them.
Binding Headers: This field will only appear if Header is selected as Exchange type. Enter the Binding headers key and value. Binding headers are used to create a binding between an exchange and a queue based on header attributes. You can specify a set of headers in a binding, and only messages that have matching headers will be routed to the bound queue.
Publishing Headers: This field will only appear if Header is selected as Exchange type. Enter the Publishing headers key and value. Publishing headers are used to attach header attributes to messages when they are published to an exchange.
The EventHub Publisher leverages the scalability and throughput capabilities of Event Hubs to ensure efficient and reliable event transmission.
All component configurations are classified broadly into 3 section
Meta Information
Please follow the steps given in the walk-through to configure the Eventhub Publisher component.
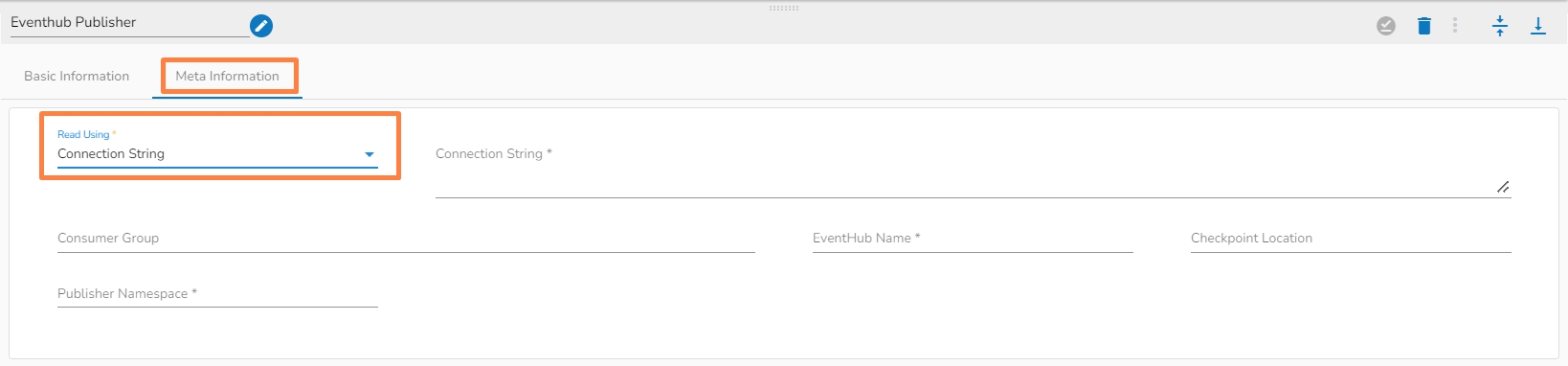
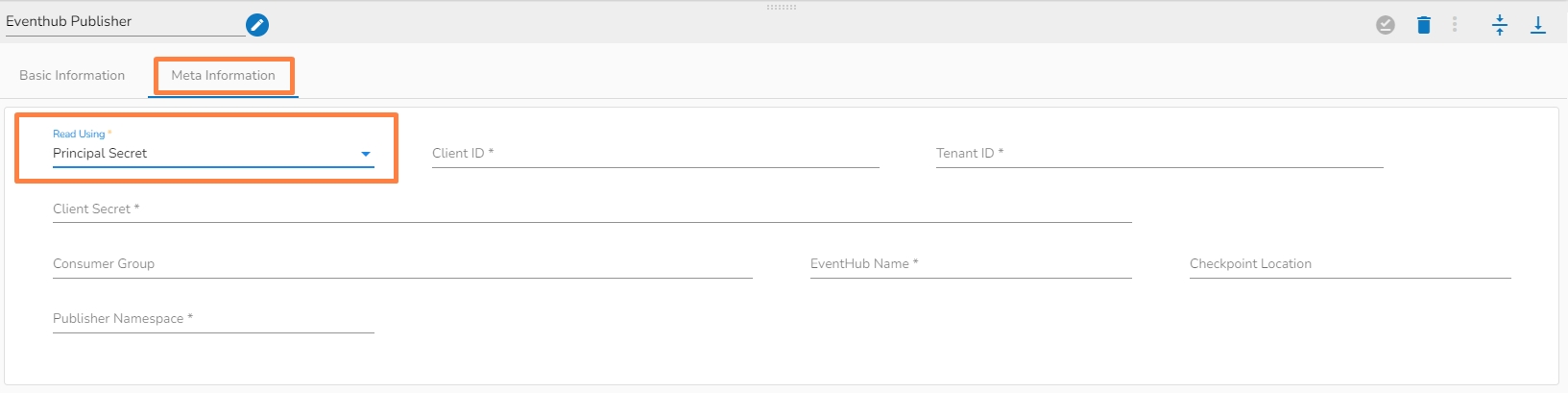
There are two read using methods:
Connection String
Principal Secret
Connection String: It is a string of parameters that are used to establish a connection to an Azure EventHub.
Consumer Group: It is a logical grouping of event consumers (subscribers) that read and process events from the same partition of an event hub.
EventHub Name: It refers to the specific Event Hub within the Event Hubs namespace to which data is being sent or received.
Checkpoint Location: It is a location in the event stream that represents the last event that has been successfully processed by the subscriber.
Enqueued time: It indicates the time when the event was added to the partition, which is typically the time when the event occurred or was generated.
Publisher namespace: It is a logical entity that is used to group related publishers and manage access control to EventHubs within the namespace.
Client ID: The ID of the Azure AD application that has been registered in the Azure portal and that will be used to authenticate the publisher. This can be found in the Azure portal under the "App registrations" section.
Tenant ID: The ID of the Azure AD tenant that contains the Azure AD application and service principal that will be used to authenticate the publisher.
Client secret: The secret value that is associated with the Azure AD application and that will be used to authenticate the publisher.
Consumer group: It is a logical grouping of event producer(publisher) that read and process events from the same partition of an event hub.
EventHub Name: It refers to the specific Event Hub within the Event Hubs namespace to which data is being sent or received.
Checkpoint Location: It is a location in the event stream that represents the last event that has been successfully processed by the publisher.
Enqueued time: It indicates the time when the event was added to the partition, which is typically the time when the event occurred or was generated.
Publisher namespace: It is a logical entity that is used to group related publishers and manage access control to EventHubs within the namespace.
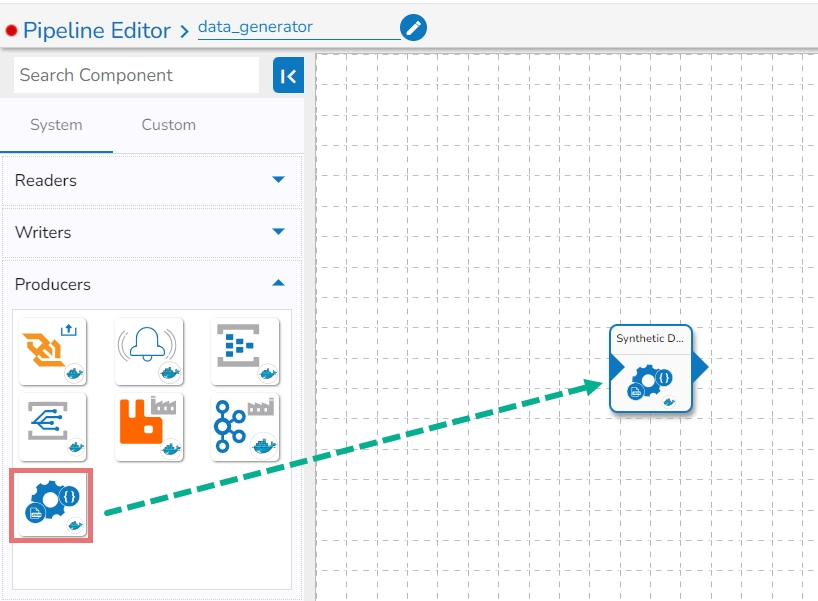
The Synthetic Data Generator component is designed to generate the desired data by using the Draft07 schema of the data that needs to be generated.
The user can upload the data in CSV or XLSX format and it will generate the draft07 schema for the same data.
Check out steps to create and use the Synthetic Data Generator component in a Pipeline workflow.
Drag and drop the Synthetic Data Generator Component to the Workflow Editor.
Click on the dragged Synthetic Data Generator component to get the component properties tabs.
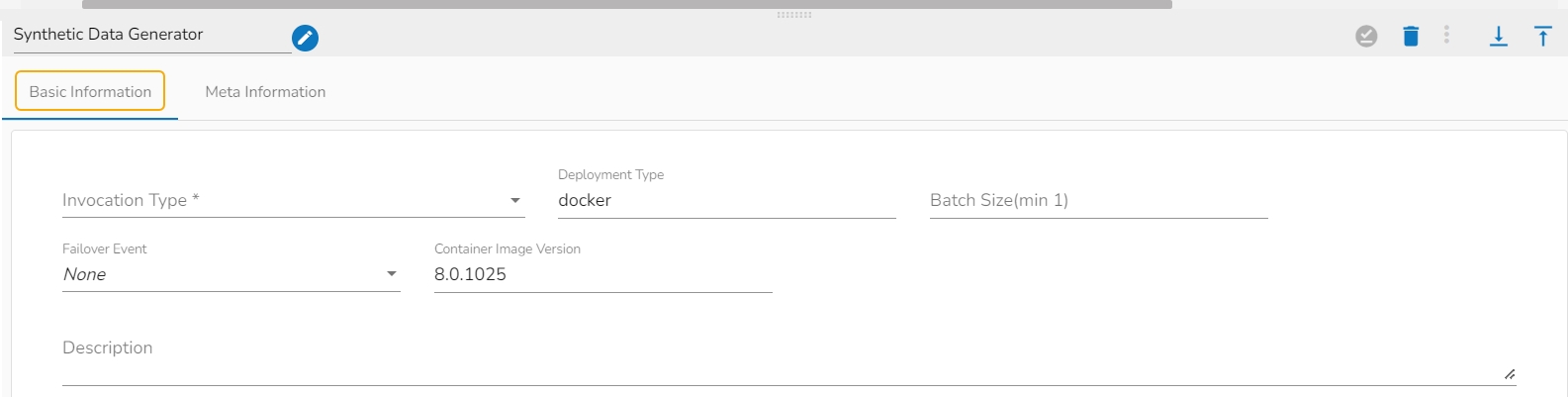
Configure the Basic Information tab.
Select an Invocation type from the drop-down menu to confirm the running mode of the component. Select the Real-Time option from the drop-down menu.
Deployment Type: It displays the deployment type for the component. This field comes pre-selected.
Container Image Version: It displays the image version for the docker container. This field comes pre-selected.
Failover Event: Select a failover Event from the drop-down menu .
Batch Size (min 10): Provide maximum number of records to be processed in one execution cycle (Min limit for this field is 10.
Configure the following information:
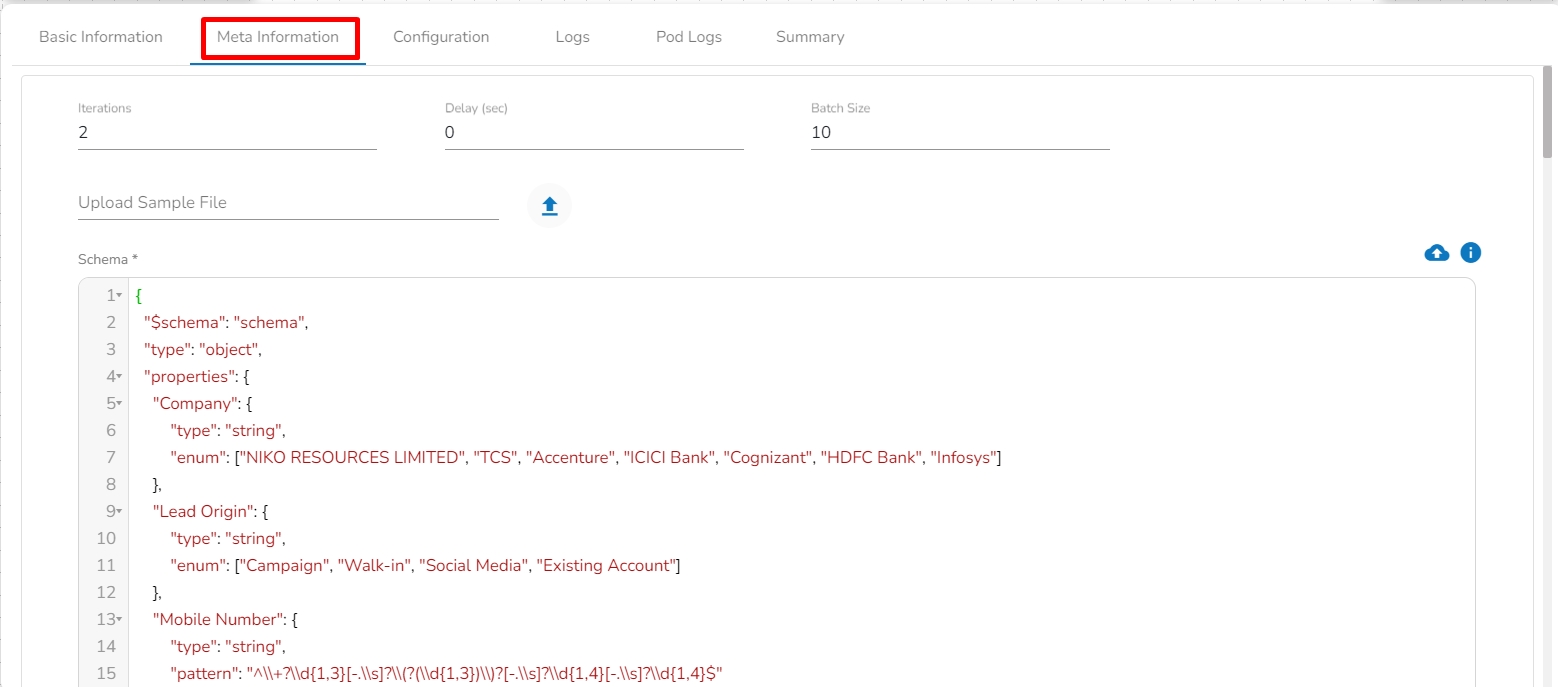
Iteration: Number of iterations for producing the data.
Delay (sec): Delay between each iteration in seconds.
Batch Size: Number of data to be produced in each iteration.
Upload Sample File: Upload the file containing data. CSV and XLSX file formats are supported. Once the file is uploaded, the draft07 schema for the uploaded file will be generated in the Schema tab. The supported files are CSV, Excel, and JSON formats.
Schema: Draft07 schema will display under this tab in the editable format.
Upload Schema: The user can directly upload the draft07 schema in JSON format from here. Also, the user can directly paste the draft07 schema in the schema tab.
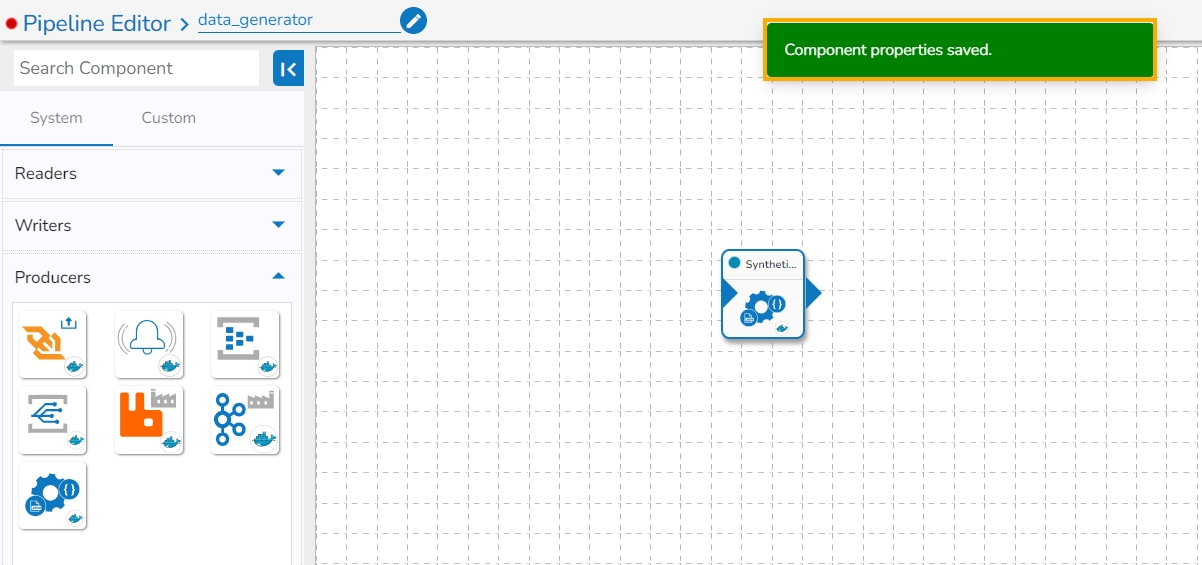
After doing all the configurations click the Save Component in Storage icon provided in the configuration panel to save the component.
A notification message appears to inform about the component configuration saved.
Please Note: Total number of generated data= Number of iterations * batch size
Please find a Sample Schema file given below for the users to explore the component.
Please Note: Weights can be given in order to handle the bias across the data generated:
The addition on weights should be exactly 1
"age": { "type": "string", "enum": ["Young", "Middle","Old"], "weights":[0.6,0.2,0.2]}
Type: "string"
Properties:
maxLength: Maximum length of the string.
minLength: Minimum length of the string.
enum: A list of values that the number can take.
weights: Weights for each value in the enum list.
format: Available formats include 'date', 'date-time', 'name', 'country', 'state', 'email', 'uri', and 'address'.
For 'date' and 'date-time' formats, the following properties can be set:
minimum: Minimum date or date-time value.
maximum: Maximum date or date-time value.
interval: For 'date' format, the interval is the number of days. For 'date-time' format, the interval is the time difference in seconds.
occurrence: Indicates how many times a date/date-time needs to repeat in the data. It should only be employed with the 'interval' and 'start' keyword.
A new format has been introduced for the string type: 'current_datetime'. This format generates records with the current date-time.
Type: "number"
Properties:
minimum: The minimum value for the number.
maximum: The maximum value for the number.
exclusiveMinimum: Indicates whether the minimum value is exclusive.
exclusiveMaximum: Indicates whether the maximum value is exclusive.
unique: Determines if the field should generate unique values (True/False).
start: Associated with unique values, this property determines the starting point for unique values.
enum: A list of values that the number can take.
weights: Weights for each value in the Enum list.
Type: "float"
Properties:
minimum: The minimum float value.
maximum: The maximum float value.
Please Note: Draft-07 schemas allow for the use of if-then-else conditions on fields, enabling complex validations and logical checks. Additionally, mathematical computations can be performed by specifying conditions within the schema.
Sample Draft-07 schema with if-then-else condition
Example: Here number3 value will be calculated based on
"$eval": "data.number1 + data.number2 * 2" condition.
Please Note : Conditional statement can also be applied on date and datetime columns using if-then-else. Please go through the below given schema for reference.
This above given JSON schema defines an object with two properties: "task_end_date" and "task_start_date", both of which are expected to be strings in date format. The schema includes a conditional validation rule using the "if-then" structure. If both "task_end_date" and "task_start_date" properties are present and in date format, then an additional constraint is applied. Specifically, the "task_end_date" must have a minimum value that is greater than or equal to the value of "task_start_date." This schema is useful for ensuring that task end dates are always set to a date that is on or after the task's start date when working with JSON data.