Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
All the available Writer Task components for a Job are explained in this section.
Writers are a group of components that can write data to different DB and cloud storages.
There are Eight(8) Writers tasks in Jobs. All the Writers tasks is having the following tabs:
Meta Information: Configure the meta information same as doing in pipeline components.
Preview Data: Only ten random data can be previewed in this tab only when the task is running in Development mode.
Preview schema: Spark schema of the data will be shown in this tab.
Logs: Logs of the tasks will display here.
HDFS stands for Hadoop Distributed File System. It is a distributed file system designed to store and manage large data sets in a reliable, fault-tolerant, and scalable way. HDFS is a core component of the Apache Hadoop ecosystem and is used by many big data applications.
This task writes the data in HDFS(Hadoop Distributed File System).
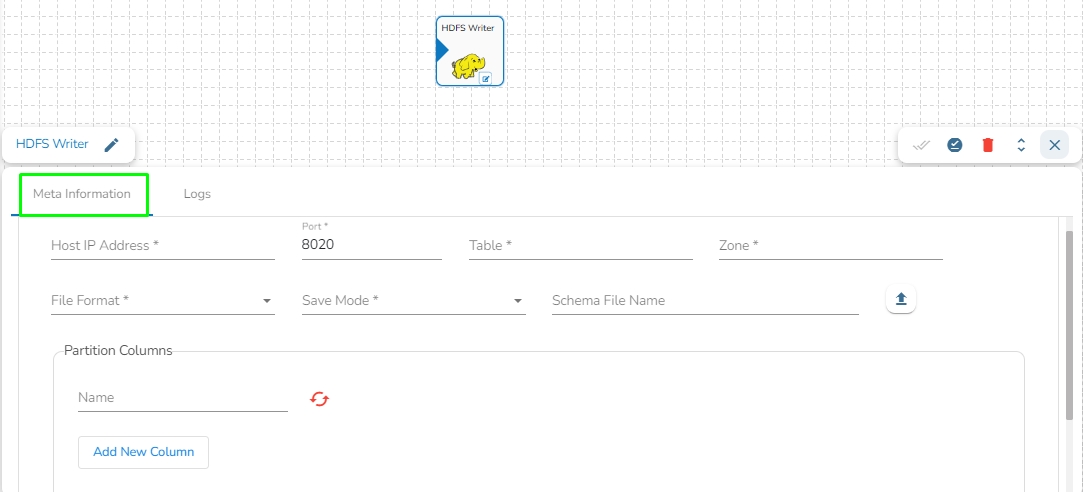
Drag the HDFS writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the host IP address for HDFS.
Port: Enter the Port.
Table: Enter the table name where the data has to be written.
Zone: Enter the Zone for HDFS in which the data has to be written. Zone is a special directory whose contents will be transparently encrypted upon write and transparently decrypted upon read.
File Format: Select the file format in which the data has to be written:
CSV
JSON
PARQUET
AVRO
Save Mode: Select the save mode.
Schema file name: Upload spark schema file in JSON format.
Partition Columns: Provide a unique Key column name to partition data in Spark.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
Azure is a cloud computing platform and service. It provides a range of cloud services, including infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS) offerings, as well as tools for building, deploying, and managing applications in the cloud.
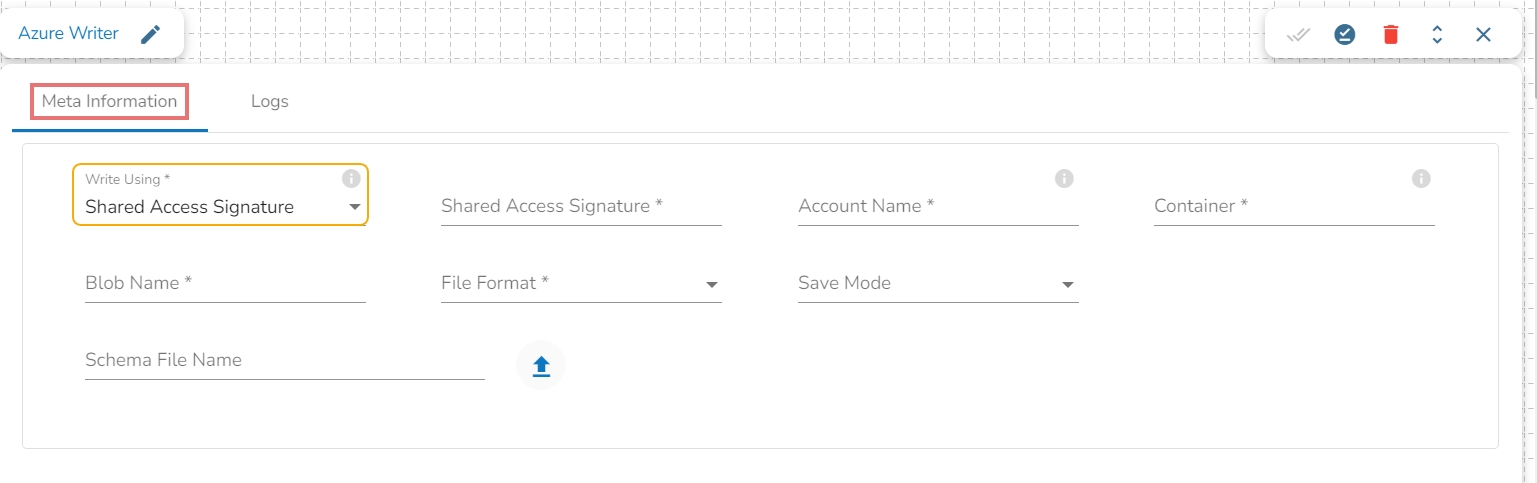
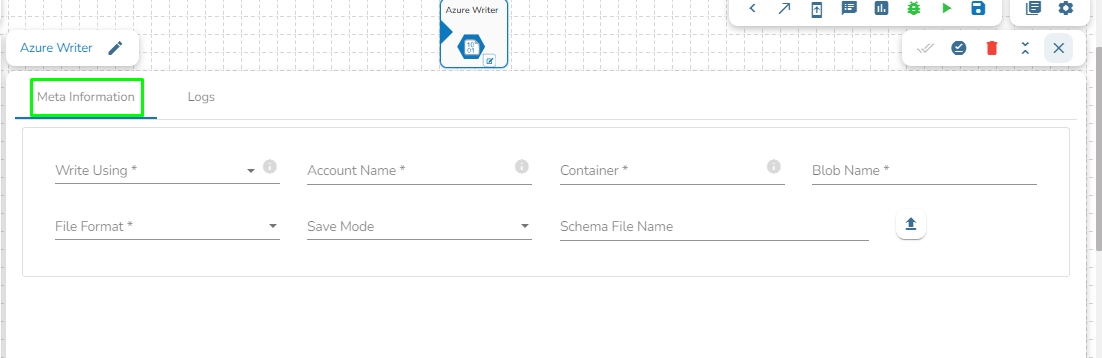
Azure Writer task is used to write the data in the Azure Blob Container.
Drag the Azure writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
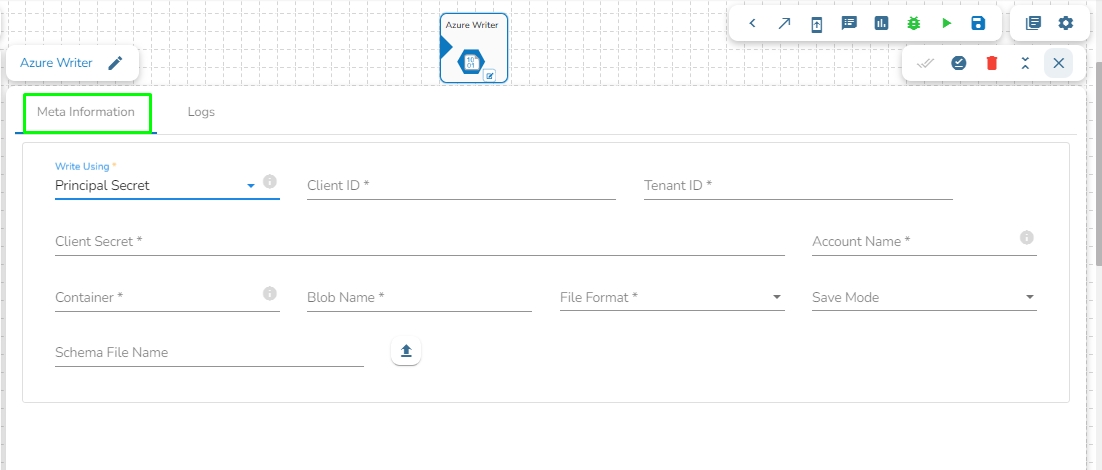
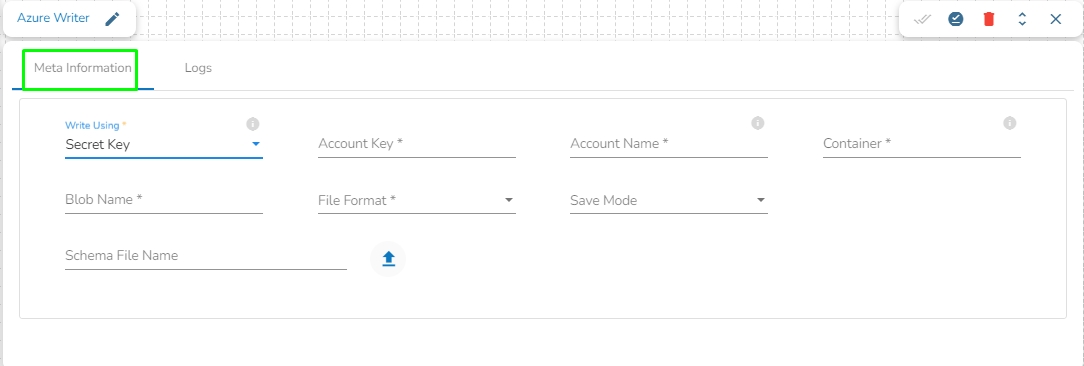
Write using: There are three(3) options available under this tab:
Shared Access Signature:
Secret Key
Principal Secret
Provide the following details:
Shared Access Signature: This is a URI that grants restricted access rights to Azure Storage resources.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the blob is located. A container is a logical unit of storage in Azure Blob Storage that can hold blobs. It is similar to a directory or folder in a file system, and it can be used to organize and manage blobs.
Blob Name: Enter the Blob name. A blob is a type of object storage that is used to store unstructured data, such as text or binary data, like images or videos.
File Format: There are four(4) types of file extensions are available under it, select the file format in which the data has to be written:
CSV
JSON
PARQUET
AVRO
Save Mode: Select the Save mode from the drop down.
Append
Overwrite
Schema File Name: Upload spark schema file in JSON format.
Account Key: Enter the azure account key. In Azure, an account key is a security credential that is used to authenticate access to storage resources, such as blobs, files, queues, or tables, in an Azure storage account.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the blob is located. A container is a logical unit of storage in Azure Blob Storage that can hold blobs. It is similar to a directory or folder in a file system, and it can be used to organize and manage blobs.
Blob Name: Enter the Blob name. A blob is a type of object storage that is used to store unstructured data, such as text or binary data, like images or videos.
File type: There are four(4) types of file extensions are available under it:
CSV
JSON
PARQUET
AVRO
Schema File Name: Upload spark schema file in JSON format.
Save Mode: Select the Save mode from the drop down.
Append
Overwrite
Provide the following details:
Client ID: Provide Azure Client ID. The client ID is the unique Application (client) ID assigned to your app by Azure AD when the app was registered.
Tenant ID: Provide the Azure Tenant ID. Tenant ID (also known as Directory ID) is a unique identifier that is assigned to an Azure AD tenant, which represents an organization or a developer account. It is used to identify the organization or developer account that the application is associated with.
Client Secret: Enter the Azure Client Secret. Client Secret (also known as Application Secret or App Secret) is a secure password or key that is used to authenticate an application to Azure AD.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the blob is located. A container is a logical unit of storage in Azure Blob Storage that can hold blobs. It is similar to a directory or folder in a file system, and it can be used to organize and manage blobs.
Blob Name: Enter the Blob name. A blob is a type of object storage that is used to store unstructured data, such as text or binary data, like images or videos.
File type: There are four(4) types of file extensions are available under it:
CSV
JSON
PARQUET
AVRO
Save Mode: Select the Save mode from the drop down.
Append
Overwrite
Schema File Name: Upload spark schema file in JSON format.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
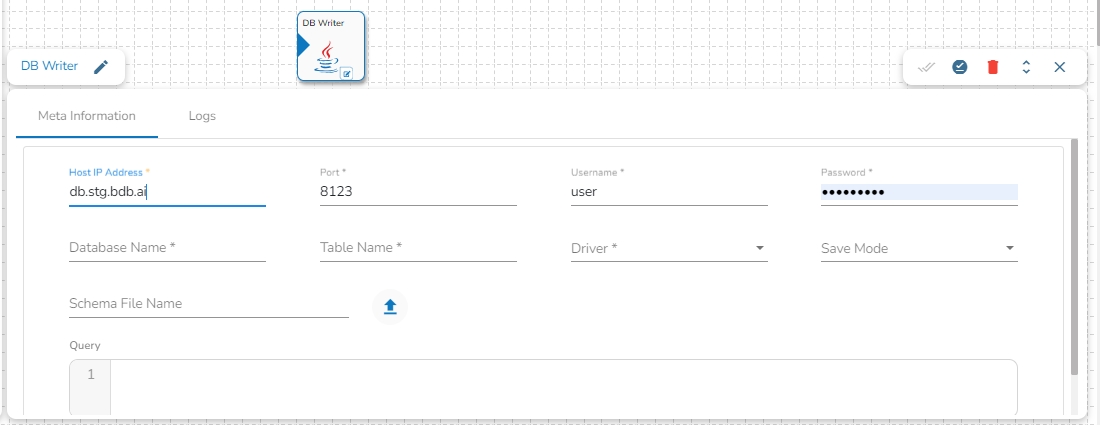
This task is used to write data in the following databases: MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL, Redshift.
Drag the DB writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the Host IP Address for the selected driver.
Port: Enter the port for the given IP Address.
Database name: Enter the Database name.
Table name: Provide a single or multiple table names. If multiple table name has be given, then enter the table names separated by comma(,).
User name: Enter the user name for the provided database.
Password: Enter the password for the provided database.
Driver: Select the driver from the drop down. There are 6 drivers supported here: MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL, Redshift.
Schema File Name: Upload spark schema file in JSON format.
Save Mode: Select the Save mode from the drop down.
Append
Overwrite
Query: Write the create table(DDL) query.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
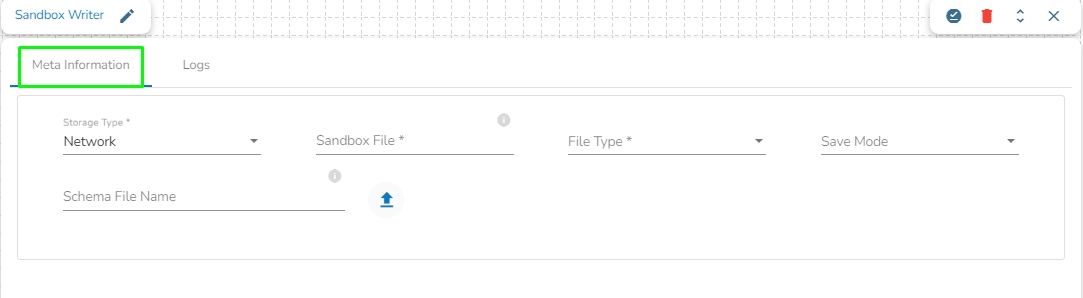
This task writes data to network pool of Sandbox.
Drag the Sandbox writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Storage Type: This field is pre-defined.
Sandbox File: Enter the file name.
File Type: Select the file type in which the data has to be written. There are 4 files types supported here:
CSV
JSON
Save Mode: Select the Save mode from the drop down.
Append
Overwrite
Schema File Name: Upload spark schema file in JSON format.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
Elasticsearch is an open-source search and analytics engine built on top of the Apache Lucene library. It is designed to help users store, search, and analyze large volumes of data in real-time. Elasticsearch is a distributed, scalable system that can be used to index and search structured, semi-structured, and unstructured data.
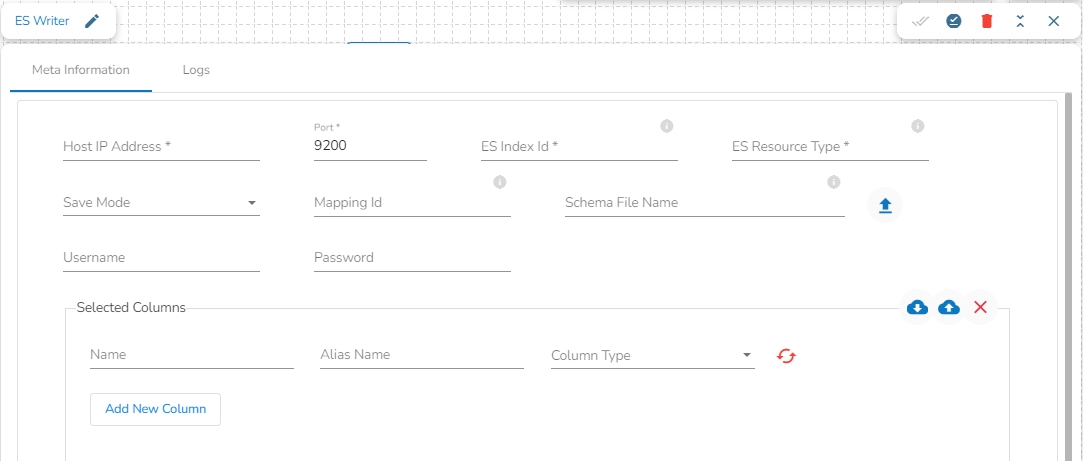
This task is used to write the data in Elastic Search engine.
Drag the ES writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the host IP Address for Elastic Search.
Port: Enter the port to connect with Elastic Search.
Index ID: Enter the Index ID to read a document in elastic search. In Elasticsearch, an index is a collection of documents that share similar characteristics, and each document within an index has a unique identifier known as the index ID. The index ID is a unique string that is automatically generated by Elasticsearch and is used to identify and retrieve a specific document from the index.
Mapping ID: Provide the Mapping ID. In Elasticsearch, a mapping ID is a unique identifier for a mapping definition that defines the schema of the documents in an index. It is used to differentiate between different types of data within an index and to control how Elasticsearch indexes and searches data.
Resource Type: Provide the resource type. In Elasticsearch, a resource type is a way to group related documents together within an index. Resource types are defined at the time of index creation, and they provide a way to logically separate different types of documents that may be stored within the same index.
Username: Enter the username for elastic search.
Password: Enter the password for elastic search.
Schema File Name: Upload spark schema file in JSON format.
Save Mode: Select the Save mode from the drop down.
Append
Selected columns: The user can select the specific column, provide some alias name and select the desired data type of that column.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
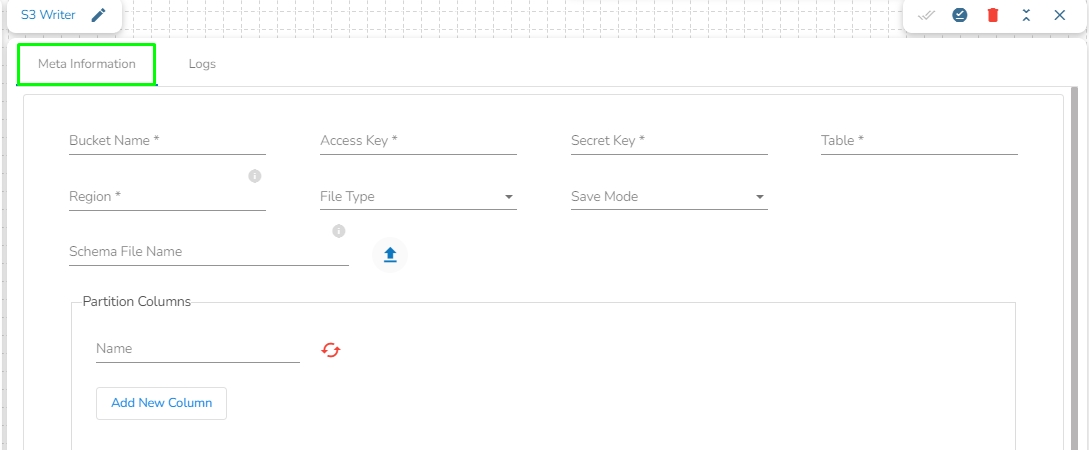
This task is used to write the data in Amazon S3 bucket.
Drag the S3 writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Bucket Name (*): Enter S3 Bucket name.
Region (*): Provide S3 region.
Access Key (*): Access key shared by AWS to login
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which is to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO are the supported file types).
Save Mode: Select the Save mode from the drop down.
Append
Schema File Name: Upload spark schema file in JSON format.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
This section provides details about the various categories of the task components which can be used in the Spark Job.
There are three categories of task components available:
All the available Reader Task components are included in this section.
Readers are a group of tasks that can read data from different DB and cloud storages. In Jobs, all the tasks run in real-time.
There are eight(8) Readers tasks in Jobs. All the readers tasks contains the following tabs:
Meta Information: Configure the meta information same as doing in pipeline components.
Preview Data: Only ten(10) random data can be previewed in this tab only when the task is running in Development mode.
Preview schema: Spark schema of the reading data will be shown in this tab.
Logs: Logs of the tasks will display here.
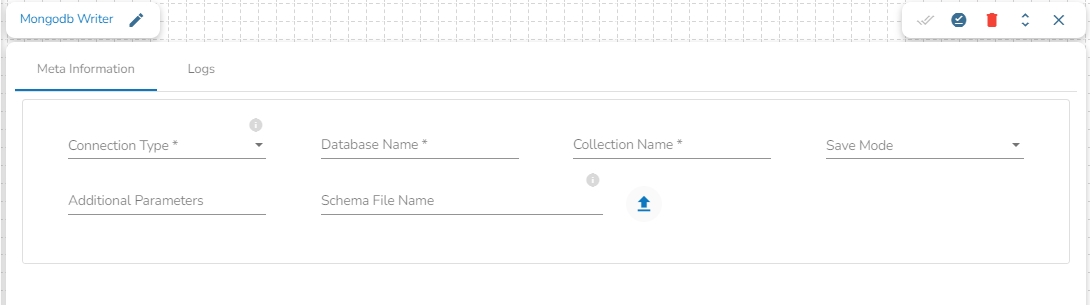
This task writes the data to MongoDB collection.
Drag the MongoDB writer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Connection Type: Select the connection type from the drop-down:
Standard
SRV
Connection String
Port (*): Provide the Port number (It appears only with the Standard connection type).
Host IP Address (*): The IP address of the host.
Username (*): Provide a username.
Password (*): Provide a valid password to access the MongoDB.
Database Name (*): Provide the name of the database where you wish to write data.
Additional Parameters: Provide details of the additional parameters.
Schema File Name: Upload Spark Schema file in JSON format.
Save Mode: Select the Save mode from the drop down.
Append: This operation adds the data to the collection.
Ignore: "Ignore" is an operation that skips the insertion of a record if a duplicate record already exists in the database. This means that the new record will not be added, and the database will remain unchanged. "Ignore" is useful when you want to prevent duplicate entries in a database.
Upsert: It is a combination of "update" and "insert". It is an operation that updates a record if it already exists in the database or inserts a new record if it does not exist. This means that "upsert" updates an existing record with new data or creates a new record if the record does not exist in the database.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
HDFS stands for Hadoop Distributed File System. It is a distributed file system designed to store and manage large data sets in a reliable, fault-tolerant, and scalable way. HDFS is a core component of the Apache Hadoop ecosystem and is used by many big data applications.
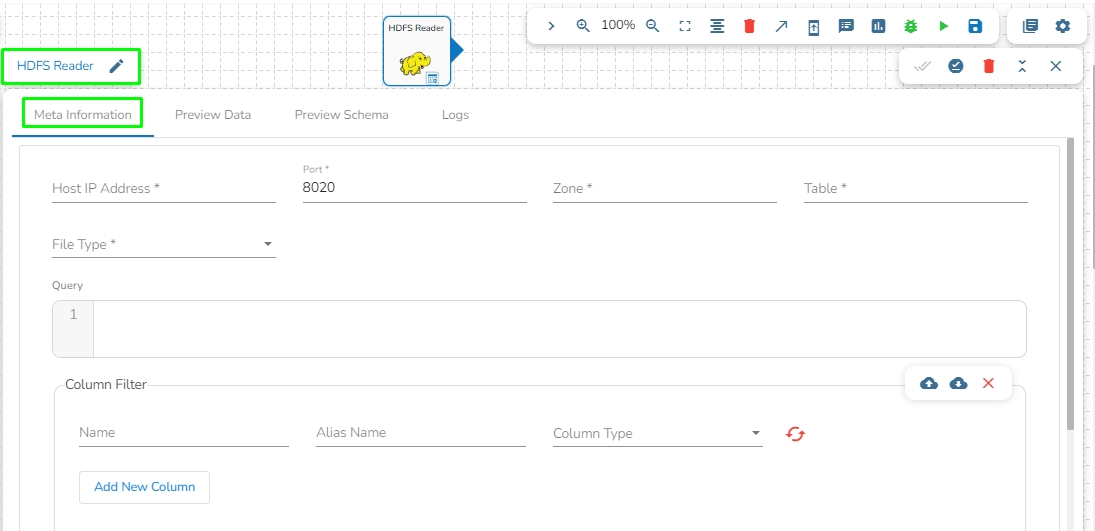
This task reads the file located in HDFS (Hadoop Distributed File System).
Drag the HDFS reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the host IP address for HDFS.
Port: Enter the Port.
Zone: Enter the Zone for HDFS. Zone is a special directory whose contents will be transparently encrypted upon write and transparently decrypted upon read.
File Type: Select the File Type from the drop down. The supported file types are:
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
Path: Provide the path of the file.
Partition Columns: Provide a unique Key column name to partition data in Spark.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
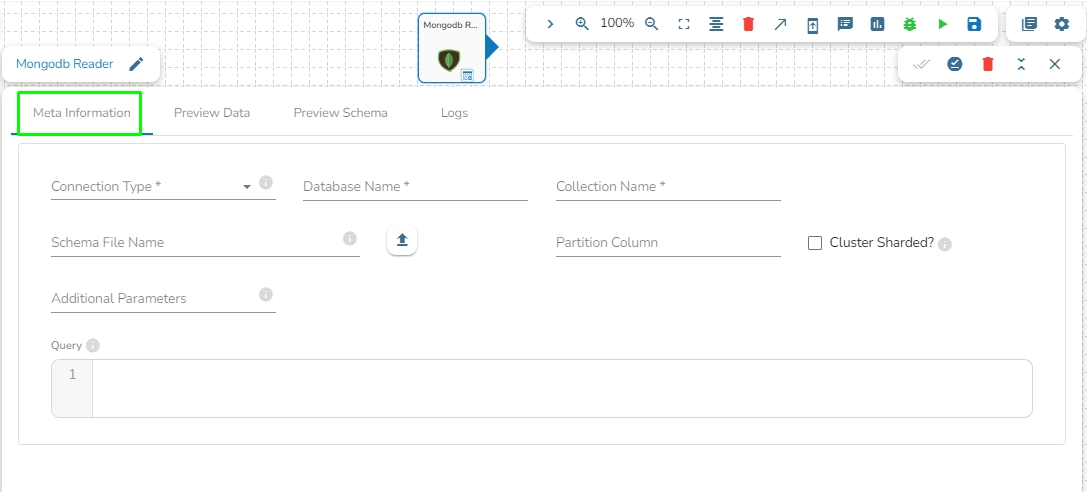
This task is used to read data from MongoDB collection.
Drag the MongoDB reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Connection Type: Select the connection type from the drop-down:
Standard
SRV
Connection String
Port (*): Provide the Port number (It appears only with the Standard connection type).
Host IP Address (*): The IP address of the host.
Username (*): Provide a username.
Password (*): Provide a valid password to access the MongoDB.
Database Name (*): Provide the name of the database where you wish to write data.
Additional Parameters: Provide details of the additional parameters.
Cluster Shared: Enable this option to horizontally partition data across multiple servers.
Schema File Name: Upload Spark Schema file in JSON format.
Query: Please provide Mongo Aggregation query in this field.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
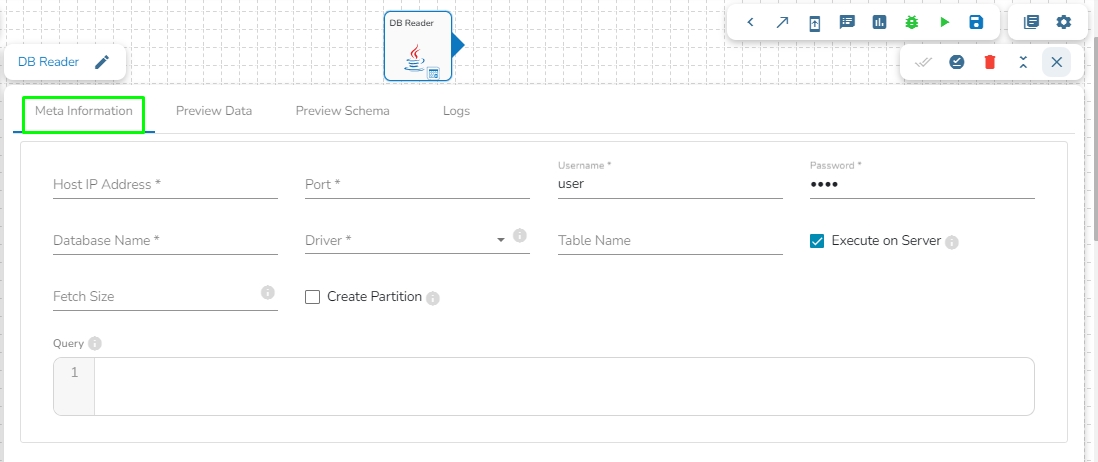
This task is used to read the data from the following databases: MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL, Redshift.
Drag the DB reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the Host IP Address for the selected driver.
Port: Enter the port for the given IP Address.
Database name: Enter the Database name.
Table name: Provide a single or multiple table names. If multiple table name has be given, then enter the table names separated by comma(,).
User name: Enter the user name for the provided database.
Password: Enter the password for the provided database.
Driver: Select the driver from the drop down. There are 7 drivers supported here: MYSQL, MSSQL, Oracle, ClickHouse, Snowflake, PostgreSQL, Redshift.
Fetch Size: Provide the maximum number of records to be processed in one execution cycle.
Create Partition: This is used for performance enhancement. It's going to create the sequence of indexing. Once this option is selected, the operation will not execute on server.
Partition By: This option will appear once create partition option is enabled. There are two options under it:
Auto Increment: The number of partitions will be incremented automatically.
Index: The number of partitions will be incremented based on the specified Partition column.
Query: Enter the spark SQL query in this field for the given table or table(s). Please refer the below image for making query on multiple tables.
Please Note:
The ClickHouse driver in the Spark components will use HTTP Port and not the TCP port.
In the case of data from multiple tables (join queries), one can write the join query directly without specifying multiple tables, as only one among table and query fields is required.
Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
In Apache Kafka, a "producer" is a client application or program that is responsible for publishing (or writing) messages to a Kafka topic.
A Kafka producer sends messages to Kafka brokers, which are then distributed to the appropriate consumers based on the topic, partitioning, and other configurable parameters.
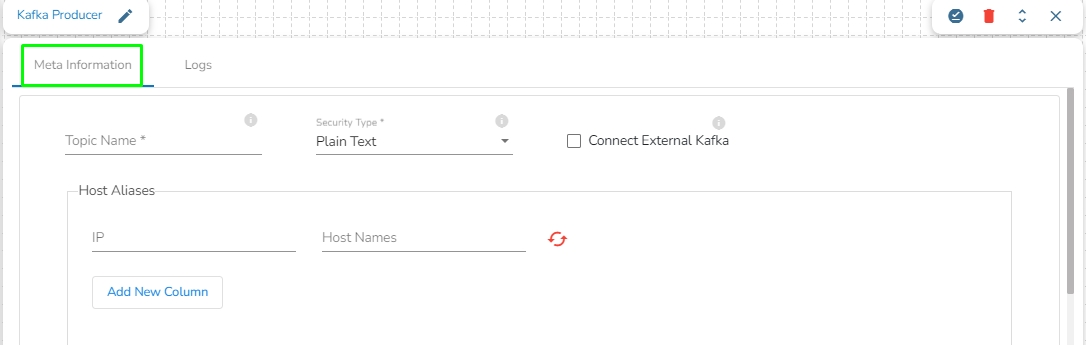
Drag the Kafka Producer task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Topic Name: Specify topic name where user want to produce data.
Security Type: Select the security type from drop down:
Plain Text
SSL
Is External: User can produce the data to external Kafka topic by enabling 'Is External' option. ‘Bootstrap Server’ and ‘Config’ fields will display after enable 'Is External' option.
Bootstrap Server: Enter external bootstrap details.
Config: Enter configuration details.
Host Aliases: In Apache Kafka, a host alias (also known as a hostname alias) is an alternative name that can be used to refer to a Kafka broker in a cluster. Host aliases are useful when you need to refer to a broker using a name other than its actual hostname.
IP: Enter the IP.
Host Names: Enter the host names.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged writer task.
Elasticsearch is an open-source search and analytics engine built on top of the Apache Lucene library. It is designed to help users store, search, and analyze large volumes of data in real-time. Elasticsearch is a distributed, scalable system that can be used to index and search structured, semi-structured, and unstructured data.
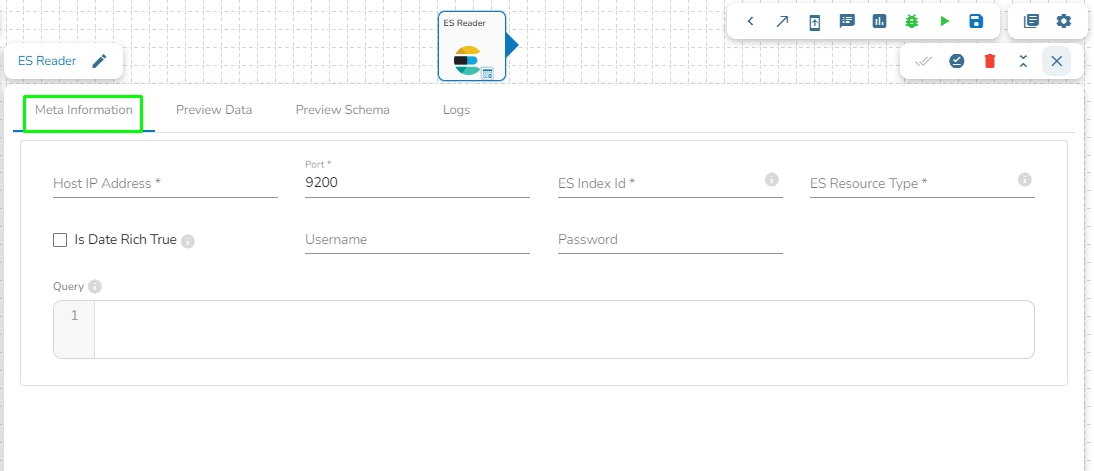
This task is used to read the data located in Elastic Search engine.
Drag the ES reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Host IP Address: Enter the host IP Address for Elastic Search.
Port: Enter the port to connect with Elastic Search.
Index ID: Enter the Index ID to read a document in elastic search. In Elasticsearch, an index is a collection of documents that share similar characteristics, and each document within an index has a unique identifier known as the index ID. The index ID is a unique string that is automatically generated by Elasticsearch and is used to identify and retrieve a specific document from the index.
Resource Type: Provide the resource type. In Elasticsearch, a resource type is a way to group related documents together within an index. Resource types are defined at the time of index creation, and they provide a way to logically separate different types of documents that may be stored within the same index.
Is Date Rich True: Enable this option if any fields in the reading file contain date or time information. The "date rich" feature in Elasticsearch allows for advanced querying and filtering of documents based on date or time ranges, as well as date arithmetic operations.
Username: Enter the username for elastic search.
Password: Enter the password for elastic search.
Query: Provide a spark SQL query.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
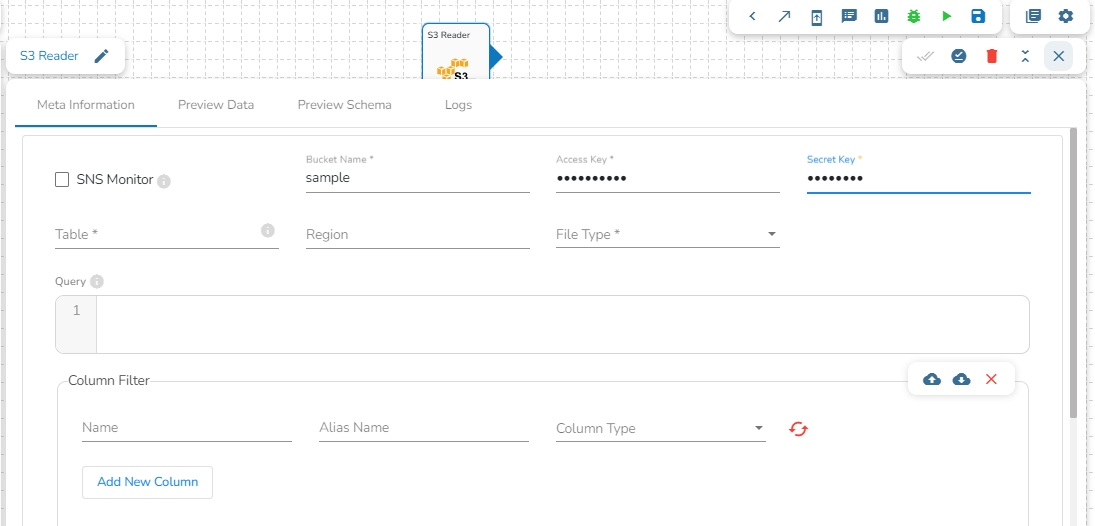
This task reads the file from Amazon S3 bucket.
Please follow the below mentioned steps to configure meta information of S3 reader task:
Drag the S3 reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Bucket Name (*): Enter S3 bucket name.
Region (*): Provide the S3 region.
Access Key (*): Access key shared by AWS to login..
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which is to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO, XML are the supported file types)
Limit: Set a limit for the number of records.
Query: Insert an SQL query (it supports query containing a join statement as well).
Access Key (*): Access key shared by AWS to login
Secret Key (*): Secret key shared by AWS to login
Table (*): Mention the Table or object name which has to be read
File Type (*): Select a file type from the drop-down menu (CSV, JSON, PARQUET, AVRO, XML are the supported file types)
Limit: Set limit for the number of records
Query: Insert an SQL query (it supports query containing a join statement as well)
Provide a unique Key column name to partition data in Spark.
Please Note:
Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
Once file type is selected the multiple fields will appear. Follow the below steps for the selected different file types.
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
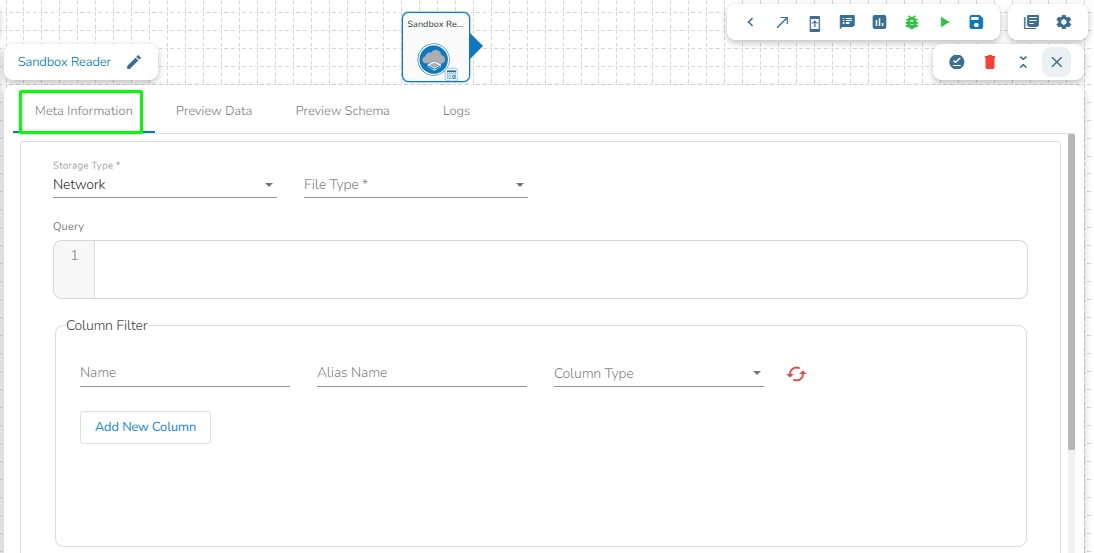
This task can read the data from the Network pool of Sandbox.
Drag the Sandbox reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Storage Type: This field is pre-defined.
Sandbox File: Select the file name from the drop-down.
File Type: Select the file type from the drop down.
There are four(5) types of file extensions are available under it:
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Query: Provide Spark SQL query in this field.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
Amazon Athena is an interactive query service that easily analyzes data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. With a few actions in the AWS Management Console, you can point Athena at your data stored in Amazon S3 and begin using standard SQL to run ad-hoc queries and get results in seconds.
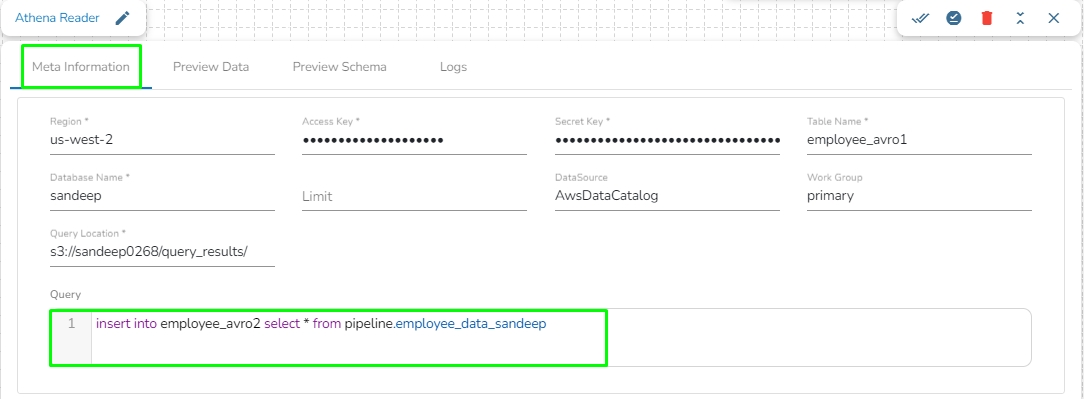
Athena Query Executer task enables users to read data directly from the external table created in AWS Athena.
Please Note: Please go through the below given demonstration to configure Athena Query Executer in Jobs.
Region: Enter the region name where the bucket is located.
Access Key: Enter the AWS Access Key of the account that must be used.
Secret Key: Enter the AWS Secret Key of the account that must be used.
Table Name: Enter the name of the external table created in Athena.
Database Name: Name of the database in Athena in which the table has been created.
Limit: Enter the number of records to be read from the table.
Data Source: Enter the Data Source name configured in Athena. Data Source in Athena refers to your data's location, typically an S3 bucket.
Workgroup: Enter the Workgroup name configured in Athena. The Workgroup in Athena is a resource type to separate query execution and query history between Users, Teams, or Applications running under the same AWS account.
Query location: Enter the path where the results of the queries done in the Athena query editor are saved in the CSV format. Users can find this path under the Settings tab in the Athena query editor as Query Result Location.
Query: Enter the Spark SQL query.
Sample Spark SQL query that can be used in Athena Reader:
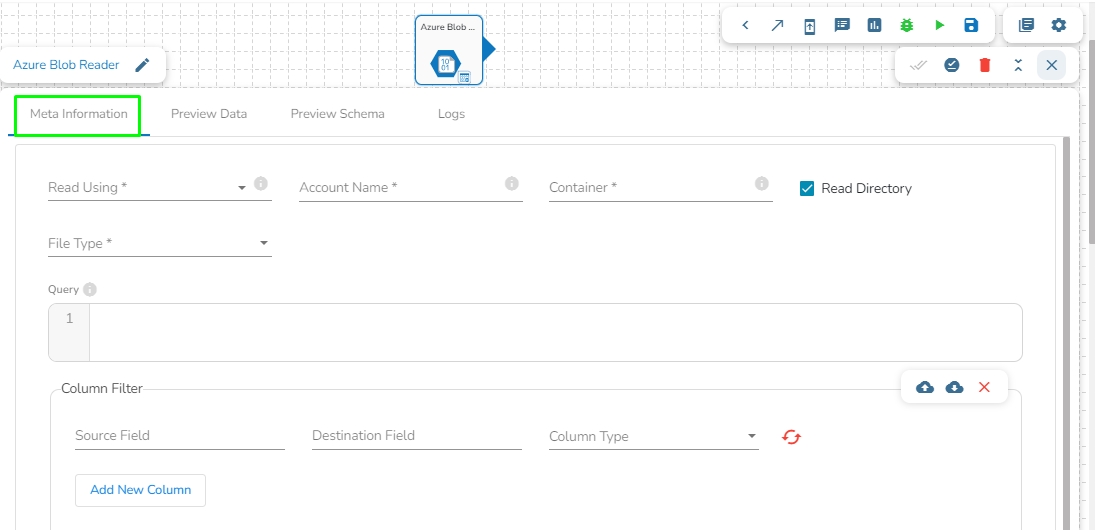
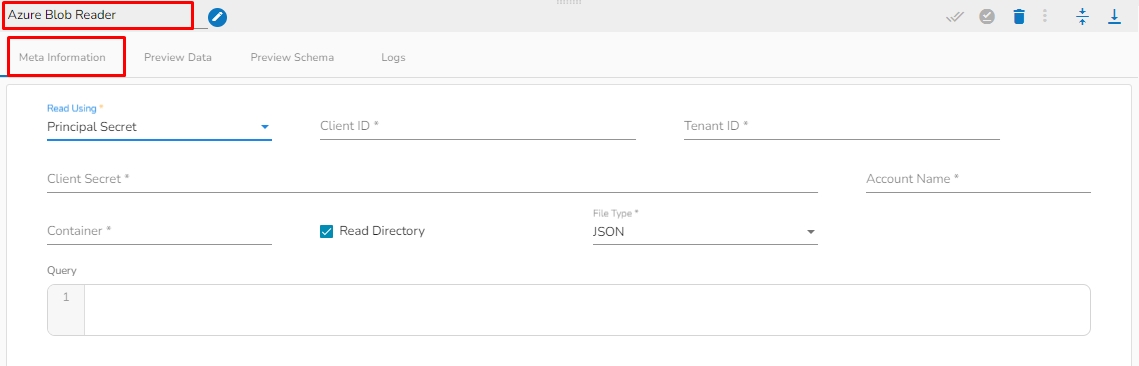
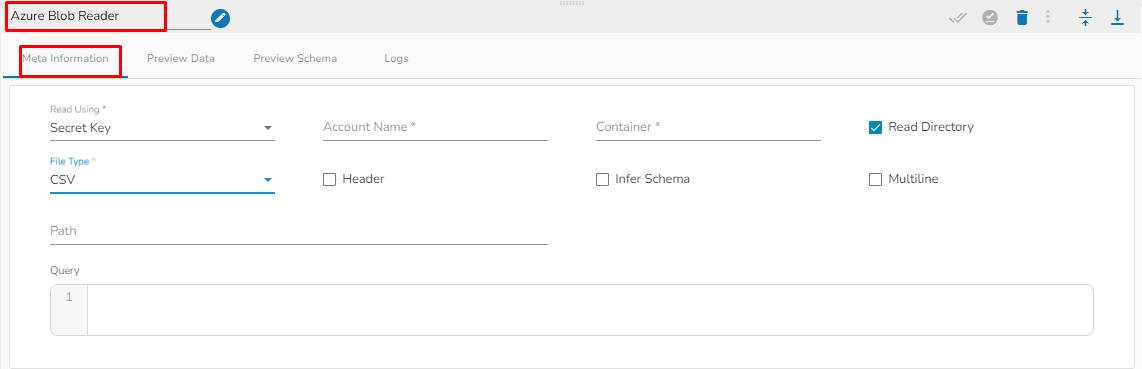
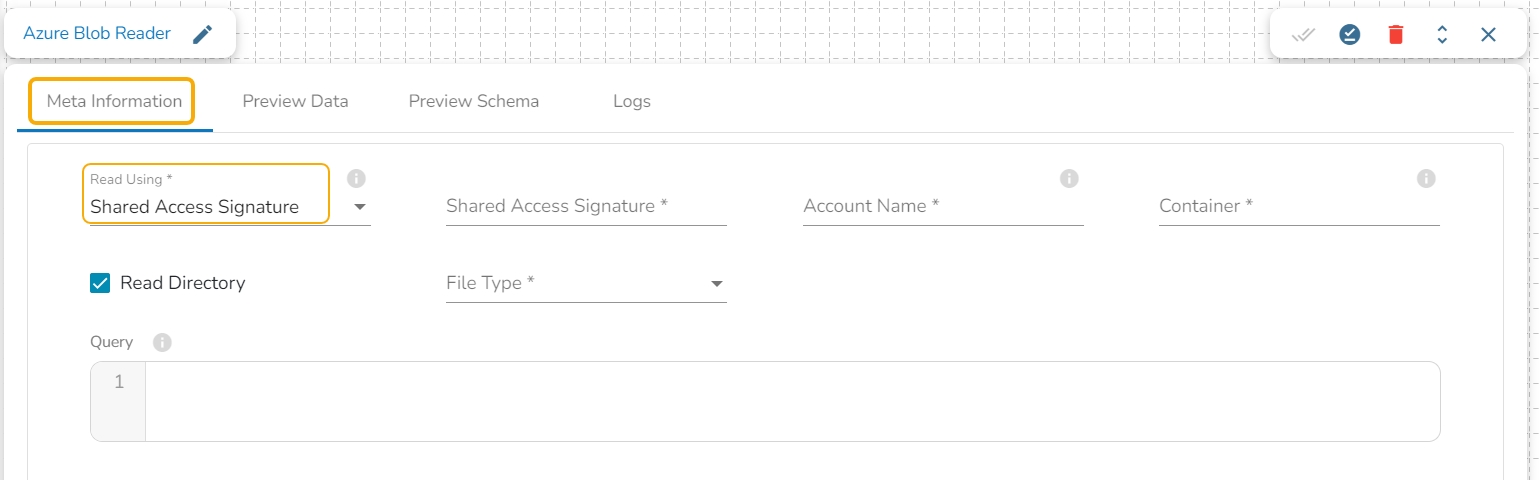
This task is used to read data from Azure blob container.
Drag the Azure Blob reader task to the Workspace and click on it to open the related configuration tabs for the same. The Meta Information tab opens by default.
Read using: There are three(3) options available under this tab:
Provide the following details:
Shared Access Signature: This is a URI that grants restricted access rights to Azure Storage resources.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the file is located and which has to be read.
File type: There are four(5) types of file extensions are available under it:
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
Path: This option will appear once the file type is selected. Enter the path where the selected file type is located.
Read Directory: Check in this box to read the specified directory.
Query: Provide Spark SQL query in this field.
Provide the following details:
Account Key: Enter the Azure account key. In Azure, an account key is a security credential that is used to authenticate access to storage resources, such as blobs, files, queues, or tables, in an Azure storage account.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the blob is located. A container is a logical unit of storage in Azure Blob Storage that can hold blobs. It is similar to a directory or folder in a file system, and it can be used to organize and manage blobs.
File type: There are four(5) types of file extensions are available under it:
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
Path: This option will appear once the file type is selected. Enter the path where the selected file type is located.
Read Directory: Check in this box to read the specified directory.
Query: Provide Spark SQL query in this field.
Provide the following details:
Client ID: Provide Azure Client ID. The client ID is the unique Application (client) ID assigned to your app by Azure AD when the app was registered.
Tenant ID: Provide the Azure Tenant ID. Tenant ID (also known as Directory ID) is a unique identifier that is assigned to an Azure AD tenant, which represents an organization or a developer account. It is used to identify the organization or developer account that the application is associated with.
Client Secret: Enter the Azure Client Secret. Client Secret (also known as Application Secret or App Secret) is a secure password or key that is used to authenticate an application to Azure AD.
Account Name: Provide the Azure account name.
Container: Provide the container name from where the blob is located. A container is a logical unit of storage in Azure Blob Storage that can hold blobs. It is similar to a directory or folder in a file system, and it can be used to organize and manage blobs.
Query: Provide Spark SQL query in this field.
File type: There are four(5) types of file extensions are available under it:
CSV: The Header and Infer Schema fields get displayed with CSV as the selected File Type. Enable Header option to get the Header of the reading file and enable Infer Schema option to get true schema of the column in the CSV file.
JSON: The Multiline and Charset fields get displayed with JSON as the selected File Type. Check-in the Multiline option if there is any multiline string in the file.
PARQUET: No extra field gets displayed with PARQUET as the selected File Type.
AVRO: This File Type provides two drop-down menus.
Compression: Select an option out of the Deflate and Snappy options.
Compression Level: This field appears for the Deflate compression option. It provides 0 to 9 levels via a drop-down menu.
XML: Select this option to read XML file. If this option is selected, the following fields will get displayed:
Infer schema: Enable this option to get true schema of the column.
Path: Provide the path of the file.
Root Tag: Provide the root tag from the XML files.
Row Tags: Provide the row tags from the XML files.
Join Row Tags: Enable this option to join multiple row tags.
Please Note: Please click the Save Task In Storage icon to save the configuration for the dragged reader task.
This page aims to explain the various transformation options provided on the Jobs Editor page.
The following transformations are provided under the Transformations section.
Alter Columns
Select Columns
Date Formatter
Query
Filter
Formula
Join
Aggregation
Sort Task
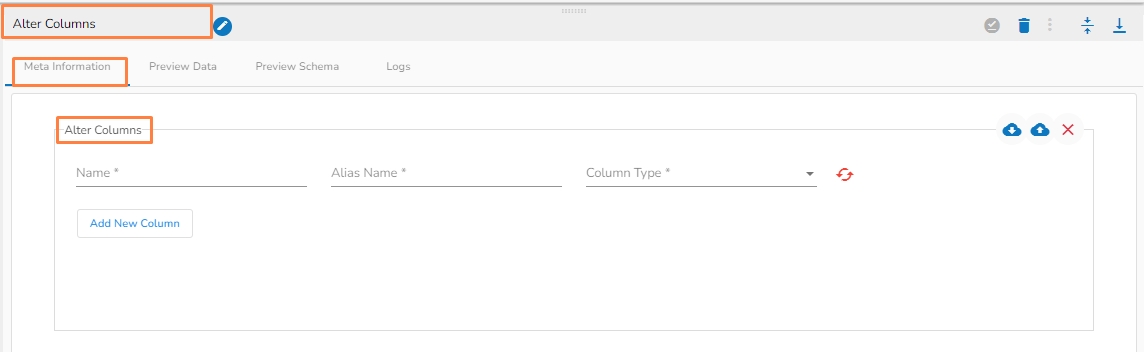
The Alter Columns command is used to change the data type of a column in a table.
Add the Column name from the Alter Columns tab where the datatype needs to be changed.
Name (*): Column name.
Alias Name(*) : New column name.
Column Type(*): Specify datatype from dropdown.
Add New Column: Multiple columns can be added for desired modification in the datatype.
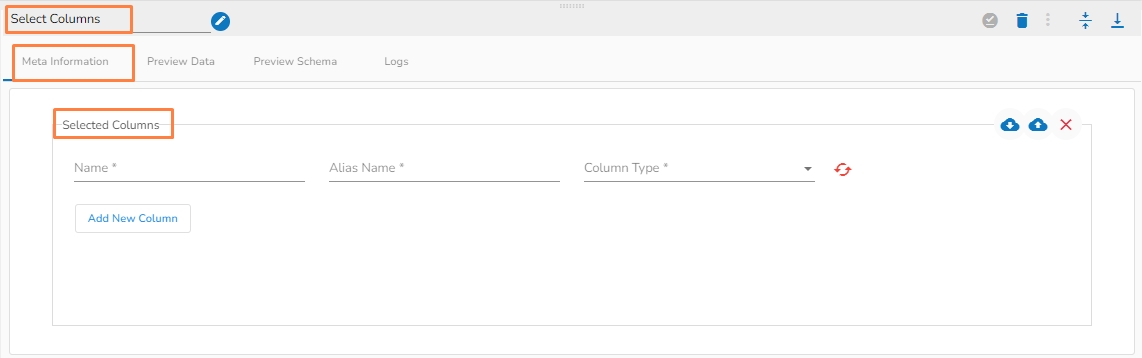
Helps to select particular columns from a table definition.
Name (*): Column name.
Alias Name(*) : New column name.
Column Type(*) : Specify datatype from dropdown.
Add New Column: Multiple columns can be added for the desired result
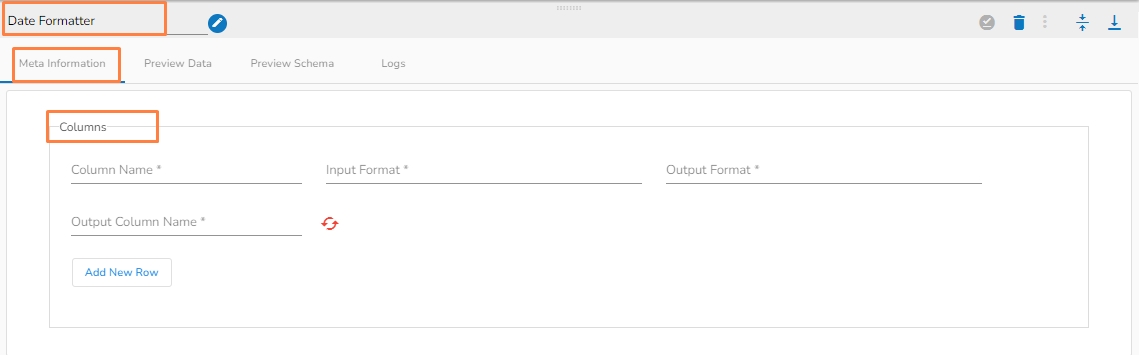
It helps in converting Date and Datetime columns to a desired format.
Name (*): Column name.
Input Format(*) : The function has total 61 different formats.
Output Format(*): The format in which the output will be given.
Output Column Name(*): Name of the output column.
Add New Row: To insert a new row.
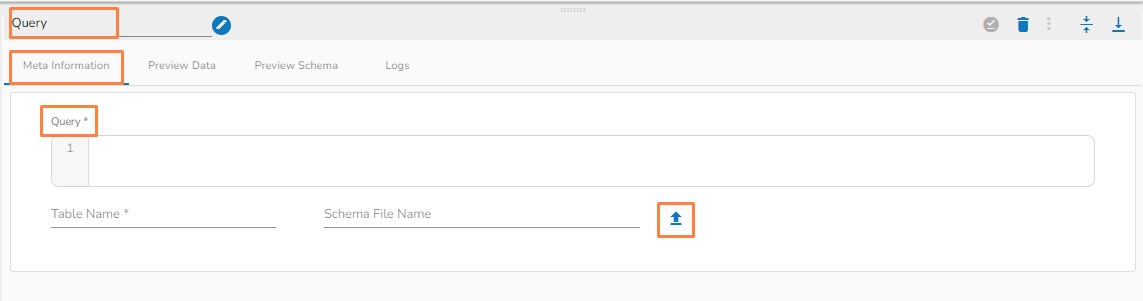
The Query transformation allows you to write SQL (DML) queries such as Select queries and data view queries.
Query(*): Provide a valid query to transform data.
Table Name(*): Provide the table name.
Schema File Name: Upload Spark Schema file in JSON format.
Choose File: Upload a file from the system.
Please Note: Alter query will not work.
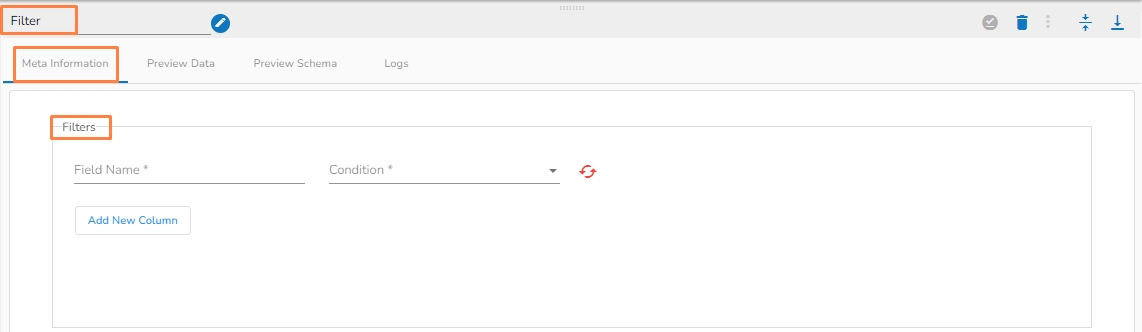
The Filter columns allow the user to filter table data based on different defined conditions.
Field Name(*): Provide field name.
Condition (*): 8 condition operations are available within this function.
Logical Condition(*)(AND/OR):
Add New Column: Adds a new Column.
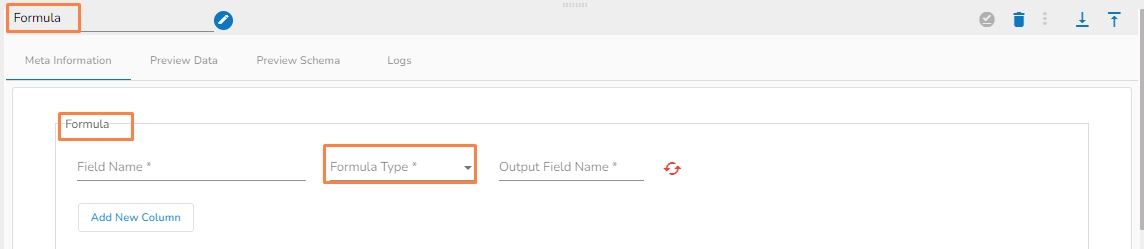
It gives computation results based on the selected formula type.
Field Name(*): Provide field name.
Formula Type(*): Select a Formula Type from the drop-down option.
Math (22 Math Operations)
String (16 String Operations )
Bitwise (3 Bitwise Operations)
Output Field Name(*): Provide the output field name.
Add New Column: Adds a new column.
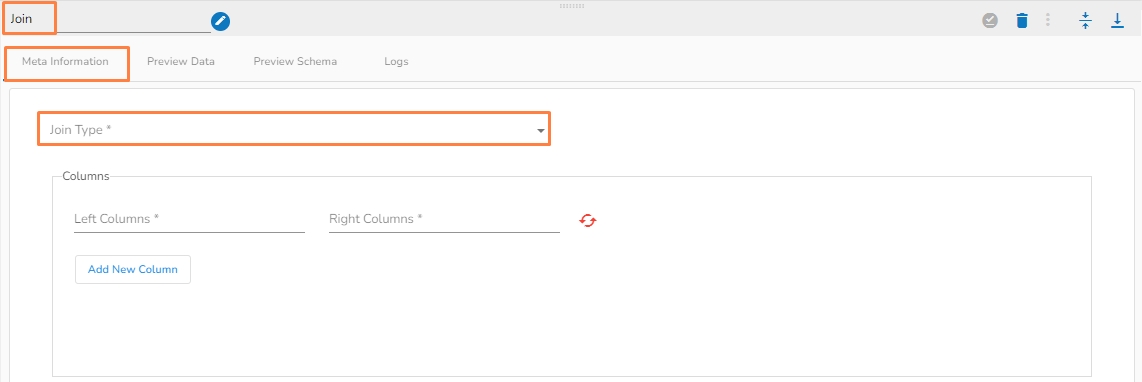
It joins 2 tables based on the specified column conditions.
Join Type (*): Provides drop-down menu to choose a Join type.
The supported Join Types are:
Inner
Outer
Full
Full outer
Left outer
Left
Right outer
Right
Left semi
Left anti
Left Column(*): Conditional column from the left table.
Right Column(*) : Conditional column from right table.
Add New Column: Adds a new column.
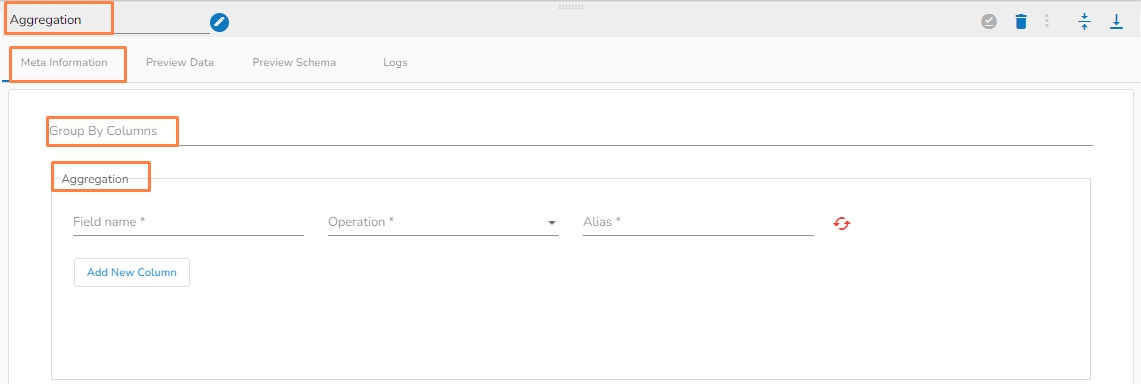
An aggregate task performs a calculation on a set of values and returns a single value by using the Group By column.
Group By Columns(*): Provide a name for the group by column.
Field Name(*): Provide the field name.
Operation (*): 30 operations are available within this function.
Alias(*): Provide an alias name.
Add New Column: Adds a new column.
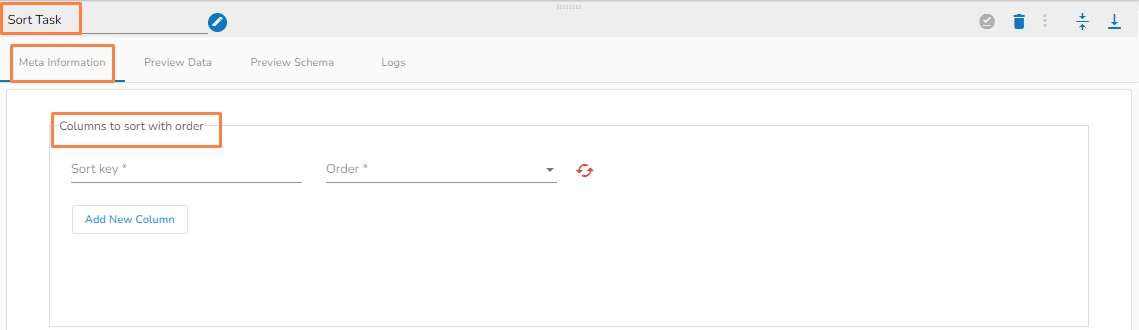
This transformation sorts all the data from a table based on the selected column and order.
Sort Key(*): Provide a sort key.
Order(*): Select an option out of Ascending or Descending.
Add New Column: Adds a new column.